
【深度学习】在PyTorch中使用 LSTM 进行新冠病例预测
时间序列数据,顾名思义是一种随时间变化的数据。例如,24 小时时间段内的温度,一个月内各种产品的价格,特定公司一年内的股票价格。长短期记忆网络(LSTM)等高级深度学习模型能够捕捉时间序列数据中的模式,因此可用于对数据的未来趋势进行预测。在本文中,我们将一起学习如何使用 LSTM 算法使用时间序列数据进行未来预测。
本案例并不是试图建立一个模型,并以尽可能最好的方式预测Covid-19。而这也仅仅是一个示例,说明如何使用 PyTorch 在一些真实数据的时间序列数据上使用循环神经网络LSTM。当然,如果你有更好的模型来预测每日确诊病例的数量,欢迎联系小猴子,一起研习呀。

写在前面

什么是 LSTM
长短期记忆网络Long Short Term Memory Networks (LSTM)[2]是一种循环神经网络,旨在克服基本 RNN 的问题,因此网络可以学习长期依赖关系。具体来说,它解决了梯度消失和爆炸的问题——当你通过时间反向传播太多时间步长时,梯度要么消失(变为零)要么爆炸(变得非常大),因为它变成了数字的乘积。
循环神经网络都具有神经网络重复模块链的形式,LSTM 也有这种类似链的结构,但重复模块与标准 RNN 相比有不同的结构。不是只有一个神经网络层,而是有四个,以一种非常特殊的方式进行交互。典型的图如下所示。
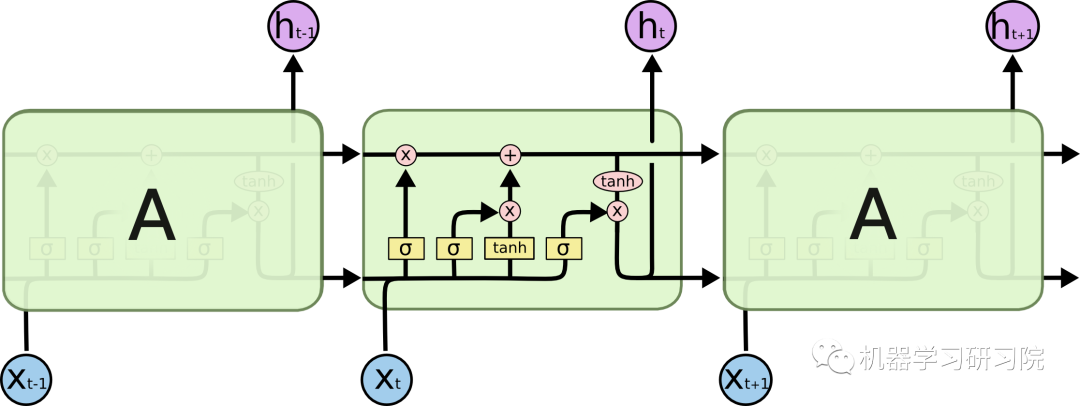
可以从Chris Olah的博客[3]中了解有关 LSTM 的更多信息。
为什么选用LSTM处理数据序列
许多经典方法(例如 ARIMA)尝试以不同的成功率处理时间序列数据(并不是说它们不擅长)。在过去几年中,长短期记忆网络模型在处理这些类型的数据时已成为一种非常有用的方法。
循环神经网络(LSTM 是其中一种)非常擅长处理数据序列。他们可以“回忆”过去(或未来)数据中的模式。在本次案例中,将学习如何基于真实世界的数据使用 LSTM 来预测未来的冠状病毒病例。
PyTorch 中的 LSTM
nn.LSTM 中每一维代表什么意思
Pytorch 中的 LSTM 期望其所有输入都是三维张量。这些张量的轴的语义很重要。第一个轴是序列本身,第二个索引是小批量中的实例,第三个索引是输入的元素。具体来讲:
第一维体现的是序列(sequence)结构,也就是序列的个数,用文章来说,就是每个句子的长度,因为是喂给网络模型,一般都设定为确定的长度,也就是我们喂给LSTM神经元的每个句子的长度,当然,如果是其他的带有序列形式的数据,则表示一个明确分割单位长度,
例如是如果是股票数据内,这表示特定时间单位内,有多少条数据。这个参数也就是明确这个层中有多少个确定的单元来处理输入的数据。
第二维度体现的是batch_size,也就是一次性喂给网络多少条句子,或者股票数据中的,一次性喂给模型多少是个时间单位的数据,具体到每个时刻,也就是一次性喂给特定时刻处理的单元的单词数或者该时刻应该喂给的股票数据的条数。
第三位体现的是输入的元素(elements of input),也就是,每个具体的单词用多少维向量来表示,或者股票数据中 每一个具体的时刻的采集多少具体的值,比如最低价,最高价,均价,5日均价,10均价,等等。
nn.LSTM参数详解
通过源代码中可以看到nn.LSTM继承自nn.RNNBase,其需要关注的参数以及其含义解释如下:
input_size– 输入数据的大小,就是你输入x的向量大小(x向量里有多少个元素)
hidden_size– 隐藏层的大小(即隐藏层节点数量),输出向量的维度等于隐藏节点数。就是LSTM在运行时里面的维度。隐藏层状态的维数,即隐藏层节点的个数,这个和单层感知器的结构是类似的。
num_layers– LSTM 堆叠的层数,默认值是1层,如果设置为2,第二个LSTM接收第一个LSTM的计算结果。
bias– 隐层状态是否带bias,默认为true。bias是偏置值,或者偏移值。没有偏置值就是以0为中轴,或以0为起点。偏置值的作用请参考单层感知器相关结构。
batch_first– 判断输入输出的第一维是否为 batch_size,默认值 False。故此参数设置可以将 batch_size 放在第一维度。因为 Torch 中,人们习惯使用Torch中带有的dataset,dataloader向神经网络模型连续输入数据,这里面就有一个 batch_size 的参数,表示一次输入多少个数据。
在 LSTM 模型中,输入数据必须是一批数据,为了区分LSTM中的批量数据和dataloader中的批量数据是否相同意义,LSTM 模型就通过这个参数的设定来区分。如果是相同意义的,就设置为True,如果不同意义的,设置为False。torch.LSTM 中 batch_size 维度默认是放在第二维度,故此参数设置可以将 batch_size 放在第一维度。
dropout– 默认值0。是否在除最后一个 RNN 层外的其他 RNN 层后面加 dropout 层。输入值是 0-1 之间的小数,表示概率。0表示0概率dripout,即不dropout 。
bidirectional– 是否是双向 RNN,默认为:false,若为 true,则:num_directions=2,否则为1。
下面介绍一下输入数据的维度要求(batch_first=False)。输入数据需要按如下形式传入input, (h_0,c_0)
input: 输入数据,即上面例子中的一个句子(或者一个batch的句子),其维度形状为 (seq_len, batch, input_size)
seq_len: 句子长度,即单词数量,这个是需要固定的。当然假如你的一个句子中只有2个单词,但是要求输入10个单词,这个时候可以用torch.nn.utils.rnn.pack_padded_sequence(),或者torch.nn.utils.rnn.pack_sequence()来对句子进行填充或者截断。 batch:就是你一次传入的句子的数量 input_size: 每个单词向量的长度,这个必须和你前面定义的网络结构保持一致
h_0:维度形状为 (num_layers * num_directions, batch, hidden_size)。
结合下图应该比较好理解第一个参数的含义num_layers * num_directions,即LSTM的层数乘以方向数量。这个方向数量是由前面介绍的bidirectional决定,如果为False,则等于1;反之等于2。 batch:同上 hidden_size: 隐藏层节点数
c_0:维度形状为 (num_layers * num_directions, batch, hidden_size),各参数含义和h_0类似。
当然,如果你没有传入(h_0, c_0),那么这两个参数会默认设置为0。
output:维度和输入数据类似,只不过最后的feature部分会有点不同,即 (seq_len, batch, num_directions * hidden_size)。这个输出tensor包含了LSTM模型最后一层每个time step的输出特征,比如说LSTM有两层,那么最后输出的是[h10,h11,...,h1l],表示第二层LSTM每个time step对应的输出。
h_n:(num_layers * num_directions, batch, hidden_size), 只会输出最后一个time step的隐状态结果。
c_n:(num_layers * num_directions, batch, hidden_size),只会输出最后个time step的cell状态结果。
导入相关模块
import torch
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
from matplotlib import rc
from sklearn.preprocessing import MinMaxScaler
from pandas.plotting import register_matplotlib_converters
from torch import nn, optim
%matplotlib inline
%config InlineBackend.figure_format='retina'
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#93D30C", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 14, 6
register_matplotlib_converters()
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
每日数据集
这些数据由约翰·霍普金斯大学系统科学与工程中心(JHU CSSE)提供,包含按国家/地区报告的每日病例数。数据集可在GitHub上获得[5],并定期更新。
我们将只使用确诊病例的时间序列数据(也提供死亡和康复病例数):
探索性数据分析
首先导入数据集
df = pd.read_csv('./data/time_series_covid19_confirmed_global.csv')
df.head()

这里要注意两点:
数据包含省、国家/地区、纬度和经度。但我们不需要这些数据。 病例数是累积的。我们需要撤消累积。
从去掉前四列我们不需要的数据,可以通过切片直接获取第五列之后的数据。
df = df.iloc[:, 4:]
df.head()

接下来检查缺失值。
df.isnull().sum().sum()
0
一切都已就位。我们对所有行求和,这样就得到了每日累计案例:
daily_cases = df.sum(axis=0)
daily_cases.index = pd.to_datetime(daily_cases.index)
daily_cases.head()
2020-01-22 557
2020-01-23 655
2020-01-24 941
2020-01-25 1434
2020-01-26 2118
dtype: int64
plt.plot(daily_cases)
plt.title("Cumulative daily cases");

我们将通过从前一个值中减去当前值来撤消累加。我们将保留序列的第一个值。
daily_cases = daily_cases.diff().fillna(daily_cases[0]).astype(np.int64)
daily_cases.head()
2020-01-22 557
2020-01-23 98
2020-01-24 286
2020-01-25 493
2020-01-26 684
dtype: int64
plt.plot(daily_cases)
plt.title("Daily cases");
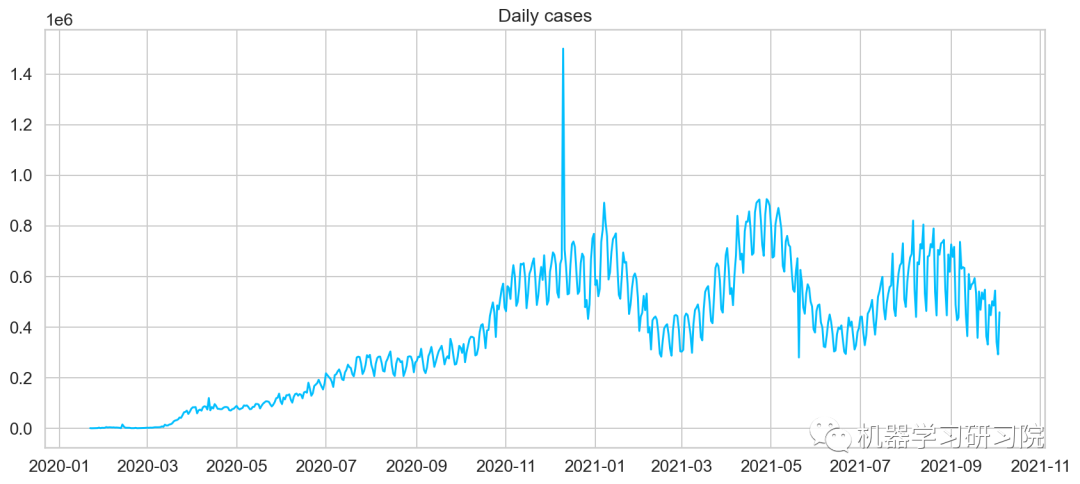
从图中可以看出有一个巨大的峰值,这主要是由于中国检测患者的标准发生了变化。这对我们的模型来说肯定是一个挑战。
让我们检查一下我们拥有的数据量。
daily_cases.shape
(622,)
我们有 622 天的数据。让我们看看我们能用它做什么。
数据预处理
我们将保留前 467 天用于训练,其余时间用于测试。
test_data_size = 155
train_data = daily_cases[:-test_data_size]
test_data = daily_cases[-test_data_size:]
train_data.shape
(467,)
如果我们想提高模型的训练速度和性能,我们必须缩放数据(将值按比例压缩在 0 和 1 之间)。我们将使用来自 scikit-learn 的MinMaxScaler。
scaler = MinMaxScaler()
scaler = scaler.fit(np.expand_dims(train_data, axis=1))
train_data = scaler.transform(np.expand_dims(train_data, axis=1))
test_data = scaler.transform(np.expand_dims(test_data, axis=1))
这份数据中,每天都有大量的病例。可以将把它转换成更小的条数。
def create_sequences(data, seq_length):
xs = []
ys = []
for i in range(len(data)-seq_length-1):
x = data[i:(i+seq_length)]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
seq_length = 7
X_train, y_train = create_sequences(train_data, seq_length)
X_test, y_test = create_sequences(test_data, seq_length)
X_train = torch.from_numpy(X_train).float()
y_train = torch.from_numpy(y_train).float()
X_test = torch.from_numpy(X_test).float()
y_test = torch.from_numpy(y_test).float()
每个训练示例包含7个历史数据点序列和一个标签,该标签表示我们的模型需要预测的真实值。接下来看看我们转换后的数据的样貌。
X_train.shape
torch.Size([459, 7, 1])
X_train[:2]
tensor([[[0.0003],
[0.0000],
[0.0001],
[0.0003],
[0.0004],
[0.0005],
[0.0017]],
[[0.0000],
[0.0001],
[0.0003],
[0.0004],
[0.0005],
[0.0017],
[0.0003]]])
y_train.shape
torch.Size([459, 1])
y_train[:2]
tensor([[0.0003],
[0.0013]])
train_data[:10]
array([[0.00030585],
[0. ],
[0.00012527],
[0.0002632 ],
[0.00039047],
[0.00047377],
[0.00170116],
[0.00032717],
[0.00131268],
[0.00106214]])建立模型
我们将把模型封装到一个自torch.nn.Module的类中。
class CoronaVirusPredictor(nn.Module):
def __init__(self, n_features, n_hidden, seq_len, n_layers=2):
super(CoronaVirusPredictor, self).__init__()
self.n_hidden = n_hidden
self.seq_len = seq_len
self.n_layers = n_layers
self.lstm = nn.LSTM(
input_size=n_features,
hidden_size=n_hidden,
num_layers=n_layers,
dropout=0.5
)
self.linear = nn.Linear(in_features=n_hidden, out_features=1)
def reset_hidden_state(self):
self.hidden = (
torch.zeros(self.n_layers, self.seq_len, self.n_hidden),
torch.zeros(self.n_layers, self.seq_len, self.n_hidden)
)
def forward(self, sequences):
lstm_out, self.hidden = self.lstm(
sequences.view(len(sequences), self.seq_len, -1),
self.hidden
)
last_time_step = \
lstm_out.view(self.seq_len, len(sequences), self.n_hidden)[-1]
y_pred = self.linear(last_time_step)
return y_pred
我们CoronaVirusPredictor 包含 3 个方法:
构造函数 - 初始化所有辅助数据并创建层。 reset_hidden_state- 我们将使用无状态 LSTM,因此我们需要在每个示例之后重置状态。forward- 获取序列,一次将所有序列通过 LSTM 层。我们采用最后一个时间步的输出并将其传递给我们的线性层以获得预测。
训练模型
为模型训练构建一个辅助函数。
def train_model(
model,
train_data,
train_labels,
test_data=None,
test_labels=None
):
loss_fn = torch.nn.MSELoss(reduction='sum')
optimiser = torch.optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 100
train_hist = np.zeros(num_epochs)
test_hist = np.zeros(num_epochs)
for t in range(num_epochs):
model.reset_hidden_state()
y_pred = model(X_train)
loss = loss_fn(y_pred.float(), y_train)
if test_data is not None:
with torch.no_grad():
y_test_pred = model(X_test)
test_loss = loss_fn(y_test_pred.float(), y_test)
test_hist[t] = test_loss.item()
if t % 10 == 0:
print(f'Epoch {t} train loss: {loss.item()} test loss: {test_loss.item()}')
elif t % 10 == 0:
print(f'Epoch {t} train loss: {loss.item()}')
train_hist[t] = loss.item()
optimiser.zero_grad()
loss.backward()
optimiser.step()
return model.eval(), train_hist, test_hist
注意,隐藏层的状态在每个epoch开始时被重置。我们不使用批量的数据,模型可以一次看到每个样本。将使用均方误差来测量我们的训练和测试误差,并将两者都记录下来。
接下来创建一个模型的实例并训练它。
model = CoronaVirusPredictor(
n_features=1,
n_hidden=512,
seq_len=seq_length,
n_layers=2
)
model, train_hist, test_hist = train_model(
model,
X_train,
y_train,
X_test,
y_test
)
Epoch 0 train loss: 36.648155212402344 test loss: 19.638214111328125
Epoch 10 train loss: 15.204809188842773 test loss: 1.5947879552841187
Epoch 20 train loss: 12.796365737915039 test loss: 2.8455893993377686
Epoch 30 train loss: 13.453448295593262 test loss: 5.292770862579346
Epoch 40 train loss: 13.023208618164062 test loss: 2.4893276691436768
Epoch 50 train loss: 12.724889755249023 test loss: 4.096951007843018
Epoch 60 train loss: 12.620814323425293 test loss: 3.4106807708740234
Epoch 70 train loss: 12.63078498840332 test loss: 3.245408296585083
Epoch 80 train loss: 12.615142822265625 test loss: 3.529395341873169
Epoch 90 train loss: 12.61486530303955 test loss: 3.571239948272705
如何解决神经网络训练时loss不下降的问题?
由结果可以看出,本次训练的网络效果并不是很好,可以通过一定的方法对模型进行进一步优化。这里建议参考该博客:如何解决神经网络训练时loss不下降的问题[6]
训练集loss不下降
1.模型结构和特征工程存在问题
2.权重初始化方案有问题
3.正则化过度
4.选择合适的激活函数、损失函数
5.选择合适的优化器和学习速率
6.训练时间不足
7.模型训练遇到瓶颈:梯度消失、大量神经元失活、梯度爆炸和弥散、学习率过大或过小等
8.batch size过大
9.数据集未打乱
10.数据集有问题
11.未进行归一化
12.特征工程中对数据特征的选取有问题验证集loss不下降
1.适当的正则化和降维
2.适当降低模型的规模
3.获取更多的数据集
来看看训练和测试损失。
plt.plot(train_hist, label="Training loss")
plt.plot(test_hist, label="Test loss")
plt.ylim((0, 100))
plt.legend();
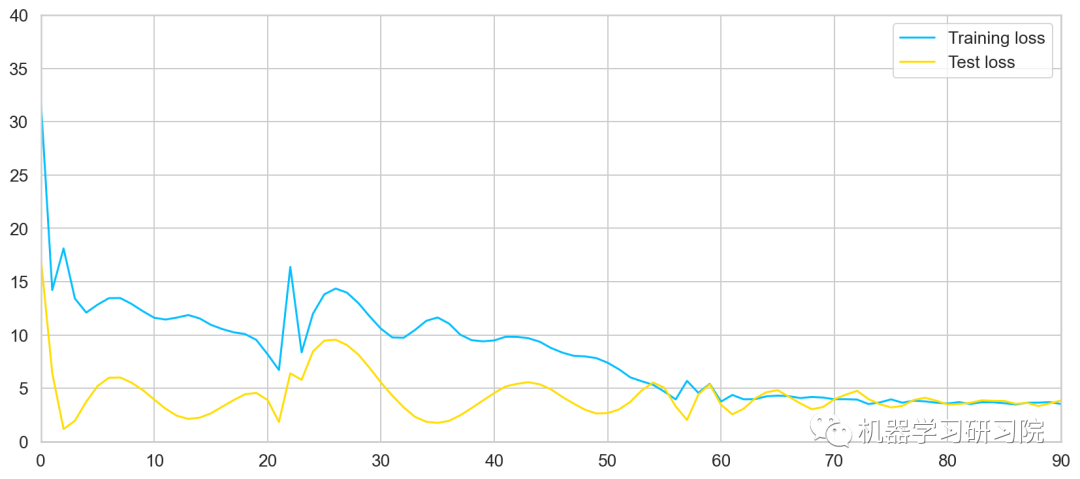
我们的模型在50个时代之后并没有改善。回想一下,我们只有很少的数据,并且模型损失并未优化至最佳。也许我们不该那么相信我们的模型?
预测未来几天的病例
我们的所建立的模型(由于训练它的方式)只能预测未来的某一天。我们将采用一个简单的策略来克服这个限制。使用预测值作为预测未来几天的输入。
with torch.no_grad():
test_seq = X_test[:1]
preds = []
for _ in range(len(X_test)):
y_test_pred = model(test_seq)
pred = torch.flatten(y_test_pred).item()
preds.append(pred)
new_seq = test_seq.numpy().flatten()
new_seq = np.append(new_seq, [pred])
new_seq = new_seq[1:]
test_seq = torch.as_tensor(new_seq
).view(1, seq_length, 1).float()
这里需要撤销测试数据和模型预测的缩放转换比例,即使用逆缩放器变换,已得到原始数据。
true_cases = scaler.inverse_transform(
np.expand_dims(y_test.flatten().numpy(), axis=0)
).flatten()
predicted_cases = scaler.inverse_transform(
np.expand_dims(preds, axis=0)
).flatten()
一起看看结果,将训练数据、测试数据及预测数据绘制在同一张画布上,一起比较下预测结果。
plt.plot(
daily_cases.index[:len(train_data)],
scaler.inverse_transform(train_data).flatten(),
label='Historical Daily Cases')
plt.plot(
daily_cases.index[len(train_data):len(train_data) + len(true_cases)],
true_cases,
label='Real Daily Cases')
plt.plot(
daily_cases.index[len(train_data):len(train_data) + len(true_cases)],
predicted_cases,
label='Predicted Daily Cases')
plt.legend();
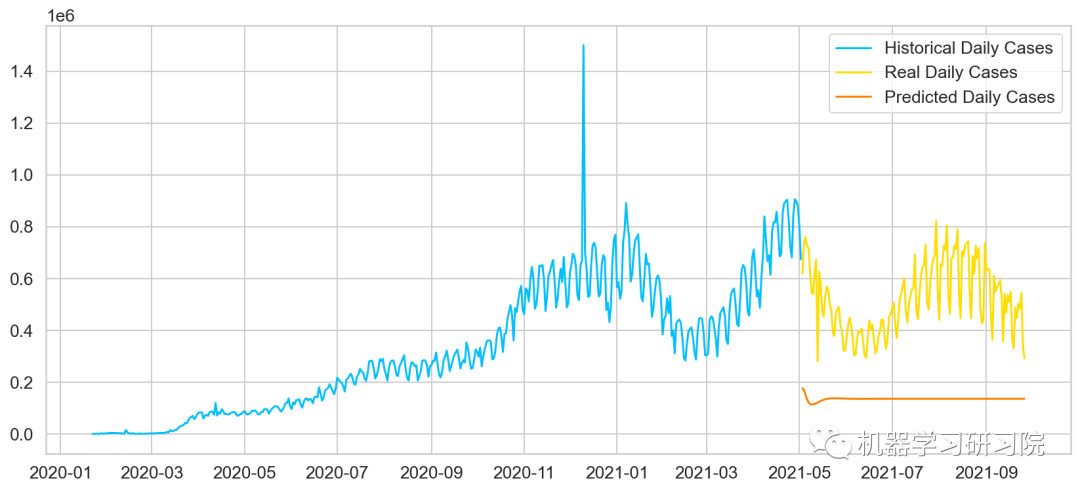
正如预期的那样,我们的模型表现不佳。也就是说,预测似乎是正确的(可能是因为使用最后一个数据点作为下一个数据点的强预测器)。
使用所有数据来训练
现在,我们将使用所有可用数据来训练相同的模型。
scaler = MinMaxScaler()
scaler = scaler.fit(np.expand_dims(daily_cases, axis=1))
all_data = scaler.transform(np.expand_dims(daily_cases, axis=1))
all_data.shape
(622, 1)
预处理和训练步骤相同。
X_all, y_all = create_sequences(all_data, seq_length)
X_all = torch.from_numpy(X_all).float()
y_all = torch.from_numpy(y_all).float()
model = CoronaVirusPredictor(
n_features=1,
n_hidden=512,
seq_len=seq_length,
n_layers=2
)
model, train_hist, _ = train_model(model, X_all, y_all)
Epoch 0 train loss: 28.981904983520508
Epoch 10 train loss: 12.115002632141113
Epoch 20 train loss: 10.47011661529541
Epoch 30 train loss: 18.45709991455078
Epoch 40 train loss: 14.793025016784668
Epoch 50 train loss: 12.061325073242188
Epoch 60 train loss: 11.918513298034668
Epoch 70 train loss: 11.55040168762207
Epoch 80 train loss: 10.834881782531738
Epoch 90 train loss: 15.602020263671875
预测未来病例
使用“完全训练”的模型来预测未来 12 天的确诊病例。
DAYS_TO_PREDICT = 12
with torch.no_grad():
test_seq = X_all[:1]
preds = []
for _ in range(DAYS_TO_PREDICT):
y_test_pred = model(test_seq)
pred = torch.flatten(y_test_pred).item()
preds.append(pred)
new_seq = test_seq.numpy().flatten()
new_seq = np.append(new_seq, [pred])
new_seq = new_seq[1:]
test_seq = torch.as_tensor(new_seq).view(1, seq_length, 1).float()
和以前一样,我们将逆缩放器变换。
predicted_cases = scaler.inverse_transform(
np.expand_dims(preds, axis=0)
).flatten()
要使用历史和预测案例创建一个很酷的图表,我们需要扩展数据框的日期索引。
daily_cases.index[-1]
Timestamp('2020-03-02 00:00:00')
predicted_index = pd.date_range(
start=daily_cases.index[-1],
periods=DAYS_TO_PREDICT + 1,
closed='right'
)
predicted_cases = pd.Series(
data=predicted_cases,
index=predicted_index
)
plt.plot(predicted_cases, label='Predicted Daily Cases')
plt.legend();
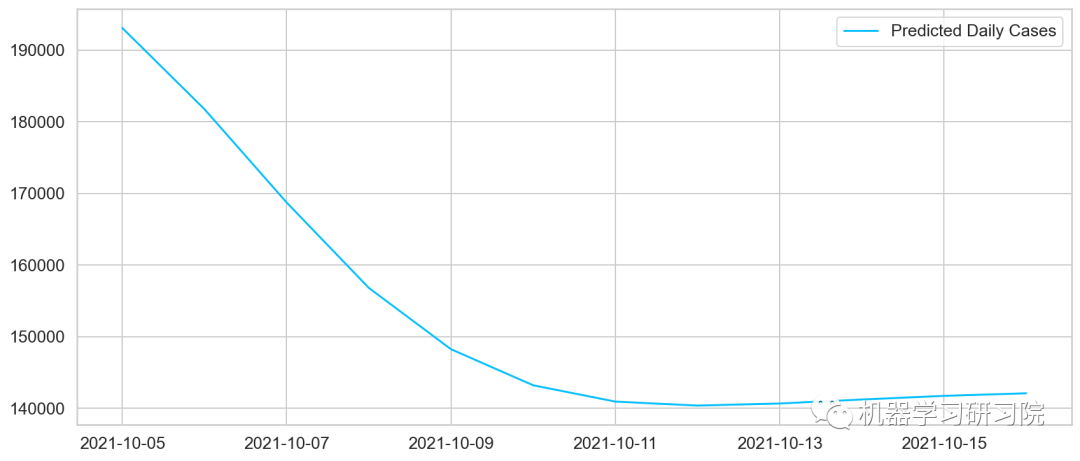
现在我们可以使用所有数据来绘制结果。
plt.plot(daily_cases, label='Historical Daily Cases')
plt.plot(predicted_cases, label='Predicted Daily Cases')
plt.legend();
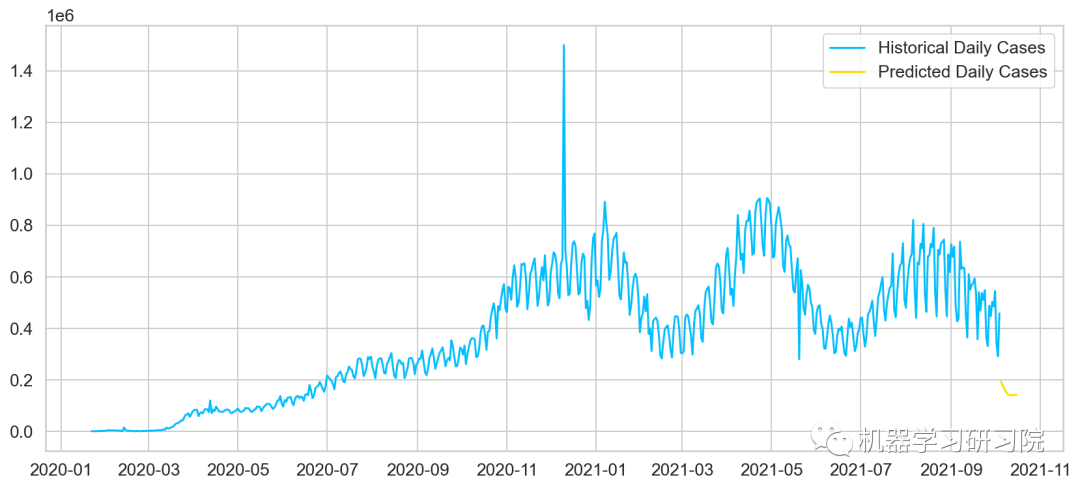
从这里也能看,本次模型仍然有待优化。至于如何优化模型,待后续更新。
写在最后
我们学习了如何使用 PyTorch 创建处理时间序列数据的循环神经网络。模型性能不是很好,但考虑到数据量很少,这是可以预期的。
预测每日 Covid-19 病例的问题确实是一个难题。同样希望一段时间后一切都会恢复正常。
参考资料
参考原文: https://curiousily.com/posts/time-series-forecasting-with-lstm-for-daily-coronavirus-cases/
[2]Long Short Term Memory Networks (LSTM): https://en.wikipedia.org/wiki/Long_short-term_memory
[3]Chris Olah的博客: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[4]参数详解: https://blog.csdn.net/wangwangstone/article/details/90296461
[5]数据集可在GitHub上获得: https://github.com/CSSEGISandData/COVID-19
[6]如何解决神经网络训练时loss不下降的问题: https://blog.ailemon.net/2019/02/26/solution-to-loss-doesnt-drop-in-nn-train/
往期精彩回顾 本站qq群955171419,加入微信群请扫码: