
手把手教你学会RabbitMQ
每天早上七点三十,准时推送干货

前几天阿粉在看关于如何处理分布式事务的解决方案,于是就看到了关于使用最大努力通知来处理分布式事务的问题,而这其中最不可或缺的就是消息中间件了,那么什么是消息中间件呢?
为什么有消息中间件
前几天阿粉在看关于如何处理分布式事务的解决方案,于是就看到了关于使用最大努力通知来处理分布式事务的问题,而这其中最不可或缺的就是消息中间件了,那么什么是消息中间件呢?
1. 什么是消息中间件
在百度百科给出的解释是:消息中间件是基于队列与消息传递技术,在网络环境中为应用系统提供同步或异步、可靠的消息传输的支撑性软件系统。
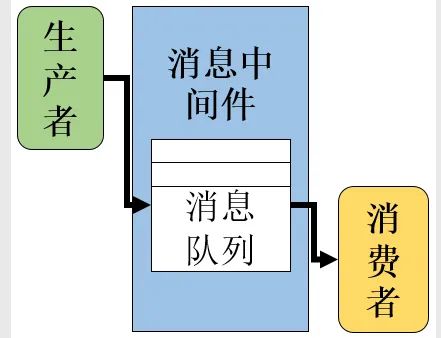
大家看上图,实际上就是生产者发给消息中间件一点东西,然后提供给消费者去消费,这样理解是不是就比百度百科要简单了很多了。
2. 消息中间件的种类
我们在这里先不讨论消息中间件的组成,下面会继续讲解,我们先看看都有哪些消息中间件,以及他们之间都有什么特点
1.ActiveMQ
ActiveMQ是Apache软件基金会所研发的开放源代码消息中间件;由于ActiveMQ是一个纯Java程序,因此只需要操作系统支持Java虚拟机,ActiveMQ便可执行。毕竟是Apache来维护的,功能还是非常强大的,
支持Java消息服务(JMS) 集群 (Clustering) 协议支持包括:OpenWire、REST、STOMP、WS-Notification、MQTT、XMPP以及AMQP。
但是ActiveMQ的缺点一样也是很明显的,版本更新很缓慢。集群模式需要依赖Zookeeper实现。虽然现在有了Apollo,号称下一代ActiveMQ,目前案例那是少的可怜。
2.RabbitMQ
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)
生态丰富,使用者众,有很多人在前面踩坑。AMQP协议的领导实现,支持多种场景
3.RocketMQ
RocketMQ是阿里开源的消息中间件,目前在Apache孵化,使用纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点,如果大家使用过Kafka的话,那么你就会发现RocketMQ其实和Kafka很相似,但是绝对不是单纯的摘出来了一块内容那么简单,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景,支撑了阿里多次双十一活动。
4.Kafka
Kafka是LinkedIn于2010年12月开发并开源的一个分布式流平台,现在是Apache的顶级项目,是一个高性能跨语言分布式Publish/Subscribe消息队列系统,以Pull的形式消费消息。Kafka自身服务与消息的生产和消费都依赖于Zookeeper,使用Scala语言开发。学习成本有时候会非常的大,不过阿粉也是相信大家对这个东西肯定很好奇,因为毕竟他是大数据生态系统中不可缺少的一环,以后阿粉会陆陆续续的去带着大家学习这块的内容。
说完了区分,那么我们就得开始正儿八经的学习RabbitMQ了,安装,使用,整合到项目中,一气呵成。
3. RabbitMQ的安装
关于安装的教程,阿粉就不再给大家一一的去说了,毕竟网上有的是教程,官网也有指定的教程,【https://www.rabbitmq.com/】 官网在这里,不过大家需要注意一件事情,RabbitMQ如果你想要安装Windows版本的话,那么你一定得先装一个环境,那就是erlang语言的环境,否则,你是装不到Windows上的。
安装完成之后,登录上他的后台,IP/port,
默认登录进去就是这个样子滴。
4.RabbitMQ的使用
上一阶段,我们已经完全的把RabbitMQ进行了安装,接下来我们就要看他的使用了,来,继续找官网的文档。
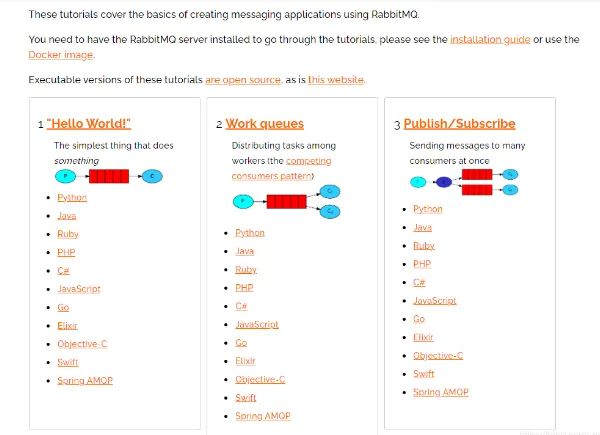
大家看到了这个Java案例了么?来打开了瞅瞅,先把生产者和消费者确定一下,生产者Producer,消费者Consumer,生产者提供消息,然后把消息发送到消息队列,消费者监听到消息之后,对消息进行消费。
我们也手把手写一个,
Producer
private final static String QUEUE_NAME = "Test_queue";
public static void main(String[] args) {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
try {
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "Hello World";
channel.basicPublish("", QUEUE_NAME, null, message.getBytes(StandardCharsets.UTF_8));
System.out.println(" 我生产了一条消息 " + message );
}catch (Exception e){
}
}
我生产了一条消息Hello World
这个时候,我们就能在后端的控制台上看到内容了,
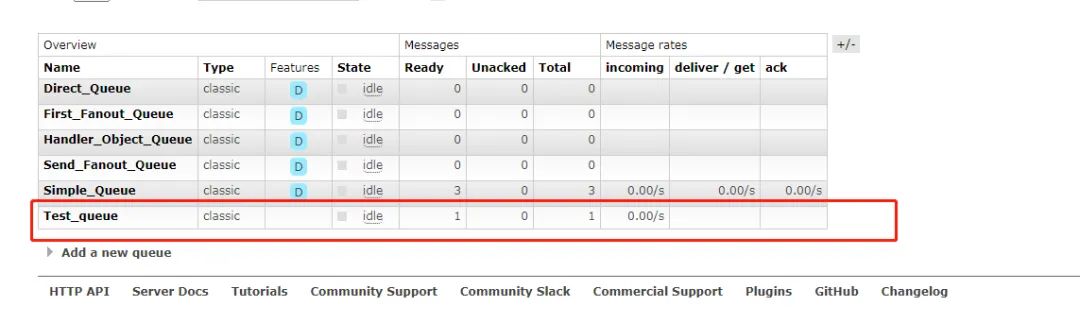
看到了我们的total,还有Ready,证明我们发送消息已经成功了,现在已经有一条叫做“Hello World”的消息在我们的消息队列里面了。
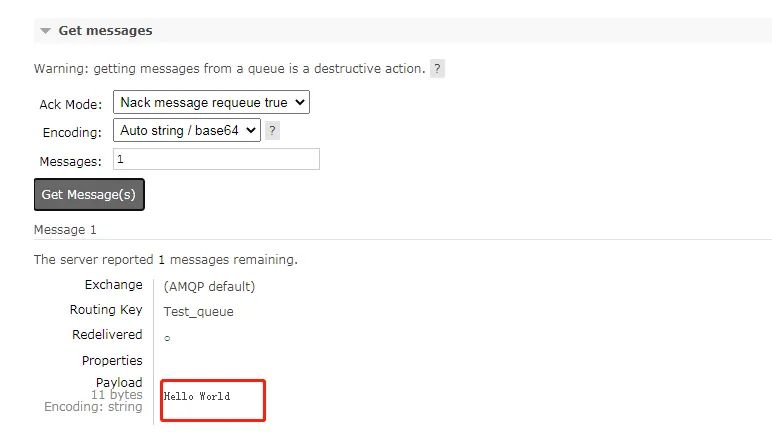
既然作为生产者的我们,消息已经发送了,这时候是不是就得开始写个消费者了?来,我们再写一个最最基础的消费者
Consumer
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
DeliverCallback deliverCallback = (consumerTag, deliver) -> {
String message = new String(deliver.getBody(), "UTF-8");
System.out.println(" 我是来消费消息的" + message );
};
channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {});
}
我是来消费消息的'Hello World'

大家看,这是不是就把你刚才生产的消息给消费掉了呢?
实际上Demo就是这么简单,但是不能这么简单的去写,今天阿粉先来讲讲这个RabbitMQ里面的一些内容,之后再继续给大家整合一下SpringBoot,SpringCloud这些内容。
5.RabbitMQ的一些重点基础
5.1 Channel(通道)
多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内的虚拟连接,复用TCP连接的通道。
5.2 Queue(消息队列)
在这里阿粉就要给大家开始划重点了,Queue是RabbitMQ 的内部对象,用于存储消息。RabbitMQ中消息都只能存储在队列中,队列的特性是先进先出。
我们刚才也看到了图片,发送的消息都是在Queue中存储的,可以理解成一个存储数据的结构,我们把“Hello World”发送到Queue中,然后提供给消费者消费。
至于生产者Producer和消费者Consumer,阿粉肯定也不用说了,一个是生产消息,一个消费消息。
5.3 Exchange: 交换器
Exchange交换机扮演着接收生产者生产的消息的角色。同时Exchange交换机还需要将接收到的消息传递给queue队列进行存储或消费,不同类型的exchange配合着routing_key就能按照exchange类型对应的路有规则将消息传递到指定的某个或者某些queue队列。
说到交换器,那肯定就想到了路由,而在这里也是有这个名字的,不过不是单纯的路由,而是RoutingKey。
RoutingKey: 相当于一个路由键,一般是用来指定路由规则的。而他经常搭配和Binding(绑定键)一起使用。
生产者将消息发送给交换器时,需要一个RoutingKey,当BindingKey和 RoutingKey相匹配时,消息会被路由到对应的队列中。
Exchange分类:
Direct
Fanout
Topic
Headers
对于Direct类型的交换器,在接收到生产者发送的消息时会将消息路由给与该exchange绑定的且与该消息的routing_key同名的queue队列。如果exchange上未绑定与routing_key同名的queue,消息将会被抛弃。
对于Fanout类型的交换器,将接收到的消息路由投递到所有与其绑定的queue队列上,此种类型exchange消息路由与routing_key无关。
对于Topic类型的交换器,采用模糊匹配的方式,可以通过通配符满足一部分规则,这就和Direct不一样了,Direct是完全匹配BindingKey和RoutingKey。
对于Headers类型的交换器,不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配.这时候我们需要在代码里面去设置Headers中的信息(键值对),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列 。
他们这些也是各有特点,大家记住了么?到这里文章就告一段落了,接下来的文章会深入讲解一下怎么去配置这些交换器类型,还有整合SpringBoot,大家快去赶紧动手安装并且写个测试吧。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】