
一次“不负责任”的 K8s 网络故障排查经验分享

转自公众号:尔达 Erda
某天晚上,客户碰到了这样的问题:K8s 集群一直扩容失败,所有节点都无法正常加入集群。在经过多番折腾无解后,客户将问题反馈到我们这里,希望得到技术支持。该问题的整个排查过程比较有意思,本文对其中的排查思路及所用的方法进行了归纳整理并分享给大家,希望能够对大家在排查此类问题时有些帮助和参考。
问题现象
运维同学在对客户的 K8s 集群进行节点扩容时,发现新增的节点一直添加失败。初步排查结果如下:
在新增节点上,访问 K8s master service vip 网络不通。
在新增节点上,直接访问 K8s master hostIP + 6443 网络正常。
在新增节点上,访问其他节点的容器 IP 可以正常 ping 通。
在新增节点上,访问 coredns service vip 网络正常。
该客户使用的 Kubernetes 版本是 1.13.10,宿主机的内核版本是 4.18(centos 8.2)。
问题排查过程
收到该一线同事的反馈,我们已经初步怀疑是 ipvs 的问题。根据以往网络问题排查的经验,我们先对现场做了些常规排查:
确认内核模块 ip_tables 是否加载(正常)
确认 iptable forward 是否默认 accpet (正常)
确认宿主机网络是否正常(正常)
确认容器网络是否正常(正常)
...
排除了常规问题后,基本可以缩小范围,下面我们再继续基于 ipvs 相关层面进行排查。
通过 ipvsadm 命令排查
10.96.0.1 是客户集群 K8s master service vip。
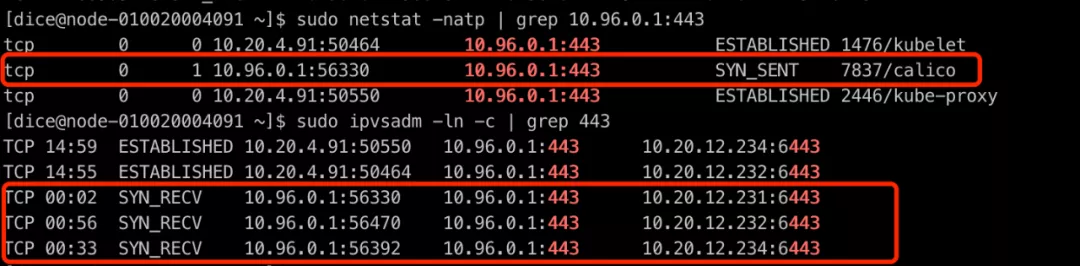
如上图所示,我们可以发现存在异常连接,处于 SYN_RECV 的状态,并且可以观察到,启动时 kubelet + kube-proxy 是有正常建连的,说明是在启动之后,K8s service 网络出现了异常。
tcpdump 抓包分析
两端进行抓包,并通过 telnet 10.96.0.1 443 命令进行确认。
结论:发现 SYN 包在本机没有发送出去。
初步总结
通过上述操作,我们初步总结:问题基本就在 kube-proxy 身上。我们采用了 ipvs 模式,也依赖了 iptables 配置实现一些网络的转发、snat、drop 等。
根据以上排查过程,我们再次缩小了范围,开始分析怀疑对象 kube-proxy。
查看 kube-proxy 日志
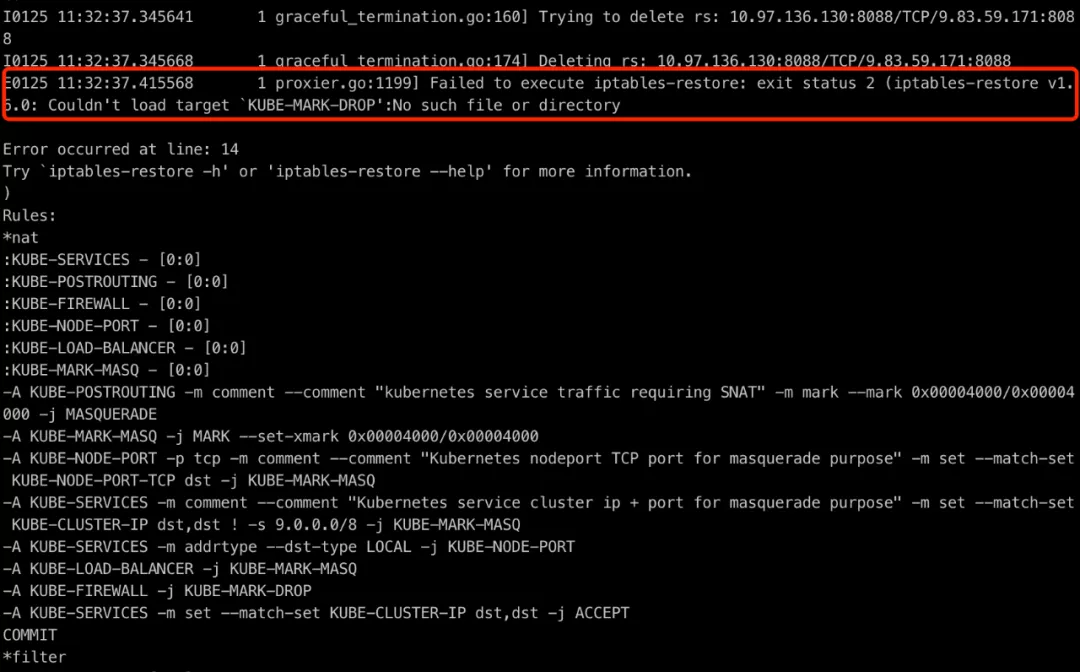
如上图所示:发现异常日志,iptables-restore 命令执行异常。通过 Google、社区查看,确认问题。
相关 issue 链接可参考:
https://github.com/kubernetes/kubernetes/issues/73360
https://github.com/kubernetes/kubernetes/pull/84422/files
https://github.com/kubernetes/kubernetes/pull/82214/files
继续深入
通过代码查看(1.13.10 版本 pkg/proxy/ipvs/proxier.go:1427),可以发现该版本确实没有判断 KUBE-MARK-DROP 是否存在并创建的逻辑。当出现该链不存在时,会出现逻辑缺陷,导致 iptable 命令执行失败。
K8s master service vip 不通,实际容器相关的 ip 是通的,这种情况出现的原因,与下面的 iptable 规则有关:
$ iptables -t nat -A KUBE-SERVICES ! -s 9.0.0.0/8 -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ
根因探究
前面我们已经知道了 kube-proxy 1.13.10 版本存在缺陷,在没有创建 KUBE-MARK-DROP 链的情况下,执行 iptables-restore 命令配置规则。但是为什么 K8s 1.13.10 版本跑在 centos8.2 4.18 内核的操作系统上会报错,跑在 centos7.6 3.10 内核的操作系统上却正常呢?
我们查看下 kube-proxy 的源码,可以发现 kube-proxy 其实也就是执行 iptables 命令进行规则配置。那既然 kube-proxy 报错 iptables-restore 命令失败,我们就找一台 4.18 内核的机器,进入 kube-proxy 容器看下情况。
到容器内执行下 iptables-save 命令,可以发现 kube-proxy 容器内确实没有创建 KUBE-MARK-DROP 链(符合代码预期)。继续在宿主机上执行下 iptables-save 命令,却发现存在 KUBE-MARK-DROP 链。
这里有两个疑问:
为什么 4.18 内核宿主机的 iptables 有 KUBE-MARK-DROP 链?
为什么 4.18 内核宿主机的 iptables 规则和 kube-proxy 容器内的规则不一致?
第一个疑惑,凭感觉怀疑除了 kube-proxy,还会有别的程序在操作 iptables,继续撸下 K8s 代码。
>>> 结论:发现确实除了 kube-proxy,还有 kubelet 也会修改 iptables 规则。
具体代码可以查看:pkg/kubelet/kubelet_network_linux.go
第二个疑惑,继续凭感觉······Google 一发捞一下为何 kube-proxy 容器挂载了宿主机 /run/xtables.lock 文件的情况下,宿主机和容器 iptables 查看的规则不一致。
>>> 结论:CentOS 8 在网络方面摒弃 iptables,采用 nftables 框架作为默认的网络包过滤工具。
至此,所有的谜团都解开了。
团队完成过大量的客户项目交付,这里有些问题可以再解答下:
问题一:为什么这么多客户环境第一次碰到该情况?
因为需要 K8s 1.13.10 + centos 8.2 的操作系统,这个组合罕见,且问题必现。升级 K8s 1.16.0+ 就不出现该问题。
问题二:为什么使用 K8s 1.13.10 + 5.5 内核却没有该问题?
因为与 centos 8 操作系统有关,我们手动升级 5.5 版本后,默认还是使用的 iptables 框架。
可以通过 iptables -v 命令,来确认是否使用 nftables。

题外话:nftables 是何方神圣?比 iptables 好么?这是另一个值得进一步学习的点,这里就不再深入了。
总结与感悟
针对以上的排查问题,我们总结下解决方法:
调整内核版本到 3.10(centos 7.6+),或者手动升级内核版本到 5.0 +。
升级 Kubernetes 版本,确认 1.16.10+ 版本没有该问题。
以上是我们在进行 Kubernetes 网络故障排查中的一点经验,希望能够对大家高效排查,定位原因有所帮助。


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
