
一文读懂 RoIPooling、RoIAlign 和 RoIWarp
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

导读
本文详细讲解了 RoIPooling 、RoIAlign 和 RoIWarp ,用非常的图来帮助理解,相信通过本文阅读能让你对这三者有更加深刻的理解
如果对你有所帮助请点个在看、点或分享,鼓励一下小编
理解Region of Interest — (RoI Pooling)
快速而简单地解释什么是RoI Pooling 以及它是如何工作的?为什么我们在Fast R-CNNs中使用它?
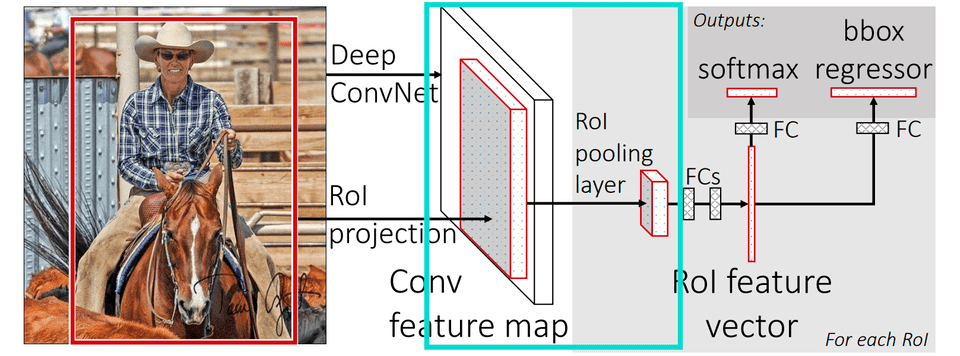
Fast R-CNNs 架构。来源https://arxiv.org/pdf/1504.08083.pdf
我们将讨论在Fast R-CNN文件中描述的原始RoI池化(上图中的浅蓝色矩形)。这个过程还有第二种和第三种版本分别叫做 RoIAlign 和 RoIWarp 。
什么是RoI?
RoI(Region of Interest) 是从原始图像中提取的区域。我们不打算讲解如何提取这些区域,因为有很多方法可以做到。我们现在唯一应该知道的是,有多个类似的区域,最后都应该接受测试。
Fast R-CNN 的原理
特征提取
Fast R-CNN 不同于基本的 R-CNN 网络。它只有一个卷积特征提取(在我们的示例中,我们将使用VGG16)。
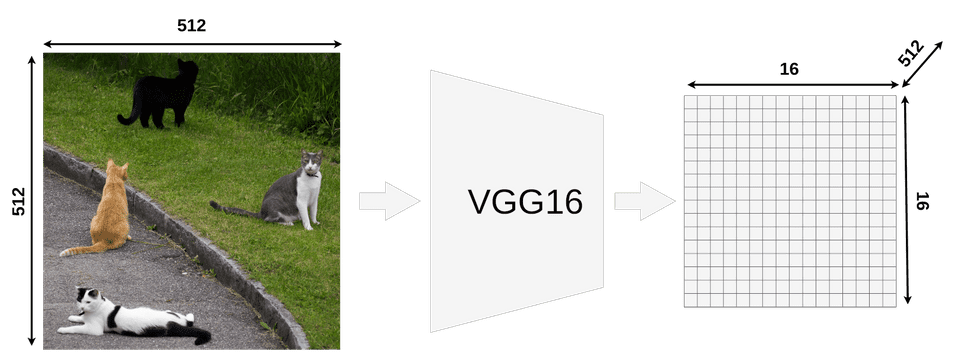
VGG16 特征提取输出尺寸
我们的模型取一个尺寸为 512x512x3 (宽度x高度x RGB) 的图像输入,VGG16将其映射为一个 16x16x512 的feature map。你可以使用不同的输入大小(通常较小,Keras中VGG16的默认输入大小为224x224)。
如果你看输出矩阵,你应该注意到它的 宽度和高度 正好比输入图像小32倍(512/32 = 16)。这很重要,因为所有 RoIs 都要按这个因子减小。
Sample RoIs
这里只画出了 4 个不同的 RoI 。在实际的Fast R-CNN你可能有成千上万个,但打印所有使图像难于观察。

Regions of Interest, 图片来源:https://www.flickr.com/photos/bunny/
重要!需要记住的是 RoI 不是一个边界框。它可能看起来像一个,但它只是一个进一步处理的proposal。很多人都这么认为,因为大多数论文和博客文章都是在提出proposals,而不是实际的对象。这样更方便,上面的图像上也这样做了。这里有一个不同的 proposal area ,也将被Fast R-CNN(绿框)选中。

Region of Interest which doesn’t make sense
有一些方法可以限制 RoI 的数量,也许我将来会写一些关于它的东西。
如何从feature map 上获取 RoI ?
现在,当我们知道RoI是什么时,我们必须能够将它们映射到VGG16的输出 feature map上。

将RoI映射到VGG16的输出
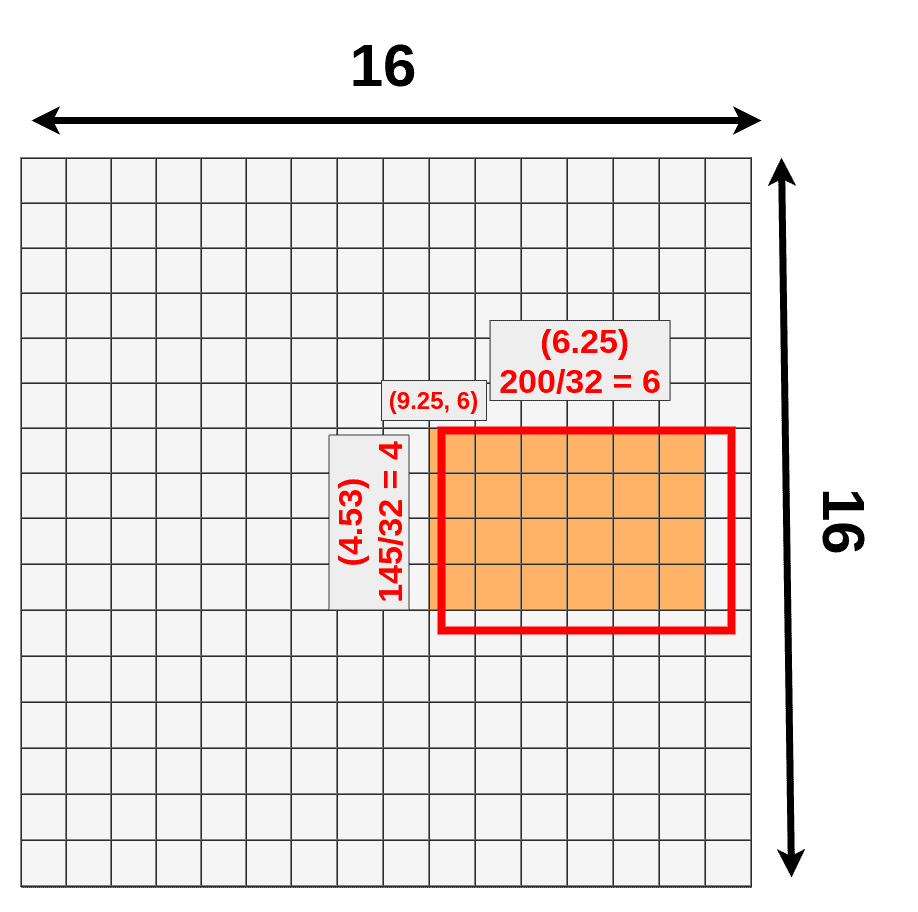
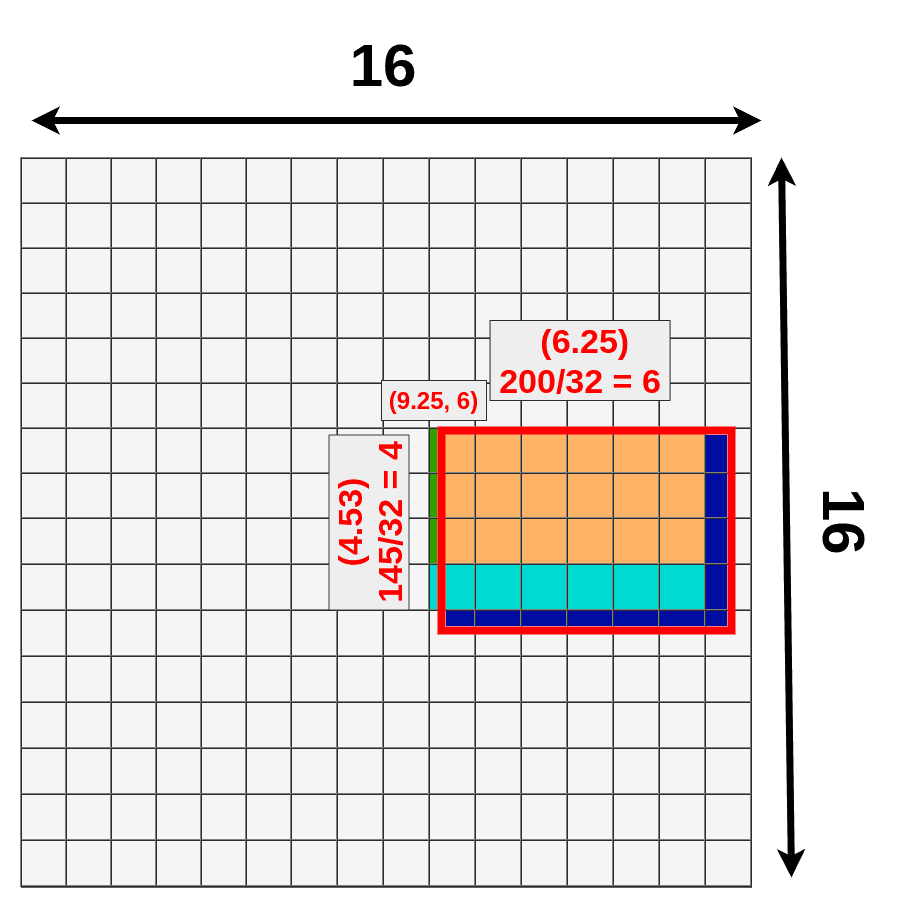
每个RoI都有它的原始坐标和大小。从现在开始,我们将只关注其中之一:

我们的RoI 对象
其原始大小为 145x200 ,左上角设置为 (192x296) 。正如你可能知道的,我们无法将这些数字的大部分整除以 32(比例因子)。
- width: 200/32 = 6.25
- height: 145/32 = ~4.53
- x: 296/32 = 9.25
- y: 192/32 = 6
只有最后一个数字(左上角的Y坐标)是有意义的。这是因为我们现在使用的是16x16 网格,我们关心的数字只有整数(更精确地说:自然数)。
feature map上坐标的量化
量化是将输入从一大组值(如实数)约束为一组离散的值(如整数)的过程。
如果我们feature map 上原始的 RoI 如下所示:

feature map 上的 原始 RoI
我们不能真正地在它上面应用池化层,因为一些“cells”被分割了。量化所做的就是每一个结果在放到矩阵上之前都进行约减。9.25变成9, 4.53变成4,等等。
量化后的RoI
你可以注意到我们刚刚丢失了一堆数据(深蓝色)和获得了新的数据(绿色):

Quantization losses
我们不需要处理它因为它仍然可以工作但是这个过程有一个不同的版本叫做RoIAlign它可以修复这个问题
RoI Pooling
现在,当我们把RoI映射到feature map上时,我们可以在上面应用pooling。为了方便起见,我们将再次选择 RoI池化层 的大小,但请记住,大小可能是不同的。你可能会问:“我们为什么要应用RoI Pooling呢?”这是个好问题。如果你看原始设计的Fast R-CNN:

原始的 Fast R-CNN 架构 ,来源:(https://arxiv.org/pdf/1504.08083.pdf)
在 RoI池化层 之后是一个固定大小的 全连接层。因为RoIs的大小不同,所以我们必须将它们池化为相同的大小(在我们的示例中为 3x3x512)。此时我们映射的RoI大小为 4x6x512,你可以想象我们 不能将4除以3:(这就是量化再次使用的地方。)
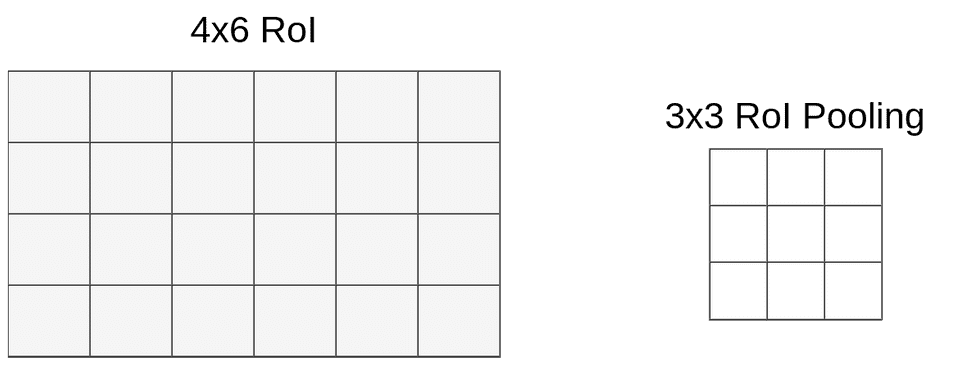
映射后的 RoI 和 池化层
这次我们不需要处理坐标,只需要处理大小。我们很幸运(或者只是适用于池化层的大小) 6 可以整除以 3 得到2,但当你用 4 除以 3 时,剩下1.33。在应用相同的方法(约简 round down )后,我们有一个 1x2的向量。我们的映射是这样的:

数据池化映射
由于量化,我们又一次失去了最底下的那行
 数据的池化映射
数据的池化映射
现在我们能将数据池化成 3x3x512 的矩阵

数据池化处理过程
在本例中,我们应用了 最大池化,但在你的模型中可能会有所不同。当然,这个过程是在整个RoI矩阵上完成的,而不仅仅是在最顶层。所以最终的结果是这样的:

同样的过程应用到原始图像的每一个RoI上,因此最终,我们可能会得到数百甚至数千个3x3x512矩阵。每一个矩阵都必须通过网络的其余部分(从FC层开始)发送。对于它们,模型分别生成bbox和类。
接下来呢?
在池化完成之后,我们确定输入的大小为**3x3x512**,这样我们就可以将其输入到FC层进行进一步处理。还有一件事要讨论。由于量化过程,我们丢失了很多数据。确切地说,就是:
量化数据丢失(深蓝色和浅蓝色),数据获得(绿色)
这可能是一个问题,因为每个“单元格”都包含大量数据(feature map上的1x1x512,在原始图像上大致相当于32x32x3,但请不要使用这个引用,因为卷积层不是这样工作的)。有一种方法可以解决这个问题(RoIAlign)
Understanding Region of Interest — (RoI Align and RoI Warp)
为什么我们想去修改 RoI 池化
正如我们上面所说的,RoI 池化 有一个主要的问题。它在处理过程中丢失了大量的数据。
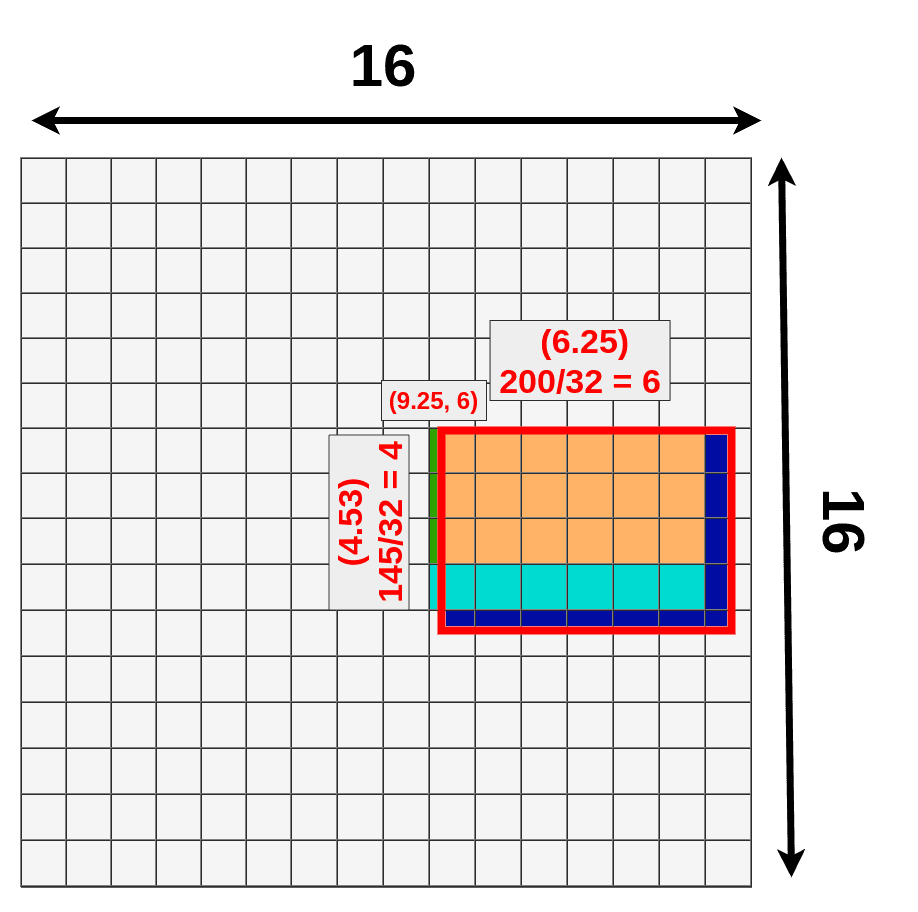
量化数据丢失(深蓝色和浅蓝色),数据获得(绿色)
每次进行 RoI 池化操作的时候,就会丢失关于该对象的部分信息。这降低了整个模型的精确度,很多真正聪明的人都考虑过这个问题。
设置
在我们开始之前,我需要快速解释一下我们的模型。

原始的 Mask R-CNN 架构。来源:(https://arxiv.org/pdf/1703.06870.pdf)

Mask R-CNN 的输出
我们将使用 Mask R-CNN 网络进行测试。我们使用它的唯一原因是,这种网络从一个精确的池化层中获益更多,因此更容易显示 RoI Align和RoI池化之间的差异。我们使用哪个网络并不重要,重要的是它实现了RoI 池化。因此我们的设置不变,看起来是这样的:

模型特征映射过程。图片来源:https://www.flickr.com/photos/bunny/
我们的模型取一个大小为 512x512x3 (宽度x高度x RGB)的图像输入,VGG16将其映射为一个 16x16x512 的feature map。比例因子是 32 。
接下来,我们将使用其中一个proposed RoIs (145x200 box),并尝试将其映射到feature map上。因为不是所有的对象维度都可以整除以32,所以我们没有将RoI与网格对齐。

RoI 位置
- (9.25,6) — top left corner
- 6.25 — width
- 4.53 — height
再一次,我们选择池化层的大小为3x3,所以最终的形状是3x3x512(这只是一个任意的例子,以便更容易在图像上显示。你的池化层可能有不同的大小)。

池化层
在这里,所有看上去和 RoI 池化一样
引入RoI Align
RoI池化和RoI Align之间的主要区别是量化。**RoI Align没有将量化**用于数据池化。你知道Fast R-CNN应用了两次量化。第一次在映射过程中,第二次在池化过程中。

我们可以跳过这些操作,将原始RoI分成9个等大小的小格子,并在每个盒子内应用双线性插值。让我们定义框:

每个框的大小由映射的RoI的大小和池化层的大小决定。我们使用了一个 3x3 的池化层,所以我们必须将映射的RoI (6.25x4.53)除以3。这样我们就得到了一个高为 1.51 ,宽为 2.08 的方框(我在这里约简以使它更容易)。现在我们可以把我们的方框放入映射的RoI中:
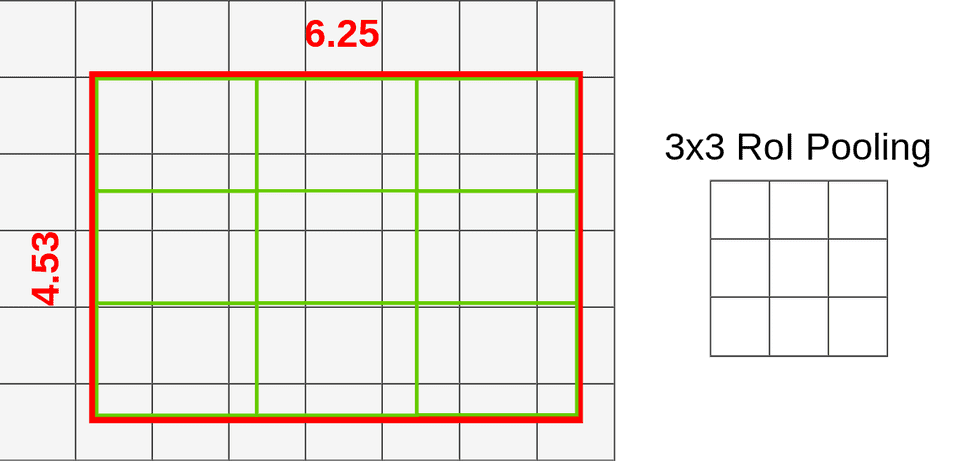
RoI分割成多个框
如果查看第一个框(左上角),可以注意到它覆盖了6个不同的网格单元格。为了提取池化层的值,我们必须从池化层中采样一些数据。为了对数据进行采样,我们必须在盒子里创建 四个采样点。

采样点分布
你可以 通过方框的高度和宽度除以3 来计算每个点的位置。
在我们的例子中,我们计算第一个点(左上角)的坐标如下:
- X = X_box + (width/3) * 1 = 9.94
- Y = Y_box + (height/3) * 1 = 6.50
为了计算第二点(左下角),我们只需要改变Y:
- X = X_box + (width/3) * 1 = 9.94
- Y = Y_box + (height/3) * 2 = 7.01
现在,当我们有了所有的点我们可以应用双线性插值对这个方框进行数据采样。图像处理中常用双线性插值对颜色进行采样,其方程如下:
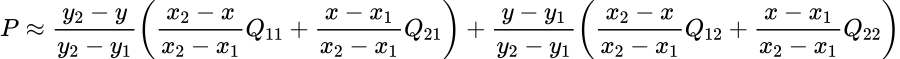
双线性差值方程
不要试图理解这个方程,请看看它是如何工作的图形解释:

双线性插值第一个点
当您从我们的方框中取出第一个点时,除非它已经被取走了,您将它与最邻近的单元格连接(正好在中间)。在本例中,我们的点的坐标是**(9.44,6.50)**。单元格左上角最接近的中间位置是**(9.50,6.50)**(如果我们的点只比网格高0.01,那么它应该是(9.50,5.50))。然后我们必须选择一个左下角的点,最近的是**(9.50,7.50)**遵循同样的规则,我们选择**(10.50,6.50)**和**(10.50,7.50)**作为右上角和右下角的点。在RoI上面,您可以看到整个计算过程,从而得到第一个点(0.14)的值。

双线性插值的第二个点
这一次我们从:
- top-left: (10.50, 6.50)
- bottom-left: (10.50, 7.50)
- top-right: (11.50, 6.50)
- bottom-right: (11.50, 7.50)
你应该开始在这里看到一个模式:)。以下是其他要点:
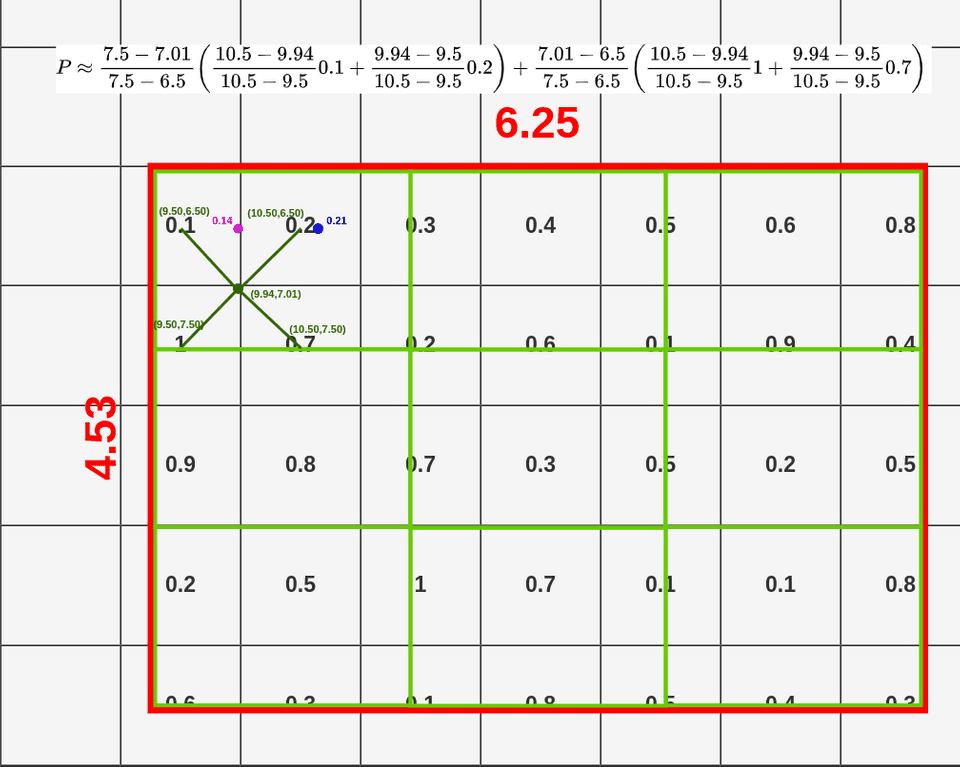
双线性插值的第三个点
- top-left: (9.50, 6.50)
- bottom-left: (9.50, 7.50)
- top-right: (10.50, 6.50)
- bottom-right: (10.50, 7.50)
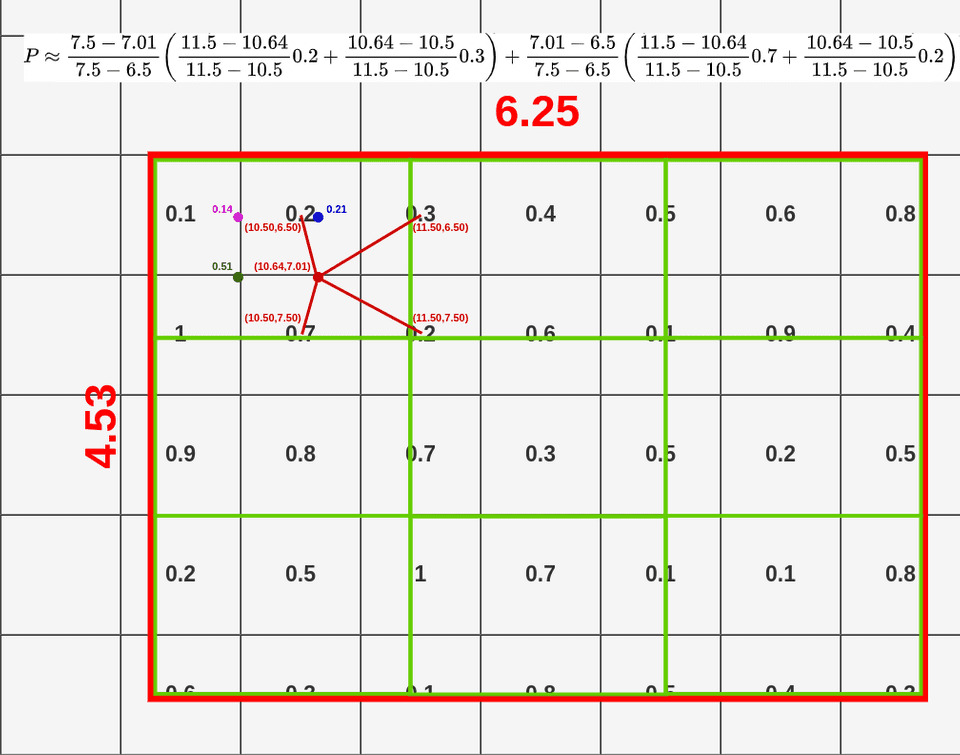
双线性插值的第四个点
- top-left: (10.50, 6.50)
- bottom-left: (10.50, 7.50)
- top-right: (11.50, 6.50)
- bottom-right: (11.50, 7.50)
现在我们已经计算了所有的点,并可以应用**Max Pooling**对他们(它可以是Avg池,如果你想):

第一个 Box Pooling
我不会给你们讲所有的插值,因为这会花很长时间而且你们可能已经知道怎么做了。我将向你们展示整个过程是如何使用RoIAlign,对RoI进行池化的:

当然,这一过程适用于每一层,因此最终结果包含512个层(与feature map输入相同)

请注意,即使我们没有把采样点放在feature map的所有单元格中,我们也通过双线性插值从它们中提取数据。
在这种情况下,单元11x6, 11x7, 11x8, 11x9, 11x10, 13x6, 13x7, 13x8, 13x9, 13x10, 15x6, 15x7, 15x8, 15x9, 15x10将不会有任何点。如果你观察第二个点的计算(第一个框),它仍然使用单元格11x6和11x7来进行双线性插值,即使点在单元格10x6中。
如果您比较从RoIAlign和RoIPooling的数据丢失/数据获取,您应该看到RoIAlign使用来自整个区域来池化数据:
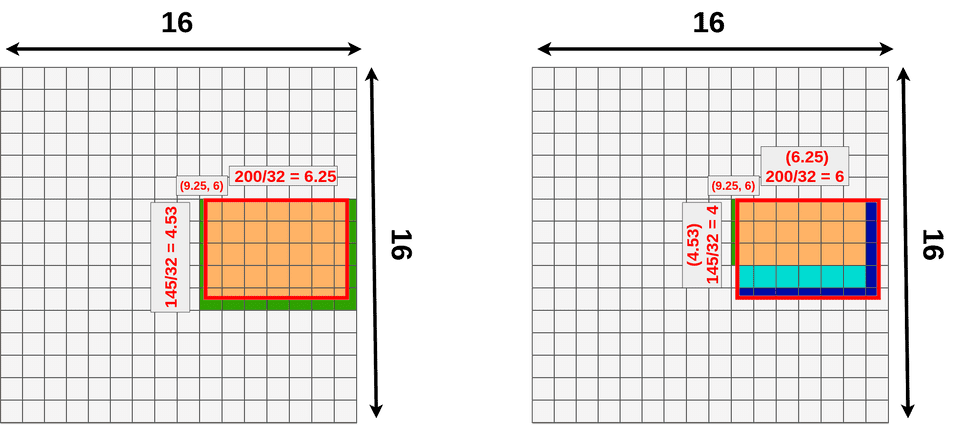
比较RoIAlign(左)和RoIPooling(右)数据源。
- 绿色意味着用于池化的额外数据。
- 蓝色(两种阴影)表示池化是丢失数据。
RoIWarp — meet me in the middle
第三种池化数据的方法是通过 [*Instance-aware semantic segmentation via multi-task network cascades*](https://arxiv.org/pdf/1512.04412.pdf) 中引入的,它被称为RoIWarp。RoIWarp的想法和RoIAlign差不多,唯一的区别是RoIWarp是将RoI量化到feature map上。
https://arxiv.org/pdf/1512.04412.pdf
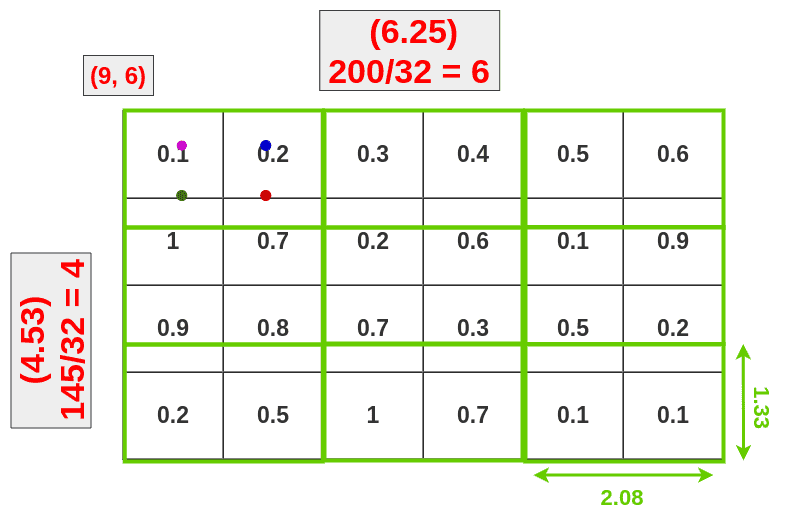
RoI Warp
如果你看数据丢失/额外数据:
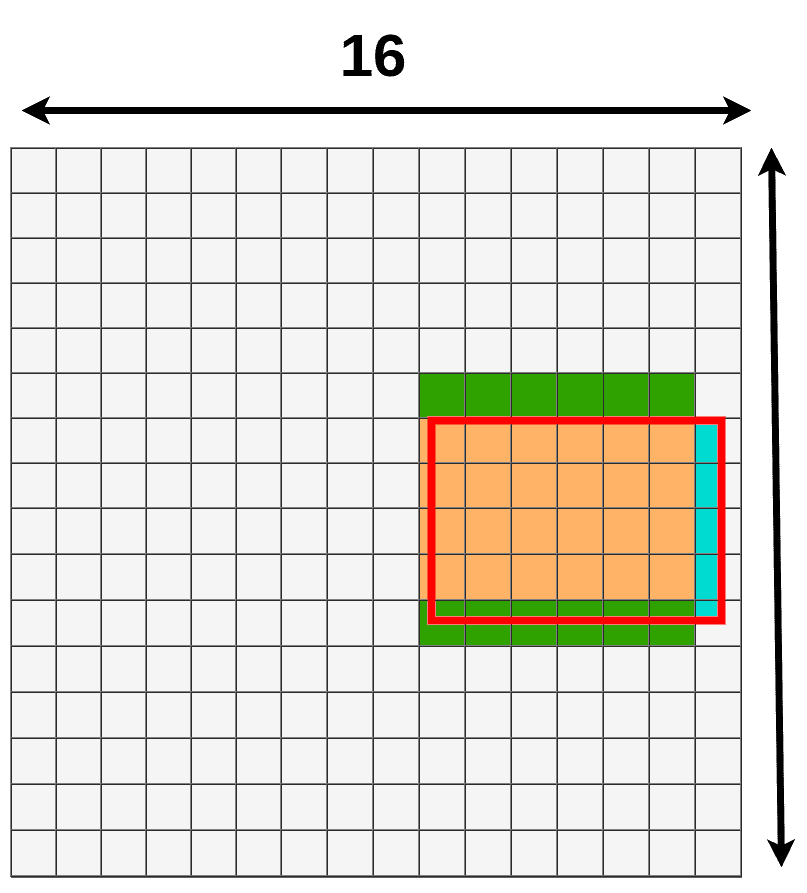
RoI Warp data lost/data gain
由于双线性插值,我们只损失了一小部分。
RoIAlign 和 RoIWarp 是如何影响准确率的
如果我们看一下Mask R-CNN的文件,有一些重要的数字需要讨论。第一个是使用stride 16在ResNet-50-C4上应用不同RoI层时的 平均精度 变化:
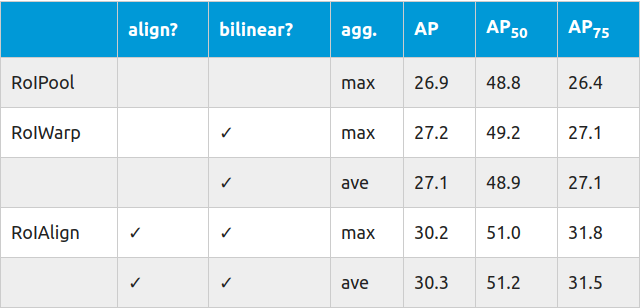
当使用RoIWarp的时候只有一个小的提升,但是使用RoIAlign在精度上给了我们一个显著的提高。这种提升随着步长(stride)的增加而增加:
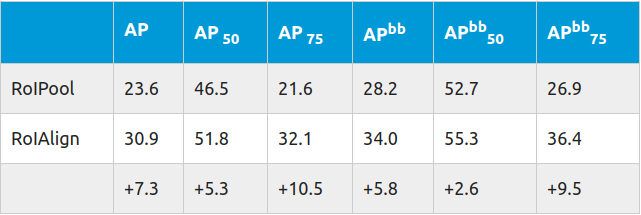
其中 APbb 是检测边界看的平均精度。该测试是在ResNet-50-C5上使用stride 32完成的。
总结
当我们想要提高类似 R-CNN 的模型的准确性时,理解RoI池化是很重要的。2014年论文中提出的Fast R-CNN的标准方法和2018年论文中提出的Mask R-CNN的新方法有很大区别。这并不意味着这些方法只适用于特定的网络,我们可以很容易地使用RoIAlign在Fast R-CNN和RoIPooling在Mask R-CNN,但你必须记住,RoIAlign给我们更好的平均精度。
我真的希望我的解释能容易理解,因为我看过很多关于RoI 池化而不涉及计算的文章。在我看来,更直观的方法总是更好的,特别是如果你不想花一整天的时间阅读原始的论文来最终理解它的作用。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~