
Pravega 实践 | Pravega Flink Connector 的过去、现在和未来
摘要:本文整理自戴尔科技集团软件工程师周煜敏在 Flink Forward Asia 2020 分享的议题《Pravega Flink Connector 的过去、现在和未来》,文章内容为:
Pravega 以及 Pravega connector 简介 Pravega connector 的过去 回顾 Flink 1.11 高阶特性心得分享 未来展望 Pravega 创客大赛介绍
 GitHub 地址
GitHub 地址 一、Pravega 以及 Pravega connector 简介

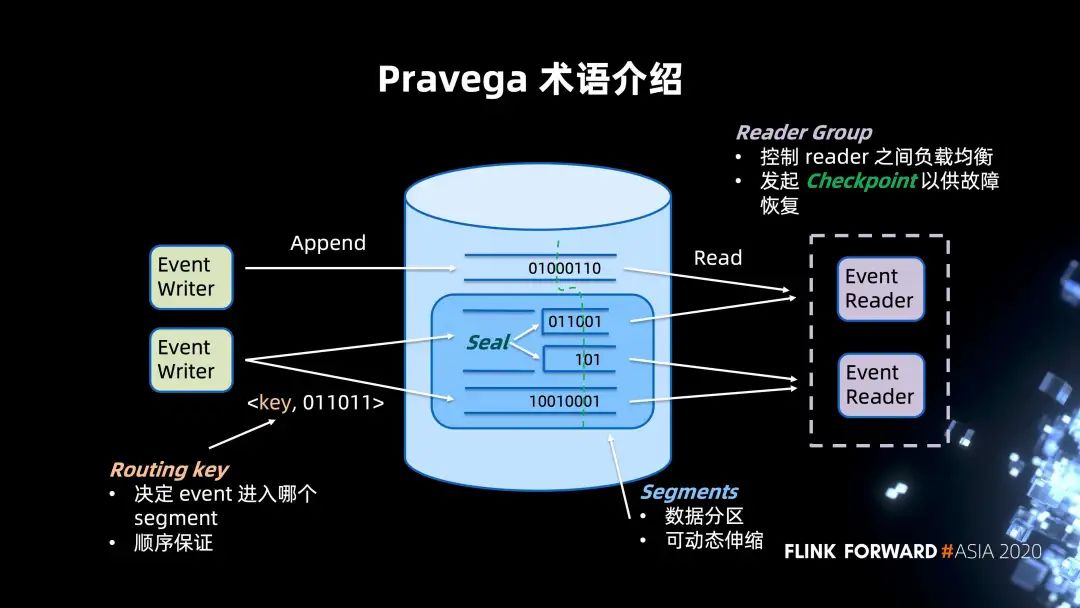
中间部分是一个 Pravega 的集群 ,它整体是以 stream 抽象的系统。stream 可以认为是类比 Kafka 的 topic。同样,Pravega 的 Segment 可以类比 Kafka 的 Partition,作为数据分区的概念,同时提供动态伸缩的功能。 Segment 存储二进制数据数据流,并且根据数据流量的大小,发生 merge 或者 split 的操作,以释放或者集中资源。此时 Segment 会进行 seal 操作禁止新数据写入,然后由新建的 Segment 进行新数据的接收。 图片左侧是数据写入的场景,支持 append only 的写入。用户可以对于每一个 event 指定 Routing key 来决定 Segment 的归属。这一点可以类比 Kafka Partitioner。单一的 Routing key 上的数据具有保序性,确保读出的顺序与写入相同。 图片右侧是数据读取的场景,多个 reader 会有一个 Reader Group 进行管控。Reader Group 控制着 reader 之间的负载均衡的,来保证所有的 Segment 能在 reader 之间均匀分布。同时也提供 Checkpoint 机制形成一致的 stream 切分来保证数据的故障恢复。对于 "读",我们支持批和流两种语义。对于流的场景,我们支持尾读;对于批的场景,我们会更多的考虑高并发来达到高吞吐。
二、Pravega Flink connector 的过去
1. Pravega 发展历程
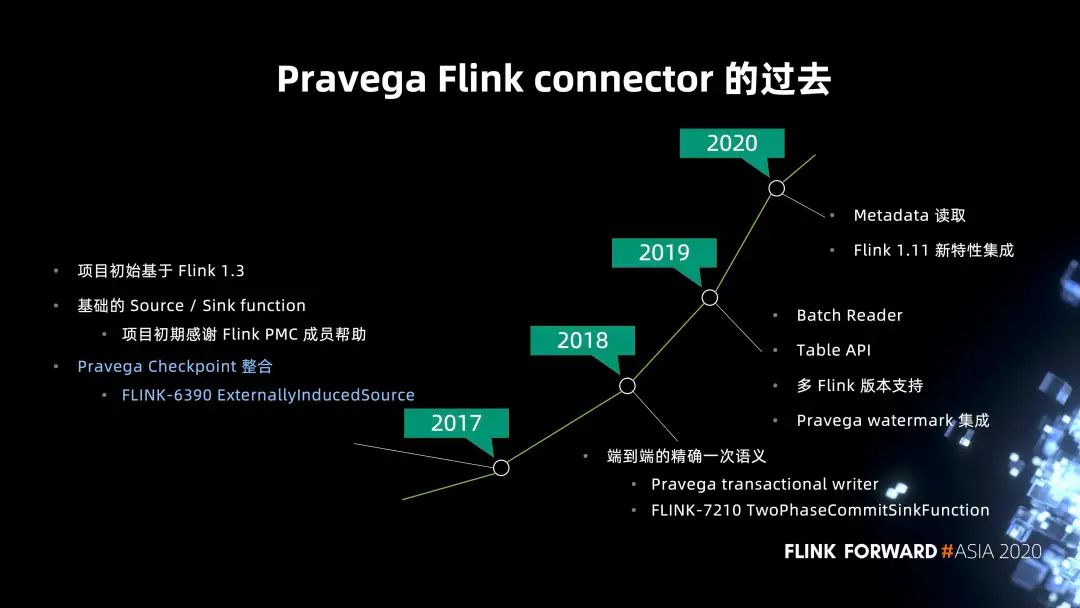
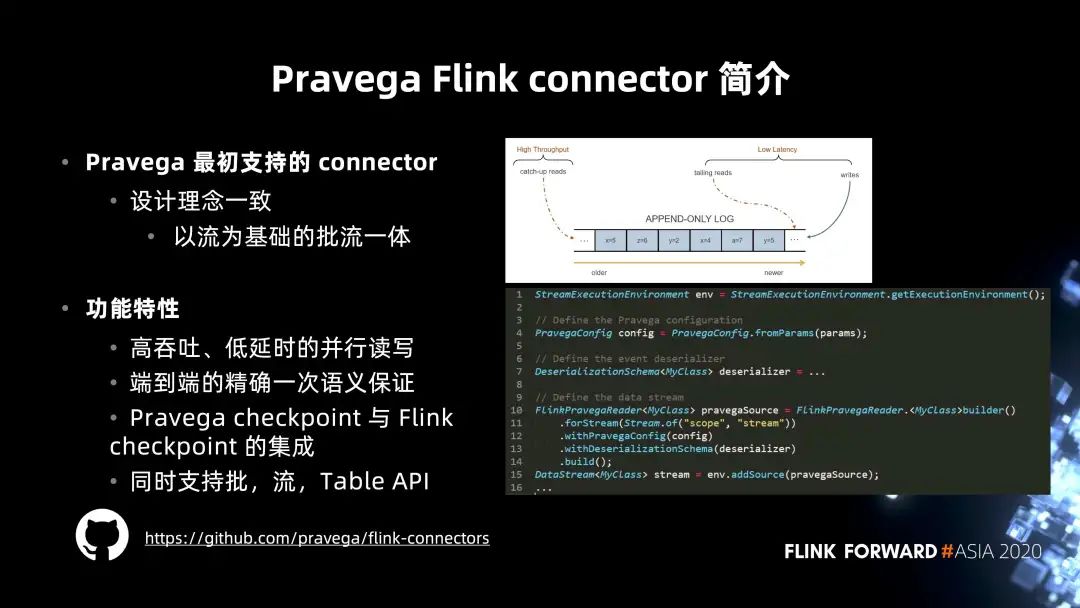
connector 从 2017 年开始成为独立的 Github 项目。2017 年,我们基于 Flink 1.3 版本进行开发,当时有包括 Stephan Ewen 在内的 Flink PMC 成员加入,合作构建了最基础的 Source / Sink function,支持最基础的读写,同时也包括 Pravega Checkpoint 的集成,这点会在后面进行介绍。 2018 年最重要的一个亮点功能就是端到端的精确一次性语义支持。当时团队和 Flink 社区有非常多的讨论,Pravega 首先支持了事务性写客户端的特性,社区在此基础上合作,以 Sink function 为基础,通过一套两阶段提交的语义实现了基于 checkpoint 的分布式事务功能。后来,Flink 也进一步抽象出了两阶段提交的 API,也就是为大家熟知的 TwoPhaseCommitSinkFunction 接口,并且也被 Kafka connector 采用。社区有博客来专门介绍这一接口,以及端到端的一次性语义。 2019 年更多的是 connector 对其它 API 的一些补完,包括对批的读取以及 Table API 都有了支持。 2020 年的主要关注点是对 Flink 1.11 的集成,其中的重点是 FLIP-27 以及 FLIP-95 的新特性集成。
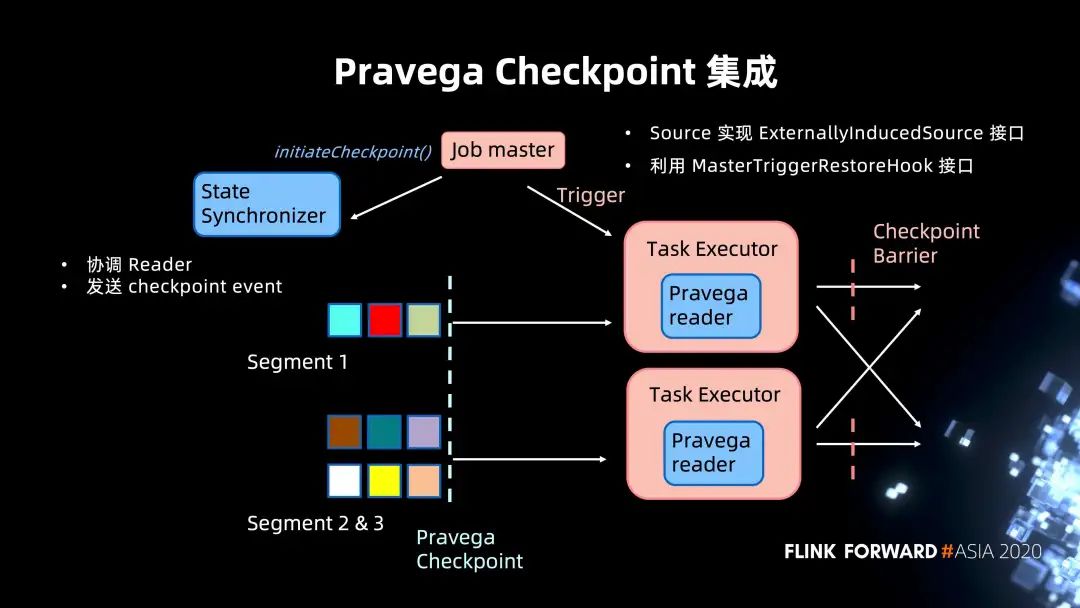
2. Checkpoint 集成实现
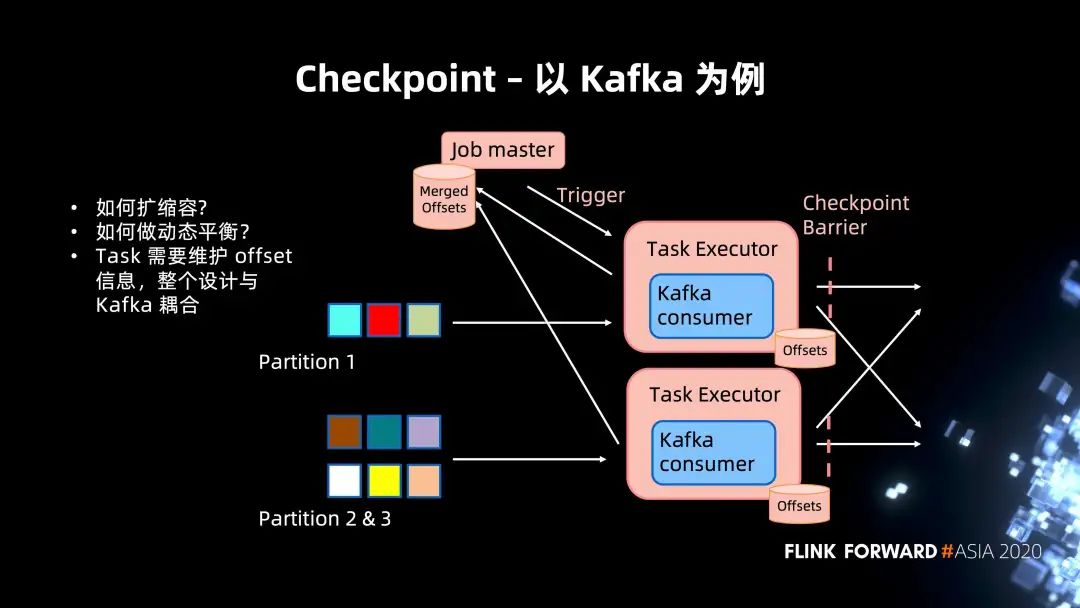
扩缩容以及动态的平衡支持。当 Partition 进行调整的时候,或者说对 Pravega 而言,在 Partition 动态扩容和缩容的时候,如何进行 Merge 一致性的保证。 还有一点就是 Task 需要维护一个 offset 的信息,整个设计会与 Kafka 的内部抽象 offset 耦合。
三、回顾 Flink 1.11 高阶特性心得分享
1. FLIP-95 集成

■ 1.1 Pravega 旧的 Table API

以 update mode 和 append 去进行区分批和流,而且批流的数据这样的区分并不直观。 配置件也非常的冗长和复杂,读取的 Stream 需要通过 connector.reader.stream-info.0 这样非常长的配置键来配置。 在代码层面,和 DataStream API 也有非常多的耦合难以维护。

■ 1.2 Pravega 全新 Table API

2. Flink-18641 解决过程心得分享

首先会自己去逐步断点调试,通过查看 error 的报错日志,分析相关的 Pravega 以及 Flink 的源码,确定它是 Flink CheckpointCoordinator 相关的一些问题; 然后我们也查看了社区的一些提交记录,发现 Flink 1.10 之后, CheckpointCoordinator 线程模型,由原来锁控制的模型变成了 Mailbox 模型。这个模型导致了我们原来同步串型化执行的一些逻辑,错误的被并行化运行了,于是导致该错误; 进一步看了这一个改动的 pull request,也通过邮件和相关的一些 Committer 取得了联系。最后在 dev 邮件列表上确认问题,并且开了这个 JIRA ticket。
在邮件列表和 JIRA 中搜索是否有其他人已经提出了类似问题; 完整的描述问题,提供详细的版本信息,报错日志和重现步骤; 得到社区成员反馈之后,可以进一步会议沟通商讨解决方案; 在非中文环境需要使用英语。
四、未来展望
在未来比较大的工作就是 Pravega schema registry 集成。Pravega schema registry 提供了对 Pravega stream 的元数据的管理,包括数据 schema 以及序列化方式,并进行存储。这个功能伴随着 Pravega 0.8 版本发布了该项目的第一个开源版本。我们将在之后的 0.10 版本中基于这一项目实现 Pravega 的Catalog,使得 Flink table API 的使用更加简单; 其次,我们也时刻关注 Flink 社区的新动向,对于社区的新版本、新功能也会积极集成,目前的计划包括 FLIP-143 和 FLIP-129; 社区也在逐步完成基于 docker 容器的新的 Test Framework 的转换,我们也在关注并进行集成。
 戳我,查看原文视频~
戳我,查看原文视频~评论