
【Python】6000字、22个案例详解Pandas数据分析/预处理时的实用技巧,超简单
Pandas在数据预处理和数据分析方面的硬核干货,我们大致会说Pandas计算交叉列表Pandas将字符串与数值转化成时间类型Pandas将字符串转化成数值类型
Pandas当中的交叉列表
Pandas模块当中的crosstab()函数,它的作用主要是进行分组之后的信息统计,里面会用到聚合函数,默认的是统计行列组合出现的次数,参数如下pandas.crosstab(index, columns,
values=None,
rownames=None,
colnames=None,
aggfunc=None,
margins=False,
margins_name='All',
dropna=True,
normalize=False)
下面小编来解释一下里面几个常用的函数
index: 指定了要分组的类目,作为行 columns: 指定了要分组的类目,作为列 rownames/colnames: 行/列的名称 aggfunc: 指定聚合函数 values: 最终在聚合函数之下,行与列一同计算出来的值 normalize: 标准化统计各行各列的百分比
corss_tab()函数的作用,我们先导入要用到的模块并且读取数据集import pandas as pd
df = pd.read_excel(
io="supermarkt_sales.xlsx",
engine="openpyxl",
sheet_name="Sales",
skiprows=3,
usecols="B:R",
nrows=1000,
)
output
我们先简单来看几个corsstab()函数的例子,代码如下
pd.crosstab(df['城市'], df['顾客类型'])
output
顾客类型 会员 普通
省份
上海 124 115
北京 116 127
四川 26 35
安徽 28 12
广东 30 36
.......
当然我们这里只是指定了一个列,也可以指定多个,代码如下
pd.crosstab(df['省份'], [df['顾客类型'], df["性别"]])
output
顾客类型 会员 普通
性别 女性 男性 女性 男性
省份
上海 67 57 53 62
北京 53 63 59 68
四川 17 9 16 19
安徽 17 11 9 3
广东 18 12 15 21
.....
有时候我们想要改变行索引的名称或者是列方向的名称,我们则可以这么做
pd.crosstab(df['省份'], df['顾客类型'],
colnames = ['顾客的类型'],
rownames = ['各省份名称'])
output
顾客的类型 会员 普通
各省份名称
上海 124 115
北京 116 127
四川 26 35
安徽 28 12
广东 30 36
crosstab()方法当中的margin参数,如下pd.crosstab(df['省份'], df['顾客类型'], margins = True)
output
顾客类型 会员 普通 All
省份
上海 124 115 239
北京 116 127 243
.....
江苏 18 15 33
浙江 119 111 230
黑龙江 14 17 31
All 501 499 1000
你也可以给汇总的那一列重命名,用到的是margins_name参数,如下
pd.crosstab(df['省份'], df['顾客类型'],
margins = True, margins_name="汇总")
output
顾客类型 会员 普通 汇总
省份
上海 124 115 239
北京 116 127 243
.....
江苏 18 15 33
浙江 119 111 230
黑龙江 14 17 31
汇总 501 499 1000
normalize参数,如下pd.crosstab(df['省份'], df['顾客类型'],
normalize=True)
output
顾客类型 会员 普通
省份
上海 0.124 0.115
北京 0.116 0.127
四川 0.026 0.035
安徽 0.028 0.012
广东 0.030 0.036
.......
要是我们更加倾向于是百分比,并且保留两位小数,则可以这么来做
pd.crosstab(df['省份'], df['顾客类型'],
normalize=True).style.format('{:.2%}')
output
顾客类型 会员 普通
省份
上海 12.4% 11.5%
北京 11.6% 12.7%
四川 26% 35%
安徽 28% 12%
广东 30% 36%
.......
aggfunc参数以及values参数,代码如下pd.crosstab(df['省份'], df['顾客类型'],
values = df["总收入"],
aggfunc = "mean")
output
顾客类型 会员 普通
省份
上海 15.648738 15.253248
北京 14.771259 14.354390
四川 20.456135 14.019029
安徽 10.175893 11.559917
广东 14.757083 18.331903
.......
np.sum加总或者是np.median求取平均值。我们还可以指定保留若干位的小数,使用round()函数
df_1 = pd.crosstab(df['省份'], df['顾客类型'],
values=df["总收入"],
aggfunc="mean").round(2)
output
顾客类型 会员 普通
省份
上海 15.65 15.25
北京 14.77 14.35
四川 20.46 14.02
安徽 10.18 11.56
广东 14.76 18.33
.......
时间类型数据的转化
df = pd.DataFrame({'date': [1470195805, 1480195805, 1490195805],
'value': [2, 3, 4]})
pd.to_datetime(df['date'], unit='s')
output
0 2016-08-03 03:43:25
1 2016-11-26 21:30:05
2 2017-03-22 15:16:45
Name: date, dtype: datetime64[ns]
上面的例子是精确到秒,我们也可以精确到天,代码如下
df = pd.DataFrame({'date': [1470, 1480, 1490],
'value': [2, 3, 4]})
pd.to_datetime(df['date'], unit='D')
output
0 1974-01-10
1 1974-01-20
2 1974-01-30
Name: date, dtype: datetime64[ns]
pd.to_datetime()方法pd.to_datetime('2022/01/20', format='%Y/%m/%d')
output
Timestamp('2022-01-20 00:00:00')
亦或是
pd.to_datetime('2022/01/12 11:20:10',
format='%Y/%m/%d %H:%M:%S')
output
Timestamp('2022-01-12 11:20:10')
这里着重介绍一下Python当中的时间日期格式化符号
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 表示的是月份(01-12) %d 表示的是一个月当中的一天(0-31) %H 表示的是24小时制的小时数 %I 表示的是12小时制的小时数 %M 表示的是分钟数 (00-59) %S 表示的是秒数(00-59) %w 表示的是星期数,一周当中的第几天,从星期天开始算 %W 表示的是一年中的星期数
pd.to_datetime()方法当中的errors参数就可以派上用场,df = pd.DataFrame({'date': ['3/10/2000', 'a/11/2000', '3/12/2000'],
'value': [2, 3, 4]})
# 会报解析错误
df['date'] = pd.to_datetime(df['date'])
output

我们来看一下errors参数的作用,代码如下
df['date'] = pd.to_datetime(df['date'], errors='ignore')
df
output
date value
0 3/10/2000 2
1 a/11/2000 3
2 3/12/2000 4
或者将不准确的值转换成NaT,代码如下
df['date'] = pd.to_datetime(df['date'], errors='coerce')
df
output
date value
0 2000-03-10 2
1 NaT 3
2 2000-03-12 4
数值类型的转换
DataFrame数据集,如下df = pd.DataFrame({
'string_col': ['1','2','3','4'],
'int_col': [1,2,3,4],
'float_col': [1.1,1.2,1.3,4.7],
'mix_col': ['a', 2, 3, 4],
'missing_col': [1.0, 2, 3, np.nan],
'money_col': ['£1,000.00','£2,400.00','£2,400.00','£2,400.00'],
'boolean_col': [True, False, True, True],
'custom': ['Y', 'Y', 'N', 'N']
})
output
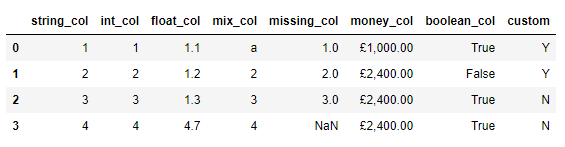
我们先来查看一下每一列的数据类型
df.dtypes
output
string_col object
int_col int64
float_col float64
mix_col object
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object
df.info()方法来调用,如下df.info()
output
'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 string_col 4 non-null object
1 int_col 4 non-null int64
2 float_col 4 non-null float64
3 mix_col 4 non-null object
4 missing_col 3 non-null float64
5 money_col 4 non-null object
6 boolean_col 4 non-null bool
7 custom 4 non-null object
dtypes: bool(1), float64(2), int64(1), object(4)
memory usage: 356.0+ bytes
我们先来看一下从字符串到整型数据的转换,代码如下
df['string_col'] = df['string_col'].astype('int')
df.dtypes
output
string_col int32
int_col int64
float_col float64
mix_col object
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object
int32类型,当然我们指定例如astype('int16')、astype('int8')或者是astype('int64'),当我们碰到量级很大的数据集时,会特别的有帮助。那么类似的,我们想要转换成浮点类型的数据,就可以这么来做
df['string_col'] = df['string_col'].astype('float')
df.dtypes
output
string_col float64
int_col int64
float_col float64
mix_col object
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object
astype('float16')、astype('float32')或者是astype('float128')df['mix_col'] = df['mix_col'].astype('int')
output

pd.to_numeric()方法以及里面的errors参数,代码如下df['mix_col'] = pd.to_numeric(df['mix_col'], errors='coerce')
df.head()
output
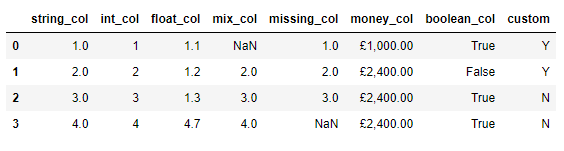
我们来看一下各列的数据类型
df.dtypes
output
string_col float64
int_col int64
float_col float64
mix_col float64
missing_col float64
money_col object
boolean_col bool
custom object
dtype: object
float64类型,要是我们想指定转换成我们想要的类型,例如df['mix_col'] = pd.to_numeric(df['mix_col'], errors='coerce').astype('Int64')
df['mix_col'].dtypes
output
Int64Dtype()
replace()方法将这些符号给替换掉,然后再进行数据类型的转换df['money_replace'] = df['money_col'].str.replace('£', '').str.replace(',','')
df['money_replace'] = pd.to_numeric(df['money_replace'])
df['money_replace']
output
0 1000.0
1 2400.0
2 2400.0
3 2400.0
Name: money_replace, dtype: float64
regex=True的参数,代码如下df['money_regex'] = df['money_col'].str.replace('[\£\,]', '', regex=True)
df['money_regex'] = pd.to_numeric(df['money_regex'])
df['money_regex']
astype()方法,对多个列一步到位进行数据类型的转换,代码如下df = df.astype({
'string_col': 'float16',
'int_col': 'float16'
})
或者在第一步数据读取的时候就率先确定好数据类型,代码如下
df = pd.read_csv(
'dataset.csv',
dtype={
'string_col': 'float16',
'int_col': 'float16'
}
)
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 机器学习在线手册 深度学习笔记专辑 《统计学习方法》的代码复现专辑 AI基础下载 本站qq群955171419,加入微信群请扫码:
评论