
Flink 解析 | Flink 源码:广播流状态源码解析

Broadcast State 是 Operator State 的一种特殊类型。它的引入是为了支持这样的场景: 一个流的记录需要广播到所有下游任务,在这些用例中,它们用于在所有子任务中维护相同的状态。然后可以在处理第二个流的数据时访问这个广播状态,广播状态有自己的一些特性。
必须定义为一个 Map 结构。 广播状态只能在广播流侧修改,非广播侧不能修改状态。 Broadcast State 运行时的状态只能保存在内存中。
看到这相信你肯定会有下面的疑问:
广播状态为什么必须定义为 Map 结构,我用其他的状态类型不行吗? 广播状态为什么只能在广播侧修改,非广播侧为什么不能修改呢? 广播状态为什么只能保存在内存中,难道不能用 Rockdb 状态后端吗?
下面就带着这三个疑问通过阅读相关源码,回答上面的问题。
broadcast 源码
/**
* Sets the partitioning of the {@link DataStream} so that the output elements are broadcasted
* to every parallel instance of the next operation. In addition, it implicitly as many {@link
* org.apache.flink.api.common.state.BroadcastState broadcast states} as the specified
* descriptors which can be used to store the element of the stream.
*
* @param broadcastStateDescriptors the descriptors of the broadcast states to create.
* @return A {@link BroadcastStream} which can be used in the {@link #connect(BroadcastStream)}
* to create a {@link BroadcastConnectedStream} for further processing of the elements.
*/
@PublicEvolving
public BroadcastStream broadcast(
final MapStateDescriptor... broadcastStateDescriptors) {
Preconditions.checkNotNull(broadcastStateDescriptors);
final DataStream broadcastStream = setConnectionType(new BroadcastPartitioner<>());
return new BroadcastStream<>(environment, broadcastStream, broadcastStateDescriptors);
}
可以发现 broadcast 方法需要的参数是 MapStateDescriptor 也就是一个 Map 结构的状态描述符,我们在使用的时候就必须定义为 MapStateDescriptor,否则会直接报错,其实主要是因为广播状态的作用是和非广播流进行关联,你可以想象成双流 join 的场景,那么 join 的时候就必须要有一个主键,也就是相同的 key 才能 join 上,所以 Map(key-value) 结构是最适合这种场景的,key 可以存储要关联字段,value 可以是任意类型的广播数据,在关联的时候只需要获取到广播状态,然后 state.get(key) 就可以很容易拿到广播数据。
process 源码
@PublicEvolving
public SingleOutputStreamOperator process(
final KeyedBroadcastProcessFunction function) {
// 获取输出数据的类型信息
TypeInformation outTypeInfo =
TypeExtractor.getBinaryOperatorReturnType(
function,
KeyedBroadcastProcessFunction.class,
1,
2,
3,
TypeExtractor.NO_INDEX,
getType1(),
getType2(),
Utils.getCallLocationName(),
true);
return process(function, outTypeInfo);
}
process 方法需要的参数是 KeyedBroadcastProcessFunction
process 源码
@PublicEvolving
public SingleOutputStreamOperator process(
final KeyedBroadcastProcessFunction function,
final TypeInformation outTypeInfo) {
Preconditions.checkNotNull(function);
Preconditions.checkArgument(
nonBroadcastStream instanceof KeyedStream,
"A KeyedBroadcastProcessFunction can only be used on a keyed stream.");
return transform(function, outTypeInfo);
}
这个 process 方法里面什么都没干,直接调用 transform 方法。
transform 源码
@Internal
private SingleOutputStreamOperator transform(
final KeyedBroadcastProcessFunction userFunction,
final TypeInformation outTypeInfo) {
// read the output type of the input Transforms to coax out errors about MissingTypeInfo
nonBroadcastStream.getType();
broadcastStream.getType();
KeyedStream keyedInputStream = (KeyedStream) nonBroadcastStream;
// 构造 KeyedBroadcastStateTransformation
final KeyedBroadcastStateTransformation transformation =
new KeyedBroadcastStateTransformation<>(
"Co-Process-Broadcast-Keyed",
nonBroadcastStream.getTransformation(),
broadcastStream.getTransformation(),
clean(userFunction),
broadcastStateDescriptors,
keyedInputStream.getKeyType(),
keyedInputStream.getKeySelector(),
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({"unchecked", "rawtypes"})
final SingleOutputStreamOperator returnStream =
new SingleOutputStreamOperator(environment, transformation);
// 添加到 List> 集合
getExecutionEnvironment().addOperator(transformation);
return returnStream;
}
transform 方法里面主要做了两件事:
先是构造对应的 KeyedBroadcastStateTransformation 对象,其实 KeyedBroadcastStateTransformation 也是 Transformation 的一个子类。 然后把构造好的 transformation 添加到 List
getStreamGraph 源码
@Internal
public StreamGraph getStreamGraph(boolean clearTransformations) {
final StreamGraph streamGraph = getStreamGraphGenerator(transformations).generate();
if (clearTransformations) {
transformations.clear();
}
return streamGraph;
}
getStreamGraph 的主要作用就是生成 StreamGraph。下面就会用到上一步生成的 List
getStreamGraphGenerator 源码
private StreamGraphGenerator getStreamGraphGenerator(List> transformations) {
if (transformations.size() <= 0) {
throw new IllegalStateException(
"No operators defined in streaming topology. Cannot execute.");
}
// We copy the transformation so that newly added transformations cannot intervene with the
// stream graph generation.
return new StreamGraphGenerator(
new ArrayList<>(transformations), config, checkpointCfg, configuration)
.setStateBackend(defaultStateBackend)
.setChangelogStateBackendEnabled(changelogStateBackendEnabled)
.setSavepointDir(defaultSavepointDirectory)
.setChaining(isChainingEnabled)
.setUserArtifacts(cacheFile)
.setTimeCharacteristic(timeCharacteristic)
.setDefaultBufferTimeout(bufferTimeout)
.setSlotSharingGroupResource(slotSharingGroupResources);
}
getStreamGraphGenerator 方法主要就是构造 StreamGraphGenerator 对象,StreamGraphGenerator 构造完成后,就可以调用 generate 方法来产生 StreamGraph 了,在看 generate 方法之前先来看一下 StreamGraphGenerator 的静态代码块。
StreamGraphGenerator 源码
static {
@SuppressWarnings("rawtypes")
Map, TransformationTranslator>
tmp = new HashMap<>();
tmp.put(OneInputTransformation.class, new OneInputTransformationTranslator<>());
tmp.put(TwoInputTransformation.class, new TwoInputTransformationTranslator<>());
tmp.put(MultipleInputTransformation.class, new MultiInputTransformationTranslator<>());
tmp.put(KeyedMultipleInputTransformation.class, new MultiInputTransformationTranslator<>());
tmp.put(SourceTransformation.class, new SourceTransformationTranslator<>());
tmp.put(SinkTransformation.class, new SinkTransformationTranslator<>());
tmp.put(LegacySinkTransformation.class, new LegacySinkTransformationTranslator<>());
tmp.put(LegacySourceTransformation.class, new LegacySourceTransformationTranslator<>());
tmp.put(UnionTransformation.class, new UnionTransformationTranslator<>());
tmp.put(PartitionTransformation.class, new PartitionTransformationTranslator<>());
tmp.put(SideOutputTransformation.class, new SideOutputTransformationTranslator<>());
tmp.put(ReduceTransformation.class, new ReduceTransformationTranslator<>());
tmp.put(
TimestampsAndWatermarksTransformation.class,
new TimestampsAndWatermarksTransformationTranslator<>());
tmp.put(BroadcastStateTransformation.class, new BroadcastStateTransformationTranslator<>());
tmp.put(
KeyedBroadcastStateTransformation.class,
new KeyedBroadcastStateTransformationTranslator<>());
translatorMap = Collections.unmodifiableMap(tmp);
}
在初始化 StreamGraphGenerator 之前,会先执行其静态代码块生成一个 Transformation -> TransformationTranslator 映射关系的 Map 集合,后面会用到这个 Map。
transform 源码
// 根据 Transformation 获取对应的 TransformationTranslator
final TransformationTranslator> translator =
(TransformationTranslator>)
translatorMap.get(transform.getClass());
Collection transformedIds;
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}
构造完 StreamGraphGenerator 对象后,紧接着会调用 generate 方法,然后又调用了 transform 方法,这里会从上面生成的 Map 里面获取到对应的 TransformationTranslator,然后调用 translate 方法。
translate#translateForStreaming#translateForStreamingInternal 源码
@Override
protected Collection translateForStreamingInternal(
final KeyedBroadcastStateTransformation transformation,
final Context context) {
checkNotNull(transformation);
checkNotNull(context);
// 构建 CoBroadcastWithKeyedOperator
CoBroadcastWithKeyedOperator operator =
new CoBroadcastWithKeyedOperator<>(
transformation.getUserFunction(),
transformation.getBroadcastStateDescriptors());
return translateInternal(
transformation,
transformation.getRegularInput(),
transformation.getBroadcastInput(),
SimpleOperatorFactory.of(operator),
transformation.getStateKeyType(),
transformation.getKeySelector(),
null /* no key selector on broadcast input */,
context);
}
translate 方法最终会调用到 KeyedBroadcastStateTransformationTranslator 的 translateForStreamingInternal 方法中,根据 UserFunction(用户代码)和 broadcastStateDescriptors(广播状态描述符)构造CoBroadcastWithKeyedOperator 对象。
CoBroadcastWithKeyedOperator 源码
/**
* A {@link TwoInputStreamOperator} for executing {@link KeyedBroadcastProcessFunction
* KeyedBroadcastProcessFunctions}.
*
* @param The key type of the input keyed stream.
* @param The input type of the keyed (non-broadcast) side.
* @param The input type of the broadcast side.
* @param The output type of the operator.
*/
@Internal
public class CoBroadcastWithKeyedOperator<KS, IN1, IN2, OUT>
extends AbstractUdfStreamOperator<OUT, KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT>>
implements TwoInputStreamOperator<IN1, IN2, OUT>, Triggerable<KS, VoidNamespace> {
private static final long serialVersionUID = 5926499536290284870L;
private final List> broadcastStateDescriptors;
private transient TimestampedCollector collector;
private transient Map, BroadcastState> broadcastStates;
private transient ReadWriteContextImpl rwContext;
private transient ReadOnlyContextImpl rContext;
private transient OnTimerContextImpl onTimerContext;
public CoBroadcastWithKeyedOperator(
final KeyedBroadcastProcessFunction function,
final List> broadcastStateDescriptors) {
super(function);
this.broadcastStateDescriptors = Preconditions.checkNotNull(broadcastStateDescriptors);
}
@Override
public void open() throws Exception {
super.open();
InternalTimerService internalTimerService =
getInternalTimerService("user-timers", VoidNamespaceSerializer.INSTANCE, this);
TimerService timerService = new SimpleTimerService(internalTimerService);
collector = new TimestampedCollector<>(output);
this.broadcastStates = new HashMap<>(broadcastStateDescriptors.size());
for (MapStateDescriptor descriptor : broadcastStateDescriptors) {
broadcastStates.put(
descriptor,
// 初始化状态实现实例
getOperatorStateBackend().getBroadcastState(descriptor));
}
rwContext =
new ReadWriteContextImpl(
getExecutionConfig(),
getKeyedStateBackend(),
userFunction,
broadcastStates,
timerService);
rContext =
new ReadOnlyContextImpl(
getExecutionConfig(), userFunction, broadcastStates, timerService);
onTimerContext =
new OnTimerContextImpl(
getExecutionConfig(), userFunction, broadcastStates, timerService);
}
@Override
public void processElement1(StreamRecord element) throws Exception {
collector.setTimestamp(element);
rContext.setElement(element);
userFunction.processElement(element.getValue(), rContext, collector);
rContext.setElement(null);
}
@Override
public void processElement2(StreamRecord element) throws Exception {
collector.setTimestamp(element);
rwContext.setElement(element);
userFunction.processBroadcastElement(element.getValue(), rwContext, collector);
rwContext.setElement(null);
}
private class ReadWriteContextImpl
extends KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT>.Context {
private final ExecutionConfig config;
private final KeyedStateBackend keyedStateBackend;
private final Map, BroadcastState> states;
private final TimerService timerService;
private StreamRecord element;
ReadWriteContextImpl(
final ExecutionConfig executionConfig,
final KeyedStateBackend keyedStateBackend,
final KeyedBroadcastProcessFunction function,
final Map, BroadcastState> broadcastStates,
final TimerService timerService) {
function.super();
this.config = Preconditions.checkNotNull(executionConfig);
this.keyedStateBackend = Preconditions.checkNotNull(keyedStateBackend);
this.states = Preconditions.checkNotNull(broadcastStates);
this.timerService = Preconditions.checkNotNull(timerService);
}
void setElement(StreamRecord e) {
this.element = e;
}
@Override
public Long timestamp() {
checkState(element != null);
return element.getTimestamp();
}
@Override
public BroadcastState getBroadcastState(
MapStateDescriptor stateDescriptor) {
Preconditions.checkNotNull(stateDescriptor);
stateDescriptor.initializeSerializerUnlessSet(config);
BroadcastState state = (BroadcastState) states.get(stateDescriptor);
if (state == null) {
throw new IllegalArgumentException(
"The requested state does not exist. "
+ "Check for typos in your state descriptor, or specify the state descriptor "
+ "in the datastream.broadcast(...) call if you forgot to register it.");
}
return state;
}
@Override
public void output(OutputTag outputTag, X value) {
checkArgument(outputTag != null, "OutputTag must not be null.");
output.collect(outputTag, new StreamRecord<>(value, element.getTimestamp()));
}
@Override
public long currentProcessingTime() {
return timerService.currentProcessingTime();
}
@Override
public long currentWatermark() {
return timerService.currentWatermark();
}
@Override
public void applyToKeyedState(
final StateDescriptor stateDescriptor,
final KeyedStateFunction function)
throws Exception {
keyedStateBackend.applyToAllKeys(
VoidNamespace.INSTANCE,
VoidNamespaceSerializer.INSTANCE,
Preconditions.checkNotNull(stateDescriptor),
Preconditions.checkNotNull(function));
}
}
private class ReadOnlyContextImpl extends ReadOnlyContext {
private final ExecutionConfig config;
private final Map, BroadcastState> states;
private final TimerService timerService;
private StreamRecord element;
ReadOnlyContextImpl(
final ExecutionConfig executionConfig,
final KeyedBroadcastProcessFunction function,
final Map, BroadcastState> broadcastStates,
final TimerService timerService) {
function.super();
this.config = Preconditions.checkNotNull(executionConfig);
this.states = Preconditions.checkNotNull(broadcastStates);
this.timerService = Preconditions.checkNotNull(timerService);
}
void setElement(StreamRecord e) {
this.element = e;
}
@Override
public Long timestamp() {
checkState(element != null);
return element.hasTimestamp() ? element.getTimestamp() : null;
}
@Override
public TimerService timerService() {
return timerService;
}
@Override
public long currentProcessingTime() {
return timerService.currentProcessingTime();
}
@Override
public long currentWatermark() {
return timerService.currentWatermark();
}
@Override
public void output(OutputTag outputTag, X value) {
checkArgument(outputTag != null, "OutputTag must not be null.");
output.collect(outputTag, new StreamRecord<>(value, element.getTimestamp()));
}
@Override
public ReadOnlyBroadcastState getBroadcastState(
MapStateDescriptor stateDescriptor) {
Preconditions.checkNotNull(stateDescriptor);
stateDescriptor.initializeSerializerUnlessSet(config);
ReadOnlyBroadcastState state =
(ReadOnlyBroadcastState) states.get(stateDescriptor);
if (state == null) {
throw new IllegalArgumentException(
"The requested state does not exist. "
+ "Check for typos in your state descriptor, or specify the state descriptor "
+ "in the datastream.broadcast(...) call if you forgot to register it.");
}
return state;
}
@Override
@SuppressWarnings("unchecked")
public KS getCurrentKey() {
return (KS) CoBroadcastWithKeyedOperator.this.getCurrentKey();
}
}
private class OnTimerContextImpl
extends KeyedBroadcastProcessFunction<KS, IN1, IN2, OUT>.OnTimerContext {
private final ExecutionConfig config;
private final Map, BroadcastState> states;
private final TimerService timerService;
private TimeDomain timeDomain;
private InternalTimer timer;
OnTimerContextImpl(
final ExecutionConfig executionConfig,
final KeyedBroadcastProcessFunction function,
final Map, BroadcastState> broadcastStates,
final TimerService timerService) {
function.super();
this.config = Preconditions.checkNotNull(executionConfig);
this.states = Preconditions.checkNotNull(broadcastStates);
this.timerService = Preconditions.checkNotNull(timerService);
}
@Override
public Long timestamp() {
checkState(timer != null);
return timer.getTimestamp();
}
@Override
public TimeDomain timeDomain() {
checkState(timeDomain != null);
return timeDomain;
}
@Override
public KS getCurrentKey() {
return timer.getKey();
}
@Override
public TimerService timerService() {
return timerService;
}
@Override
public long currentProcessingTime() {
return timerService.currentProcessingTime();
}
@Override
public long currentWatermark() {
return timerService.currentWatermark();
}
@Override
public void output(OutputTag outputTag, X value) {
checkArgument(outputTag != null, "OutputTag must not be null.");
output.collect(outputTag, new StreamRecord<>(value, timer.getTimestamp()));
}
@Override
public ReadOnlyBroadcastState getBroadcastState(
MapStateDescriptor stateDescriptor) {
Preconditions.checkNotNull(stateDescriptor);
stateDescriptor.initializeSerializerUnlessSet(config);
ReadOnlyBroadcastState state =
(ReadOnlyBroadcastState) states.get(stateDescriptor);
if (state == null) {
throw new IllegalArgumentException(
"The requested state does not exist. "
+ "Check for typos in your state descriptor, or specify the state descriptor "
+ "in the datastream.broadcast(...) call if you forgot to register it.");
}
return state;
}
}
}
在分析 CoBroadcastWithKeyedOperator 源码之前,先来看一下 CoBroadcastWithKeyedOperator 的 UML 图。
CoBroadcastWithKeyedOperator UML 图
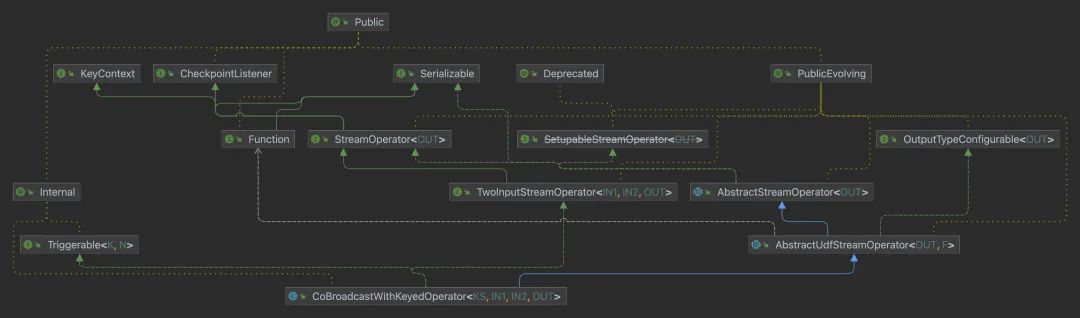
可以看到 CoBroadcastWithKeyedOperator 实现了 TwoInputStreamOperator 这个接口,从命名上就能知道,这是一个具有两个输入流的 StreamOperator 接口,因为 CoBroadcastWithKeyedOperator 的上游连接的是两个数据流,所以就实现了这个接口,下面再来看一下 TwoInputStreamOperator 的源码。
TwoInputStreamOperator 源码
/**
* Interface for stream operators with two inputs. Use {@link
* org.apache.flink.streaming.api.operators.AbstractStreamOperator} as a base class if you want to
* implement a custom operator.
*
* @param The input type of the operator
* @param The input type of the operator
* @param The output type of the operator
*/
@PublicEvolving
public interface TwoInputStreamOperator<IN1, IN2, OUT> extends StreamOperator<OUT> {
/**
* Processes one element that arrived on the first input of this two-input operator. This method
* is guaranteed to not be called concurrently with other methods of the operator.
*/
void processElement1(StreamRecord element) throws Exception;
/**
* Processes one element that arrived on the second input of this two-input operator. This
* method is guaranteed to not be called concurrently with other methods of the operator.
*/
void processElement2(StreamRecord element) throws Exception;
}
TwoInputStreamOperator 接口里面定义了两个方法,其中 processElement1 是用来处理非广播流的数据,processElement2 是用来处理广播流的数据。
接着回到 CoBroadcastWithKeyedOperator 的 open 方法,首先会初始化 broadcastStates,用来保存 MapStateDescriptor -> BroadcastState 的映射关系,然后初始化 ReadWriteContextImpl 和 ReadOnlyContextImpl 对象,顾名思义 ReadWriteContextImpl 是既可以读也可以写状态,ReadOnlyContextImpl 是只能读状态,不能写状态,在 open 方法里面还有一个重要的事情,就是初始化广播状态的实现类。
getBroadcastState 源码
public BroadcastState getBroadcastState(
final MapStateDescriptor stateDescriptor) throws StateMigrationException {
Preconditions.checkNotNull(stateDescriptor);
String name = Preconditions.checkNotNull(stateDescriptor.getName());
BackendWritableBroadcastState previous =
(BackendWritableBroadcastState) accessedBroadcastStatesByName.get(name);
if (previous != null) {
checkStateNameAndMode(
previous.getStateMetaInfo().getName(),
name,
previous.getStateMetaInfo().getAssignmentMode(),
OperatorStateHandle.Mode.BROADCAST);
return previous;
}
stateDescriptor.initializeSerializerUnlessSet(getExecutionConfig());
TypeSerializer broadcastStateKeySerializer =
Preconditions.checkNotNull(stateDescriptor.getKeySerializer());
TypeSerializer broadcastStateValueSerializer =
Preconditions.checkNotNull(stateDescriptor.getValueSerializer());
BackendWritableBroadcastState broadcastState =
(BackendWritableBroadcastState) registeredBroadcastStates.get(name);
if (broadcastState == null) {
broadcastState =
new HeapBroadcastState<>(
new RegisteredBroadcastStateBackendMetaInfo<>(
name,
OperatorStateHandle.Mode.BROADCAST,
broadcastStateKeySerializer,
broadcastStateValueSerializer));
registeredBroadcastStates.put(name, broadcastState);
} else {
// has restored state; check compatibility of new state access
checkStateNameAndMode(
broadcastState.getStateMetaInfo().getName(),
name,
broadcastState.getStateMetaInfo().getAssignmentMode(),
OperatorStateHandle.Mode.BROADCAST);
RegisteredBroadcastStateBackendMetaInfo restoredBroadcastStateMetaInfo =
broadcastState.getStateMetaInfo();
// check whether new serializers are incompatible
TypeSerializerSchemaCompatibility keyCompatibility =
restoredBroadcastStateMetaInfo.updateKeySerializer(broadcastStateKeySerializer);
if (keyCompatibility.isIncompatible()) {
throw new StateMigrationException(
"The new key typeSerializer for broadcast state must not be incompatible.");
}
TypeSerializerSchemaCompatibility valueCompatibility =
restoredBroadcastStateMetaInfo.updateValueSerializer(
broadcastStateValueSerializer);
if (valueCompatibility.isIncompatible()) {
throw new StateMigrationException(
"The new value typeSerializer for broadcast state must not be incompatible.");
}
broadcastState.setStateMetaInfo(restoredBroadcastStateMetaInfo);
}
accessedBroadcastStatesByName.put(name, broadcastState);
return broadcastState;
}
getBroadcastState 方法主要就是初始化 HeapBroadcastState 对象,也就是广播状态的具体实现类,再来看一下 HeapBroadcastState 源码。
HeapBroadcastState 源码
/**
* A {@link BroadcastState Broadcast State} backed a heap-based {@link Map}.
*
* @param The key type of the elements in the {@link BroadcastState Broadcast State}.
* @param The value type of the elements in the {@link BroadcastState Broadcast State}.
*/
public class HeapBroadcastState<K, V> implements BackendWritableBroadcastState<K, V> {
/** Meta information of the state, including state name, assignment mode, and serializer. */
private RegisteredBroadcastStateBackendMetaInfo stateMetaInfo;
/** The internal map the holds the elements of the state. */
private final Map backingMap;
/** A serializer that allows to perform deep copies of internal map state. */
private final MapSerializer internalMapCopySerializer;
HeapBroadcastState(RegisteredBroadcastStateBackendMetaInfo stateMetaInfo) {
this(stateMetaInfo, new HashMap<>());
}
private HeapBroadcastState(
final RegisteredBroadcastStateBackendMetaInfo stateMetaInfo,
final Map internalMap) {
this.stateMetaInfo = Preconditions.checkNotNull(stateMetaInfo);
this.backingMap = Preconditions.checkNotNull(internalMap);
this.internalMapCopySerializer =
new MapSerializer<>(
stateMetaInfo.getKeySerializer(), stateMetaInfo.getValueSerializer());
}
private HeapBroadcastState(HeapBroadcastState toCopy) {
this(
toCopy.stateMetaInfo.deepCopy(),
toCopy.internalMapCopySerializer.copy(toCopy.backingMap));
}
@Override
public void setStateMetaInfo(RegisteredBroadcastStateBackendMetaInfo stateMetaInfo) {
this.stateMetaInfo = stateMetaInfo;
}
@Override
public RegisteredBroadcastStateBackendMetaInfo getStateMetaInfo() {
return stateMetaInfo;
}
@Override
public HeapBroadcastState deepCopy() {
return new HeapBroadcastState<>(this);
}
@Override
public void clear() {
backingMap.clear();
}
@Override
public String toString() {
return "HeapBroadcastState{"
+ "stateMetaInfo="
+ stateMetaInfo
+ ", backingMap="
+ backingMap
+ ", internalMapCopySerializer="
+ internalMapCopySerializer
+ '}';
}
@Override
public long write(FSDataOutputStream out) throws IOException {
long partitionOffset = out.getPos();
DataOutputView dov = new DataOutputViewStreamWrapper(out);
dov.writeInt(backingMap.size());
for (Map.Entry entry : backingMap.entrySet()) {
getStateMetaInfo().getKeySerializer().serialize(entry.getKey(), dov);
getStateMetaInfo().getValueSerializer().serialize(entry.getValue(), dov);
}
return partitionOffset;
}
@Override
public V get(K key) {
return backingMap.get(key);
}
@Override
public void put(K key, V value) {
backingMap.put(key, value);
}
@Override
public void putAll(Map map) {
backingMap.putAll(map);
}
@Override
public void remove(K key) {
backingMap.remove(key);
}
@Override
public boolean contains(K key) {
return backingMap.containsKey(key);
}
@Override
public Iterator> iterator() {
return backingMap.entrySet().iterator();
}
@Override
public Iterable> entries() {
return backingMap.entrySet();
}
@Override
public Iterable> immutableEntries() {
return Collections.unmodifiableSet(backingMap.entrySet());
}
}
HeapBroadcastState 的代码比较简单,主要是对状态的读写操作,本质就是在操作 HashMap。
接着回到 CoBroadcastWithKeyedOperator 的 processElement1 方法里用的是 ReadOnlyContextImpl,processElement2 方法里用的是 ReadWriteContextImpl,换句话说,只有在广播侧才可以修改状态,在非广播侧不能修改状态,这里对应了上面的第二个问题。
虽然在广播侧和非广侧都可以获取到状态,但是 getBroadcastState 方法的返回值是不一样的。
BroadcastState & ReadOnlyBroadcastState UML 图
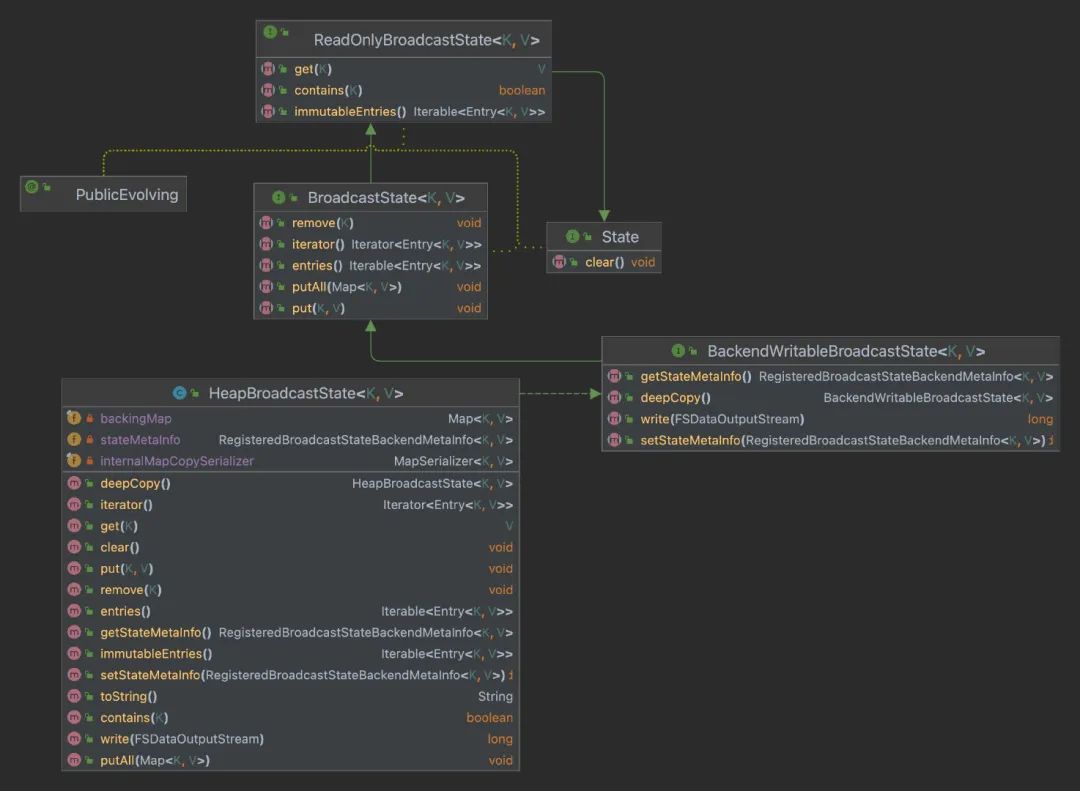
BroadcastState 接口继承了 ReadOnlyBroadcastState 接口又继承了 State 接口,BroadcastState 接口的唯一实现类是 HeapBroadcastState,从名字上就能看出广播状态是存储在 JVM 堆内存上的。底层就是一个 Map,上图中的 backingMap 就是用来保存状态数据的,这里对应了上面的第三个问题。
为了进一步解释上面的第二个问题,下面补充一个具体的场景来说明。
举例说明
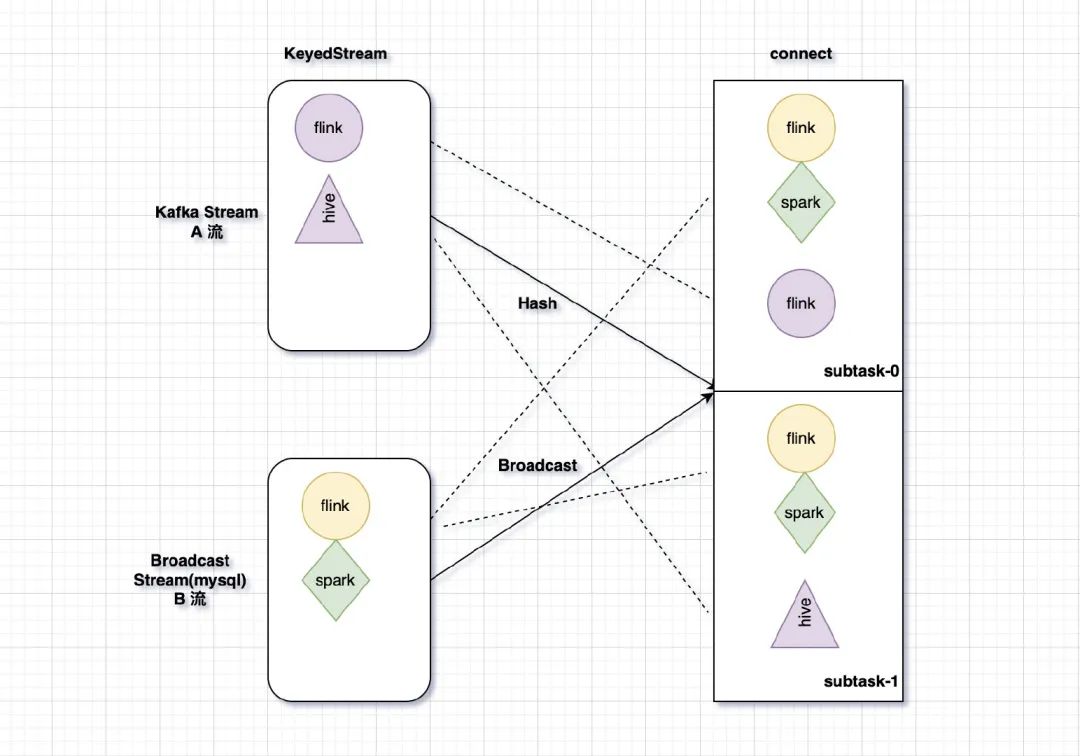
我们来看上图中的场景,A 流读取 Kafka 的数据然后经过 keyby 返回一个 KeyedStream,B 流读取 mysql 的数据用于广播流返回一个 BroadcastStream,B 流有两条数据分别是 flink,spark,然后会广播到下游的每一个 subtask 上去,此时下游的 subtask-0,subtask-1 就拥有了广播状态中的 flink,spark 两条数据,这个时候往 Kafka 里写入两条数据分别是 flink 和 hive,经过 keyby 操作,flink 被分配到了下游的 subtask-0 上,hive 被分配到了 subtask-1 上,很明显 flink 这条数据可以和广播流数据关联上,hive 这条数据则关联不上,此时,如果在非广播侧也就是 A 流侧修改了状态,比如把 flink, hive 添加到了状态里面,此时 subtask-0 和 subtask-1 上的广播状态数据就会出现不一致的情况,所以,为了保证 operator 的所有并发实例持有的广播状态的一致性,在设计的时候就禁止在非广播侧修改状态。
总结
Broadcast State 是 Operator State 的一种特殊类型。主要是用来解决低吞吐量的流(小数据量)和另一个原始数据流关联的场景,广播状态必须定义为 Map 结构,并且只能在广播流侧修改状态,非广播流侧只能获取状态,不能修改状态。广播状态只能保存在堆内存中,所以在使用广播状态的时候需要给 TM 设置足够的内存,本文主要从源码的角度解释了 Flink 这么设计的原因,让大家对广播流状态有了更加深入的理解。
推荐阅读
Flink 1.14.0 全新的 Kafka Connector
Flink 1.14.0 消费 kafka 数据自定义反序列化类
Flink 通过 State Processor API 实现状态的读取和写入
如果你觉得文章对你有帮助,麻烦点一下 赞 和 在看 吧,你的支持是我创作的最大动力.