
手把手教你阅读Flink 源码
本文大纲
一、Flink 官方文档这么全面,为什么还要读 Flink 源码
二、Flink 源码几百万行,该如何下手
通常对于阅读源码这件事情来说是有方法论可循的。
1、首先得具备前提条件
相关语言和基础技术知识。比如 Java,Maven,Git,设计模式等等。如果你只会 C++,哪天心血来潮去阅读 Flink 源码,那是不现实的;
开源项目的功能。需要知道这个项目是为了解决什么问题,完成什么功能,有哪些特性,如何启动,有哪些配置项。先把这个项目跑起来,能运行简单的 Demo;
相关的文档。也就是庞大的工程中,有哪些模块,每个模块大概的功能是干嘛的;
2、其次需要关注这些重点东西
接口抽象定义。任何项目代码都会有很多接口,接口的继承关系和方法,描述了它处理的数据结构,业务实体以及和其他模块的关系,理清楚这些关系是非常重要的。
模块粘合层。代码中很多的设计模式,都是为了解耦各个模块的,好处就是灵活扩展,坏处就是让本来平铺直述的代码割裂成一个个模块,不那么方便阅读。
业务流程。在代码一开始,不要进入细节,一方面会打消你的积极性,一方面也看不过来。要站在一定的高度,搞清楚整个的业务流程是怎样的,数据是怎么被传递的。最好可以画流程图或者时序图,方便理解和记忆。
具体实现。在具体实现中,仍然需要弄清楚一些重要的点
(1)代码逻辑。在代码中,有业务逻辑,是真正的业务处理逻辑;还有控制逻辑,像流程流转之类的;
(2)出错处理。其实很多地方都是在处理出错的逻辑,可以忽略掉这部分逻辑,排除干扰因素;
(3)数据处理。属性转换,JSON 解析,XML 解析,这些代码都比较冗长和无聊,可以忽略;
(4)重要的算法。这是比较核心的地方,也是最有技术含量的地方;
(5)底层交互。有一些代码是和底层操作系统或者是和 JVM 交互的,需要知道一些底层的东西;
运行时调试。这是最直接的方式,可以看到代码究竟是如何跑起来的,数据是怎么样的,是了解代码最重要的方式。
总结成一句话:高屋建瓴,提纲挈领,把握方向
三、安装 Git 环境
我就不具体演示了,说一下大致流程,可以自行百度,相关的文章很多的。
1、下载 Git
下载对应平台(Windows,Mac)的 Git 客户端,并安装
下载地址:https://git-scm.com/downloads
2、初始配置
$ git config --global user.name "Your Name"
$ git config --global user.email yourEmail@example.com
3、生成秘钥,并上传到 Gitee 上
ssh-keygen -t rsa
登陆 Gitee,在头像 - 设置 - 安全设置 - SSH 公钥 添加一个公钥
四、Github 龟速如何解决
GitHub 很慢如何下载好几十 M 的源码文件呢?
你想下载任意 GitHub 项目,都可以在 Gitee 上导入这个 Github 项目:

导入之后,就可以下载了。当然 Apache Flink 活跃度前几的项目,Gitee 肯定是会同步的了,直接搜索即可。
https://gitee.com/apache/flink?_from=gitee_search
然后打开 Git Bash,克隆这个项目
git@gitee.com:apache/flink.git
获取所有的分支
git fetch --tags
切换到 1.12.0 分支
git checkout release-1.12.0
这样最新发布的 1.12.0 版本源码就在本地了。
五、配置 Maven 阿里镜像
在导入 IDEA 之前,我们要配置 Maven 的镜像为阿里云的,这样下载 Jar 包比较快速。
在 Maven 安装目录的 conf 目录的 settings.xml 文件中,加入如下配置到 mirrors 标签中
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>
六、导入 IDEA
打开 IDEA,直接打开即可,等待它下载好所有的依赖
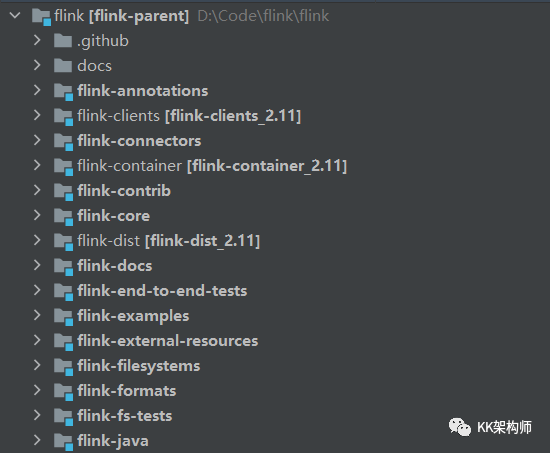
导入后,可以看到有很多模块,但是各个模块的功能见名知意,非常清晰,这里我就不挨个介绍了。直接开始 Debug Flink-Clients 模块。
七、开始调试 Flink-Clients
首先想强调一下,为什么要调试这个模块。因为这个模块是提交 Flink 作业的入口模块,代码流程相对比较清晰,调试完,就可以知道 Flink 作业是怎么提交的了。
1、我们该调试哪个对象
回忆下,大数据的 Hello,World 程序是什么,是不是 WordCount,Flink 发行版自带的例子中,就有 WordCount 程序。
下面的图,我是下载了官网的 Flink-1.12 发行版,放到我的虚拟机上了。

如何把它运行起来呢?
首先启动一个本机的 Flink 集群,把压缩包解压出来之后,什么都不要做,直接启动
cd /my2/flink/bin
./start-cluster.sh
提交 WordCount 程序到集群
./flink run ../examples/streaming/WordCount.jar
这样就直接把 WordCount 程序提交到集群上了,是怎么做到的呢?可以看看 flink 这个命令里面是什么
vi flink
移动到最后,可以发现
# Add HADOOP_CLASSPATH to allow the usage of Hadoop file systems
exec $JAVA_RUN $JVM_ARGS $FLINK_ENV_JAVA_OPTS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.client.cli.CliFrontend "$@"
原来它就是一个 java -classpath 类名,启动了一个 Java 虚拟机啊
这个类就是
org.apache.flink.client.cli.CliFrontend
这个类就是我们要运行的对象了
2、开始调试
可以看到 CliFrontend 里面有一个 main 方法,二话不说,直接 debug,报错了再说
果然,报错如下:

说在环境变量中,没有找到 FLINK_CONF_DIR 配置,也就是 flink 配置文件没有找到,就是那个 flink-conf.yml 文件
这个文件其实是在发行目录下:
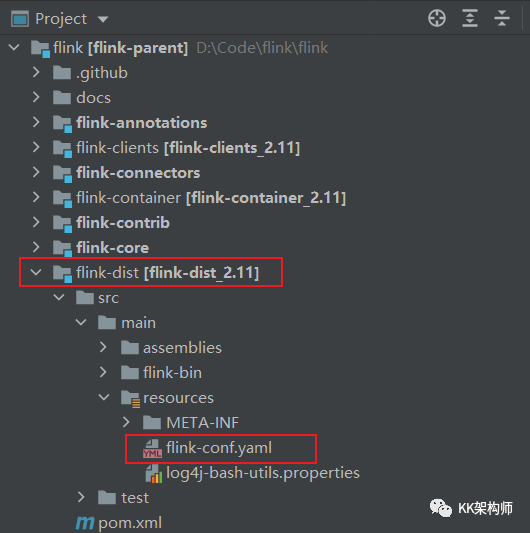
然后配置一个
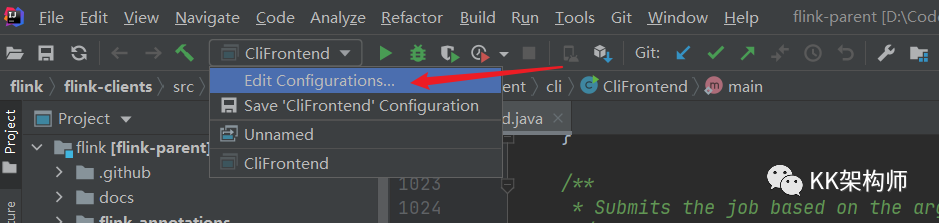
在这个地方加上这个配置

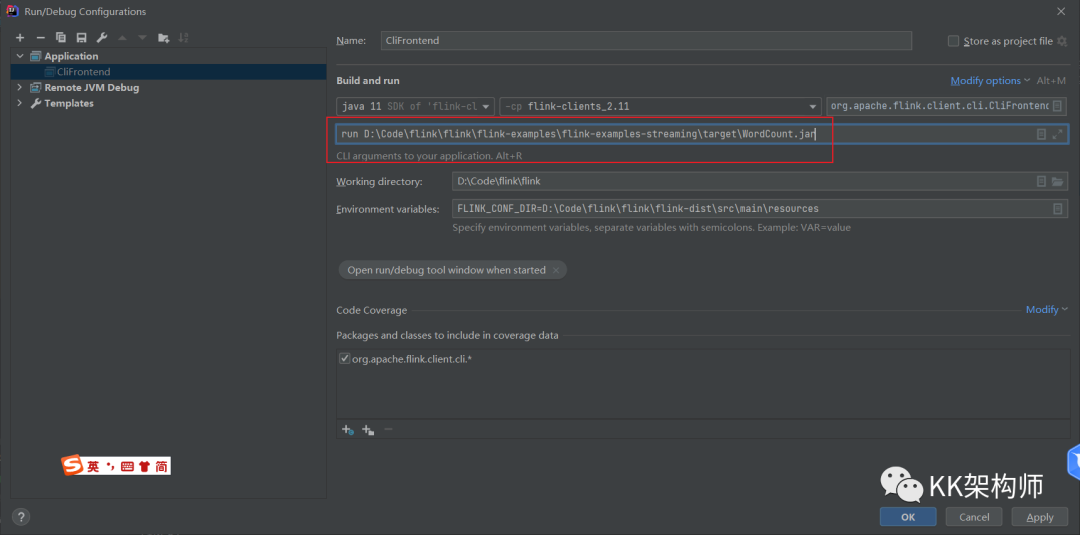
FLINK_CONF_DIR=D:\Code\flink\flink\flink-dist\src\main\resources
再运行一遍,报错如下

原来是因为,我们之前在运行命令的时候,后面还有一坨参数,现在什么参数都没有往 main 方法传,当然报错了。
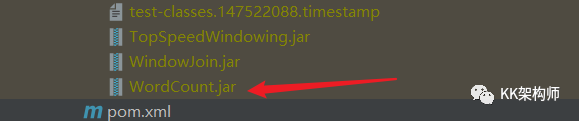
这里我们还需要一个 WordCount.jar 包,源码都有了,直接从源码打包一个出来,就是这么的任性了。
直接把 Flink : Examples : Streaming 模块打个包
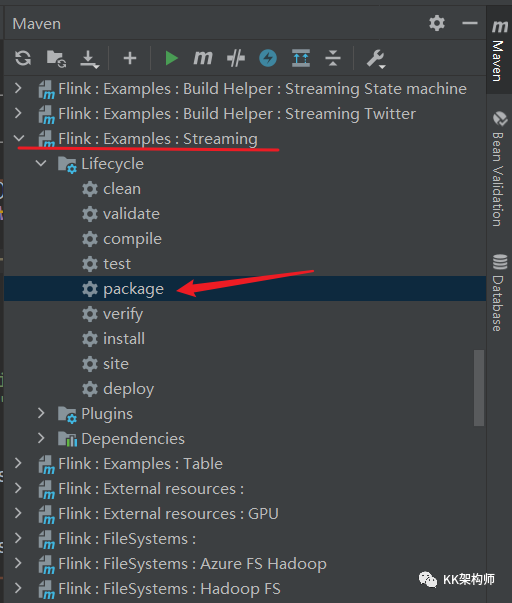
打完包之后,在 target 目录下,就会有一个 WordCount.jar 包了

填到这个地方
run D:\Code\flink\flink\flink-examples\flink-examples-streaming\target\WordCount.jar
然后再 Debug 看一下,发现它在这卡了很久,直到超时(WARNING 先不用管)

这个是正常的,因为它在最后生成 JobGraph 之后,是要通过 JobClient 客户端,提交到集群上的(还记得我们那个配置文件吗?里面可是配了集群的 JobManager 地址和端口的),而我们在 Windows 本地并没有启动集群。
不过没有关系,我们可以通过调试代码,看到 StreamGraph 是如何生成的,JobGraph 是如何生成的,最后是通过哪个类准备提交到集群的。这些提交前的动作,都可以通过源码看得到!
七、总结
今天通过完整的下载 Flink 代码,配置环境,初步调试了 Flink-Clients 代码,大致清楚,一个实时作业在提交前要经过这么多的转换逻辑。里面的实现细节我们在下一次再讲!大家一定要把环境装好了!
下次见!
--end--
原创专辑:
扫描下方二维码 添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群
更文不易,点个“在看”支持一下👇