
用超分辨率扛把子算法 ESRGAN,训练图像增强模型
By 超神经
内容一览:通过硬件或软件方法,提高原有图像的分辨率,让模糊图像秒变清晰,就是超分辨率。随着深度学习技术的发展,图像超分辨率技术在游戏、电影、医疗影像等领域的应用,也愈发广泛。
关键词:超分辨率 机器视觉 深度学习
将图像或影片从低分辨率转化为高分辨率,恢复或补足丢失的细节(即高频信息),往往需要用到超分辨率技术。
根据所用低分辨率图像的数量,超分辨率技术可分为单幅图像的超分辨率 (SISR) 和多幅图像的超分辨率 (MISR)。

网友用 AI 技术给视频上色、插帧
恢复了 1920 年北京市民生活记录影像
SISR 利用一张低分辨率图像,达到图像尺寸增大或像素的增加的效果,从而获得一张高分辨率图像。
MISR 则是借助同一场景中的多张低分辨率图像,获取不同细节信息,合成一张或多张高分辨率图像。MISR 的输出既可以是单幅图像,也可以是一个图像系列(即视频)。
超分辨率 3 大法宝:插值、重建、学习
图像超分辨率方法可以分为 3 种:基于插值、 基于重建和基于学习的方法。
方法 1:基于插值
插值法是指在放大图像后的空缺点上,填补相应的像素值,从而恢复图像内容,达到提高图像分辨率的效果。
常用的插值法包括:最近邻插值、线性插值、双线性插值和双三次插值。
最近邻插值法
最近邻插值法实现起来最简单粗暴,运算量也最小,只需要直接复制最近像素点的像素值进行填补即可,但是照搬旁边的像素最显著的特点就是效果差、块效应明显。
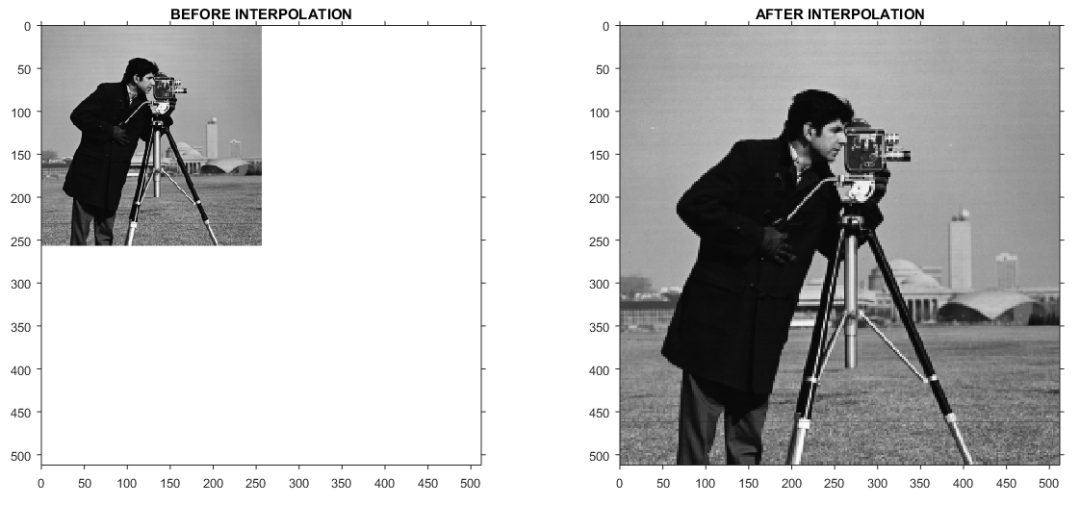
将左图进行最近邻插值后
得到的右图产生了明显可见的锯齿或马赛克现象
线性插值
线性插值 (Linear Interpolation) 是在一个方向上进行插值,只针对一维数据,其方程式是一个一元多项式,也就是说只有一个变量。
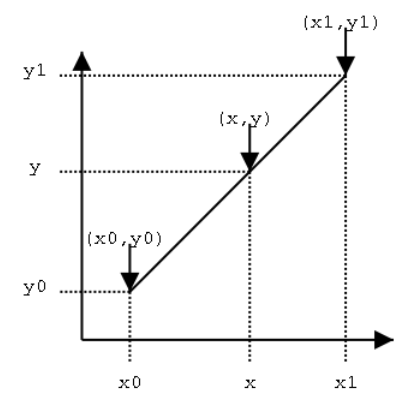
线性插值原理示意图
已知坐标 (x0,y0) 和 (x1,y1),
x 为 x0 和 x1 之间的一个已知值,求解 y
双线性插值
双线性插值 (Bilinear Interpolation) 与针对一维数据的线性插值方法类似,区别是双线性插值拓展到了二维图像,需要在 X 和 Y 两个方向上进行插值。
双线性插值的运算过程比最近邻插值稍稍复杂一些,但是效果更光滑,这也导致插值后图像的部分细节看起来比较模糊。
双三次插值
双三次插值 (Bicubic Interpolation) 同理,用于三个变量的函数插值。双三次插值法更为复杂,它输出的图像边缘比双线性插值更为平滑和精确,但是运算速度也最慢。
方法 2:基于重建
基于重建的超分辨率复原方法是指将多张同一场景的低分辨率图像,在空间上进行亚像素精度对齐, 得到高低分辨率图像彼此之间的运动偏移量, 构建观测模型中的空间运动参数,从而得到一幅高分辨率图像的过程。
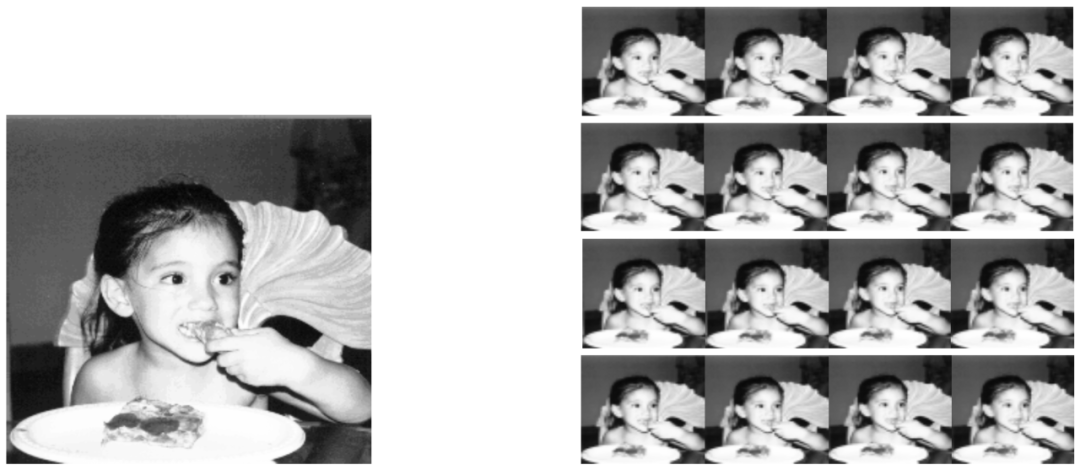
原始高分辨率图像(左)
与经过亚像素位移后得到的图像序列(右)
基于重建的超分辨率方法的核心思想,就是用时间带宽(获取同一场景的多帧图像序列),换取空间分辨率,实现时间分辨率向空间分辨率的转换。
目前超分辨率重建方法可分为两大类:频域法和空域法。
频域法在频域内解决图像内插问题,其观察模型是基于傅里叶变换的移位特性,它灵论简单、运算复杂度低,容易实现并行处理。
空域法的线性空域观测模型则涉及全局和局部运动、光学模糊、帧内运动模糊等,其典型方法包括非均匀插值法、迭代反投影法、最大后验概率法(目前实际应用和科学研究中运用最多的一种方法)、凸集投影法。
方法 3:基于学习
基于学习的超分辨率方法,是指通过神经网络,直接学习低分辨率图像到高分辨率图像的端到端的映射函数,利用模型习得的先验知识,获取图像的高频细节,从而获得较好的图像恢复效果。
基于浅层学习的算法步骤包括:特征提取–>学习–>重建,主流方法包括:基于样例 (Example-based) 法、邻域嵌入方法、支持向量回归方法、稀疏表示法等。
其中基于样例法是首个基于学习的单图像超分辨率算法,由 Freeman 首次提出。它利用机器学习训练数据集,习得低分辨率和高分辨率之间的关系,进而实现超分辨重建。
基于深度学习的算法步骤包括:特征提取–>非线性映射–>图像重建
基于深度学习的图像超分辨率重建方法包括 SRCNN、FSRCNN、ESPCN、VDSR、SRGAN、ESRGAN 等,此处重点介绍 SRCNN、SRGAN、ESRGAN 三种算法。
SRCNN
SRCNN 是将深度学习用于超分辨率重建的开山之作,它的网络结构非常简单,只包括 3 个卷积层。
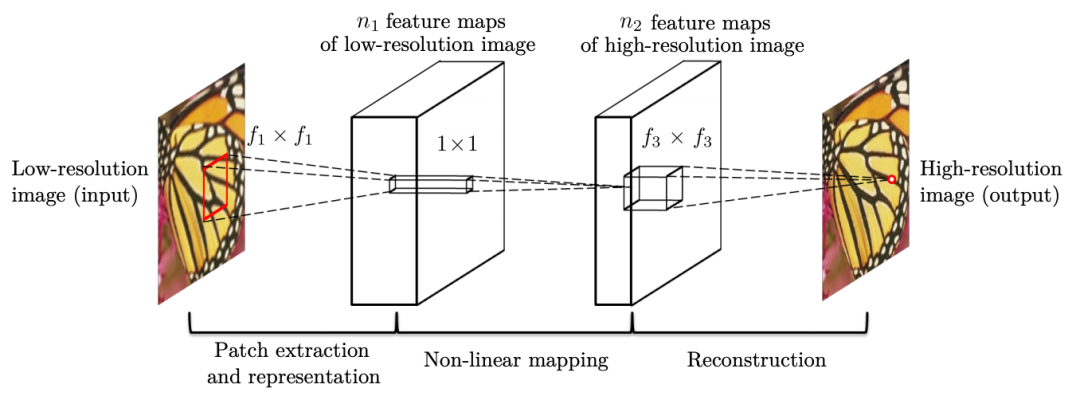
SRCNN 的网络结构
三个算法步骤分别为:特征提取、非线性映射、图像重建
实现方法很精炼:输入低分辨率图像,用双三次插值法将图像放大至目标尺寸,然后用三层卷积神经网络拟合低分辨率图像跟高分辨率图像之间的非线性映射,最后输出重建后的高分辨率图像。
优点:
网络结构简单(仅使用 3 个卷积层);框架在选择参数时很灵活,支持自定义。
缺点:
仅针对单个尺度因子进行训练,一旦数据量发生变化,则必须重新训练模型;仅使用一层卷积层进行特征提取,比较局限,细节提现不充分;当图像放大倍数超过 4 时,得到的结果过于平滑、不真实。
SRGAN
SRGAN 是首个支持图像放大 4 倍仍能保持真实感的框架,科研人员提出了感知损失函数 (perceptual loss function) 的概念,它包括一个对抗损失 (adversarial loss) 和一个内容损失 (content loss)。
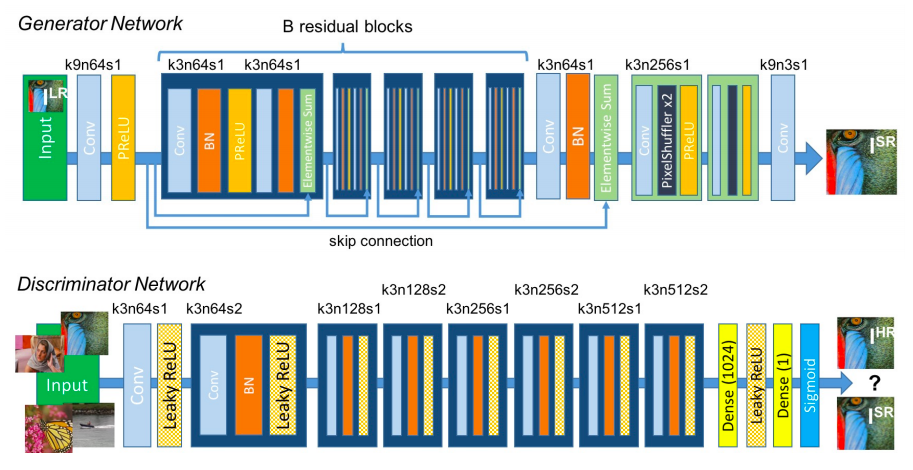
SRGAN 中生成器和判别器的网络结构
所有卷积层都有对应的卷积核尺寸 k、特征图数量 n 及步长 s
对抗损失用判别器网络来判断输出图像跟原始图像的真实性差异;内容损失也是由感知相似性驱动的,而非像素空间相似性。
感知损失函数的引入,使得 SRGAN 在进行图像超分辨率重建时,能够针对单幅图像,生成真实纹理,补充损失的细节。
ESRGAN
ESRGAN 在 SRGAN 的基础上,进一步改进了网络结构、对抗损失和感知损失,增强了超分辨率处理的图像质量。模型改进包括以下三个方面:
1 引入容量更大、更易于训练的 Residual-in- Residual Dense Block (RRDB) 来改善网络结构,删除 BN (Batch Normalization) 层,用 residual scaling 和 smaller initialization 来改善深度网络的训练;
2 用 RaGAN 改进判别器,预测高分辨率图像跟原始图像之间的相对真实性而不是绝对值,从而使得生成器恢复原始图像更真实的纹理细节;
3 改进感知损失,把先前 SRGAN 中激活后的 VGG features 改为激活前执行,提高输出图像的边缘清晰度和纹理真实性。

与其他方法相比,ESRGAN 输出的建筑物图像(右下)
具有更多的自然纹理、细节效果更佳
与 SRGAN 相比,ESRGAN 输出的图像画质更佳,且具有更真实和自然的纹理,并在 PIRM2018-SR 挑战赛中荣登榜首,代码见 github.com/xinntao/ESRGAN。
教程详解:用 ESRGAN 进行图像增强
本教程将演示如何在 TensorFlow Hub 中 用 ESRGAN 算法,进行图像增强。ESRGAN 的输出结果如下图所示:

超分辨率重建后,原图(左)与 ESRGAN 输出结果(右)对比图
ESRGAN 在清晰度和细节处理方面表现优异
快速上手 ESRGAN
开源协议:Apache License 2.0
安装环境:Python 3.6,TensorFlow 2.3.1
使用说明:该模型使用 DIV2K 数据集(双三次降采样的图像)中,大小为 128 x 128 的图像快进行训练
注意事项:运行教程请使用「使用ESRGAN进行图像超分辨率重建.ipynb」,按顺序运行 cell 即可;目录中 model 文件夹下为模型文件,esrgan-tf2_1.tar.gz 文件为模型压缩包(本教程运行中未使用压缩包)
完整教程传送门:
https://openbayes.com/console/openbayes/containers/EsAbdwfM6YN
准备环境

定义辅助函数

对从路径加载的图像执行超解析
并排比较输出大小

完整教程传送门:
https://openbayes.com/console/openbayes/containers/EsAbdwfM6YN
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮
,告诉大家你也在看

评论