
准确率87.5%,微软、中科大提出十字形注意力的CSWin Transformer
↑ 点击蓝字 关注极市平台

作者丨小马
编辑丨极市平台
极市导读
本文提出了十字形状的自注意力机制,能够在水平和垂直两个方向上同时计算注意力权重。在没有额外数据预训练的情况,CSWin-B能达到85.4%的top-1准确率,用ImageNet-21K预训练时,能够达到87.5%的top-1准确率。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面
本文工作的出发点和目前大多数的ViT的出发点非常相似,都是为了解决Self-Attention(SA)的计算复杂度和输入特征大小呈平方的关系,导致对于一些细粒度的任务(e.g. 目标检测、实例分割)不太友好。解决这一问题的最直接的方法就是引入局部Attention,但是在只有局部注意力的情况下,每个block的信息不能交互,会导致模型性能的下降,目前解决这一问题的方法有Halo[1]和Shift Window[2]。本文提出了十字形状的自注意力机制,能够在水平和垂直两个方向上同时计算注意力权重。
除此之外,作者还提出了一种局部增强的位置编码,相比于以前的位置编码,本文提出的位置编码有两个好处:1)能够适应不同大小的输入特征;2)具有更强的局部假设偏置。
作者在ImageNet上进行实验,在没有额外数据预训练的情况,CSWin-B能达到85.4%的top-1准确率,用ImageNet-21K预训练时,能够达到87.5%的top-1准确率。此外,作者还在目标检测和语义分割任务上进行了实验,都取得了非常好的效果。
1. 论文和代码地址
CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
论文地址:https://arxiv.org/abs/2107.00652
代码地址:未开源
2. Motivation
众所周知,由于SA的时间复杂度和输入特征的大小成平方关系,因此ViT对于一些需要高分辨率的任务,在计算上是效率不高的。因此Local Attention被提出来解决这个问题,并且用Halo、Shift等操作来交互相邻窗口的位置信息,但是这样的操作使得模型的感受野是慢慢扩大的,因此需堆积很多层之后才能获取全局的注意力,而比较大的感受野对于检测、分割等任务又是非常重要的。那么怎么才能保持计算量在比较低的情况下,获取更大的感受野呢?
所以本文作者就提出了一个十字形状的自注意力(Cross-Shaped Window (CSWin) self-attention),能够并行的计算横向和纵向的注意力。
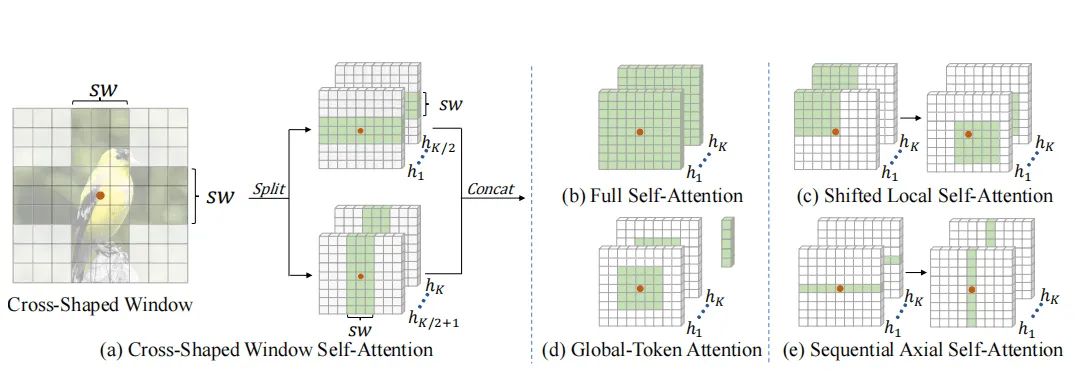
如上图所示,CSWin的感受野是和(b),(c),(d),(e)不同的,并且本文的方法在计算不同方向attention的时候是并行的,而(c),(e)计算不同区域attention的时候是串行的,这就会引入额外的计算量和参数量。
Noting:个人觉得其实本文的结构跟(e)的结构非常相似,都是捕获横向和纵向的注意力,不同的是本文用了一半的head捕获横向注意力,另一半的head捕获纵向注意力,但是e的结构是先捕获横向注意力、再捕获纵向注意力,后面的操作是基于前面的操作,所以不能够并行计算,这就导致模型的计算时间会变长。
除此之外,作者还引入了一个能够适应不同大小输入特征的相对位置编码(Locally-enhanced Positional Encoding (LePE)),用卷积来加强局部偏置,并直接加到SA的结果后面,来减少计算量。
3. 方法
3.1. Overall Architecture
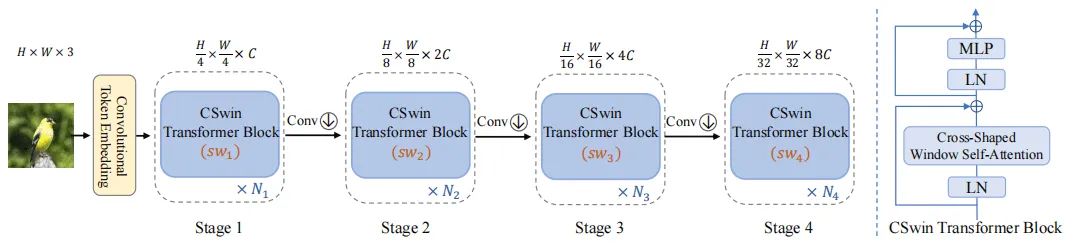
本文的模型结构如上图所示,整个结构和Swin Transformer非常相似(Swin-T的结构如下图所示)。
首先在token embedding的时候,作者采用了带重叠的卷积(步长为5,卷积核大小为7x7)来获得
的patch token,之前也有工作[3]证明带重叠的卷积会比不重叠的卷积效果要好。每个CSwin Transformer Block进行上图(右)的操作。之后,为了减少计算量和获取更大感受野,在每一个stage之后,作者又用了带重叠的卷积(步长为2,卷积核大小为3x3),将特征缩小为原来的1/2。
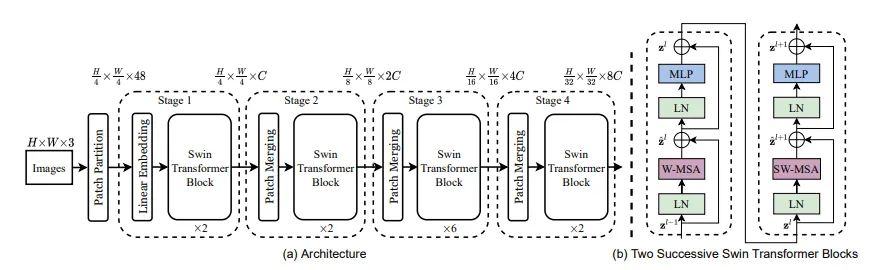
相比于其他ViT结构,CSwin Transformer主要有两点不同:1)将SA替换成了SCWin Self-Attention;2)提出了一个新的位置编码算法,引入局部假设偏置,并能够和SA模块并行计算。
3.2. Cross-Shape Window(SCWin) Self-Attention
由于HaloNet、Swin Transformer都能够的感受野都是慢慢扩大,因此获取全局注意力之前需要经过很多层。为了扩大attention的区域,更加有效的获取全局注意力,本文提出了一个十字形状的attention。
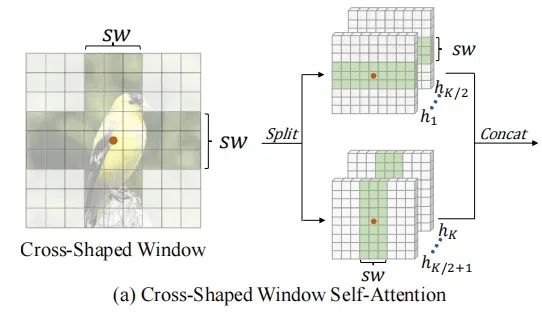
如上图所示,作者将attention的所有head分为两部分,一部分用来捕获横向的注意力(attention区域为:
),另一部分用来捕获纵向的注意力(attention的区域为:
),其中
为超参数,在不同的stage中sw是不一样的。
Noting:
为什么每个stage的sw是不一样的?
因为SWin每个stage之后都进行了降采样,所以越到后面的stage,特征的H和W会越来越小。作者在前面的stage中采用了较小的sw,后面的stage中采用较大的sw。
个人觉得这么做主要有两方面的原因:
1)第一,前期H和W较大,如果sw也比较大,那就会导致计算量很大,极端情况下,sw=H或者sw=W,那就相当于直接进行了全局的SA,导致计算量爆炸。因此作者在前期H、W较大的时候,用较小的sw来限制计算量;后期等H、W比较小的时候,在用比较大的sw来扩大感受野。
2)第二,前面的Stage是用来获取局部的attention(这里指宽度较小的十字),后面的stage用获取全局的attention。(但是个人感觉如果这么做的话,就和作者提的Motivation有点冲突了,因为其他ViT结构的由局部慢慢变成全局注意力,如果前面的stage用较小的sw,那么前期也只能捕获局部注意力(十字形的局部),所以就跟其他结构一样是从局部到全局的一个过程。
3.3. 计算复杂度分析
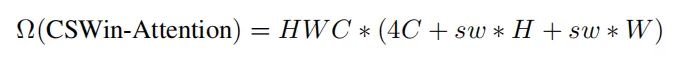
CSWin的计算复杂度如上面的公式,由三部分组成:4个FC的复杂度,计算横向attention的复杂度,计算纵向attention的复杂度。作者在每个stage取的sw分别为[1,2,7,7],前面sw较小,后面sw较大,使得CSWin的感受野能够逐步变大,并且计算量也能控制在一个可以接受的范围内。
3.4. 局部增强的位置编码

SA具有排列不变性(不同排列的输出结果是一样的),为了弥补SA的这个缺陷,通常会在Transformer上加入位置编码。
APE/CPE(上图左)是在进行SA之前就加入了位置信息,RPE(上图中)是在计算权重矩阵的过程中加入相对位置信息。作者采用了一种更加直接的方式进行了位置信息编码:直接将位置信息加入到Value中,然后将结果加到SA的结果中。
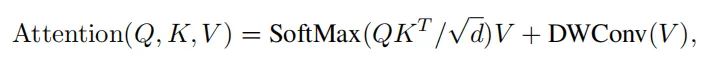
如上面的公式所示,作者为了减少计算量,只捕获了局部的注意力,所以用了一个Depth-wise Conv对value进行卷积,然后将结果加入到了SA的结果中。
(这么做一方面是能够加入相对位置信息,另一方面还引入了局部的假设偏置,来提高模型的泛化能力。)
3.5. CSWin Transformer Block
CSWin Transformer block的结构和其它ViT的结构都非常相似,不同的只是加了局部增强的位置编码,将注意力机制换成了十字形状的Self-Attention。可以用公式表示成:
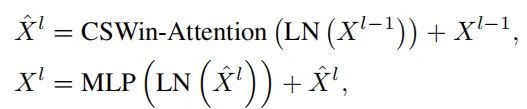
根据参数量和计算量,注意这个提出了CSWin-T的四个实例化变种,配置如下:

4.实验
4.1. ImageNet-1K Classification
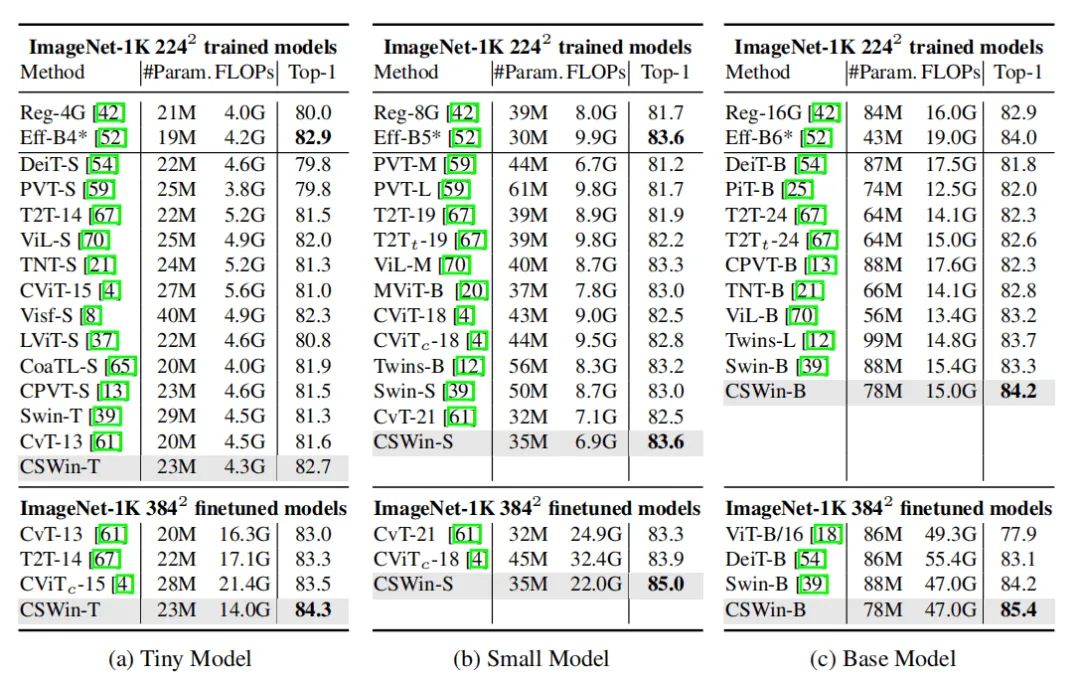
如上图所示,在没有预训练的情况下,CSWin-T能够用相似的计算量和参数量,比其他的ViT和CNN结构达到更好的效果。
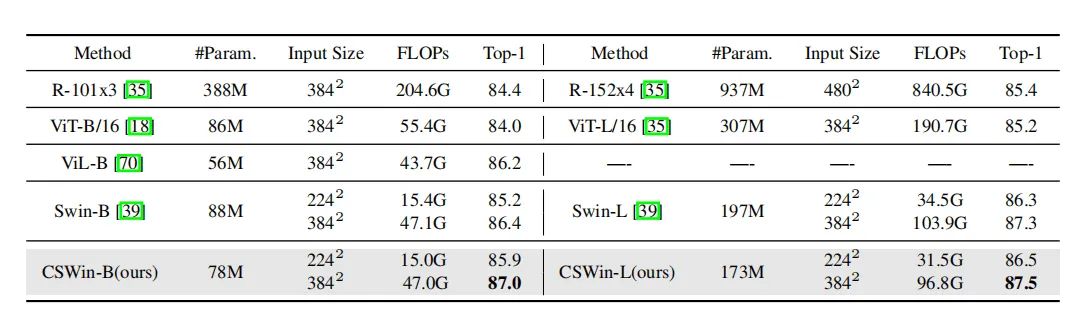
在用ImageNet-21K预训练的情况SCWin-L能够达到87.5%的准确率
4.2. COCO Object Detection
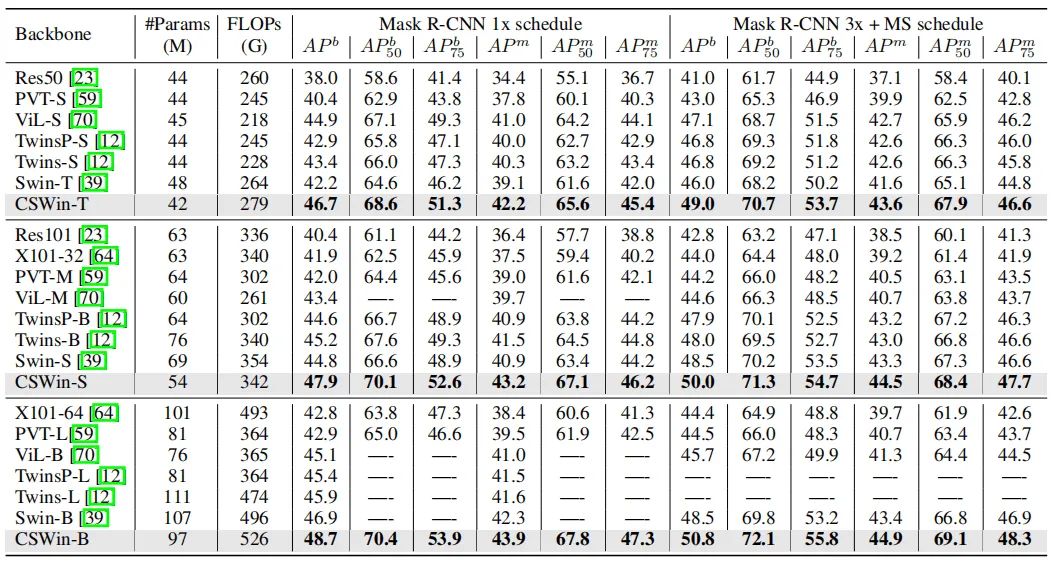
在COCO数据下,使用Mask R-CNN的框架,CSWin的能够取得不错的效果。
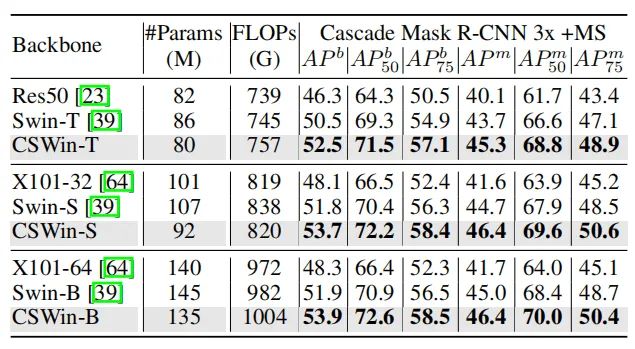
使用CascadeMask R-CNN的框架,CSWin依旧能够超过SWin-T和ResNeXt。
4.3. ADE20K Semantic Segmentation
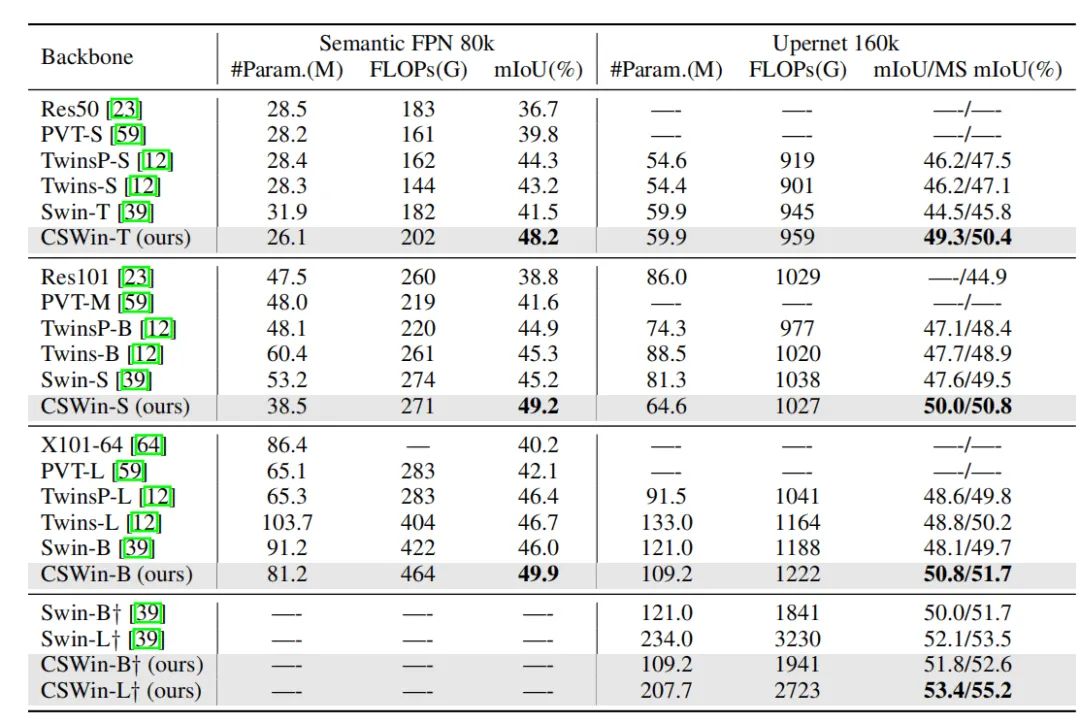
在语义分割任务上,本文也能比Swin-Transformer高出比较多的性能。
4.4. 消融实验
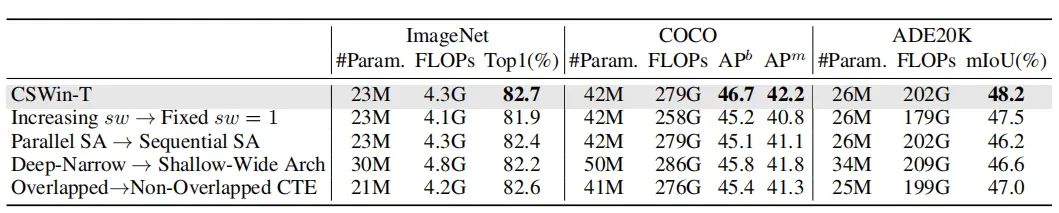
可以看出逐步增大sw、并行的SA、用层数较多通道较少的结构、用重叠的卷积,这些trick能够提升网络的性能。
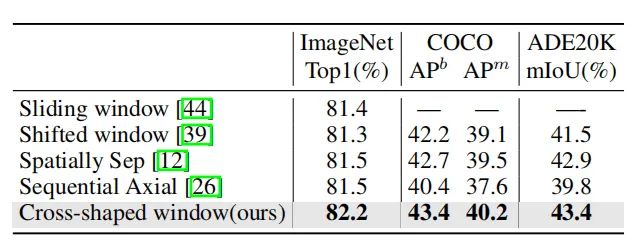
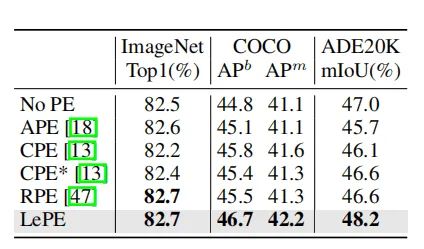
本文提出的十字形注意力、局部增强的位置编码,都能有效提升在检测、分割任务上的性能。
5. 总结
CSWin最大的不同就是引入了一个十字形状的注意力,看似和VOLO、CoAtNet、Focal SA有很大的不同,但本质上作者在进行下采样和局部增强的位置编码时,都用的是卷积,在这个过程中还是引入了局部假设偏置,所以本质上这还是一篇“SA全局建模+局部假设偏置”的文章,从这一点上说就和上面提到的文章很像了,只是实现方式不一样。(从实验结果看,LePE对模型性能的提升还是非常大的,这也可以间接说明,局部偏置对于CV任务的重要性)
但是这篇文章很有意思的一点是,将head进行了分组,不同组进行计算不同方向(区域)的注意力,由于是并行计算的,所以并不需要额外的计算时间和参数。作者在这篇文章中只是将这些head分为两组,那分为更多组,每个组还是关注不同的区域,那样感受野就会更大,对模型的性能是否还会有进一步的提升呢?
参考文献
[1]. Vaswani, Ashish, et al. "Scaling local self-attention for parameter efficient visual backbones." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[2]. Liu, Ze, et al. "Swin transformer: Hierarchical vision transformer using shifted windows." arXiv preprint arXiv:2103.14030 (2021).
[3]. Xiao, Tete, et al. "Early Convolutions Help Transformers See Better." arXiv preprint arXiv:2106.14881 (2021).
本文亮点总结
1.首先在token embedding的时候,作者采用了带重叠的卷积(步长为5,卷积核大小为7x7)来获得
的patch token。之后,为了减少计算量和获取更大感受野,在每一个stage之后,作者又用了带重叠的卷积(步长为2,卷积核大小为3x3),将特征缩小为原来的1/2。
2.APE/CPE是在进行SA之前就加入了位置信息,RPE是在计算权重矩阵的过程中加入相对位置信息。作者采用了一种更加直接的方式进行了位置信息编码:直接将位置信息加入到Value中,然后将结果加到SA的结果中。
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“调研报告”获取《2020年度中国计算机视觉人才调研报告》~
极市干货
YOLO教程:一文读懂YOLO V5 与 YOLO V4|大盘点|YOLO 系目标检测算法总览|全面解析YOLO V4网络结构
实操教程:PyTorch vs LibTorch:网络推理速度谁更快?|只用两行代码,我让Transformer推理加速了50倍|PyTorch AutoGrad C++层实现
算法技巧(trick):深度学习训练tricks总结(有实验支撑)|深度强化学习调参Tricks合集|长尾识别中的Tricks汇总(AAAI2021)
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge|3D人体目标检测与行为分析竞赛开赛,奖池7万+,数据集达16671张!

# 极市原创作者激励计划 #
极市平台深耕CV开发者领域近5年,拥有一大批优质CV开发者受众,覆盖微信、知乎、B站、微博等多个渠道。通过极市平台,您的文章的观点和看法能分享至更多CV开发者,既能体现文章的价值,又能让文章在视觉圈内得到更大程度上的推广。
对于优质内容开发者,极市可推荐至国内优秀出版社合作出书,同时为开发者引荐行业大牛,组织个人分享交流会,推荐名企就业机会,打造个人品牌 IP。
投稿须知:
1.作者保证投稿作品为自己的原创作品。
2.极市平台尊重原作者署名权,并支付相应稿费。文章发布后,版权仍属于原作者。
3.原作者可以将文章发在其他平台的个人账号,但需要在文章顶部标明首发于极市平台
投稿方式:
添加小编微信Fengcall(微信号:fengcall19),备注:姓名-投稿
△长按添加极市平台小编
觉得有用麻烦给个在看啦~
