
发际线有救了!这款app可一键AI生发,拯救你的自拍焦虑
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

比起卡粉,闷痘,油光,手残,新一代年轻人的美丽可以来得更容易,快速变美只需要两步,打开美图,摆好pose——诠释那句话,“为了美丽,我坚持开美颜”。
今年来,容貌焦虑和发际线危机已经不止一次搬上话事桌,甚至让大众误以为这并非为资本或是人的思维创造物。实际上,这是一个由意识形态到符号结构再到技术决定的逻辑蜕变过程,美图公司在后排默默观察。
去年9月,美图秀秀推出增发功能,可填充发际线、增加刘海 。

今年2月,美图秀秀发布《00后图片社交报告》,报告显示,当00后被问及“最在意的修图部位”,出乎意料的是00后用户不仅关注腹肌、锁骨和黑眼圈这些细节,也关注发际线的完美程度。

其背后的美图影像实验室(MT Lab),目前已经落地了多个头发生成项目,在美图旗下核心产品美图秀秀及海外产品AirBrush上线刘海生成、发际线调整与稀疏区域补发等功能。

其中,刘海生成功能可以基于自定义的生成区域,生成不同样式的刘海;
发际线调整功能在保持原有发际线样式的情况下,可以对发际线的不同高度进行调整;
稀疏区域补发则可以在指定区域或者智能检测区域中,自定义调整稀疏区域的头发浓密程度。
成立于2010年的MT Lab是致力于计算机视觉、机器学习、增强现实、云计算等人工智能相关领域的研发团队,深耕人脸、美颜、美妆、人体、图像分割、图像生成等多个技术研发领域,目前已广泛应用于美图旗下产品。

美图秀秀的人像美容栏中的外貌修饰功能
如今,美图秀秀不仅在人脸上做“减法’,还做起了“加法”,推出面部丰盈、整牙以及发际线调整、稀疏区域补发的新功能。

美图秀秀的整牙和面部填充对比图
但怎么解决当下大家最关注的头发生成问题,在落地过程中仍面临几个亟待突破的关键技术瓶颈:数据缺少、发丝细节不足和清晰度低。稍有不慎,头发就容易糊成一片。

当年Angel大宝贝在电视剧中的抠图效果可太假了
首先是生成数据的获取问题
以刘海生成任务为例,在生成出特定款式的刘海时,需要大量刘海数据,但是通过搜集真实数据的形式做数据喂养,其实就是个“体力活”:有刘海、无刘海的真实数据难获取;斜刘海、直刘海、八字刘海等特定款式的刘海数据耗费高成本。
这两种方式基本都不具备可操作性。

其次是高清图像细节的生成问题
要么头发太假,要么像是用座机拍出来的糊图。
由于头发部位拥有复杂的纹理细节,通过CNN难以生成真实且达到理想状态的发丝。
其中,在有配对数据的情况下,虽然可以通过设计类似Pixel2PixelHD、U2-Net等网络进行监督学习,但目前通过该方式生成的图像清晰度仍然非常有限。
而在非配对数据情况下,一般通过类似HiSD、StarGAN、CycleGAN的方式进行属性转换生成,利用该方式生成的图片不仅清晰度不佳,还存在目标效果生成不稳定、生成效果不真实等问题。
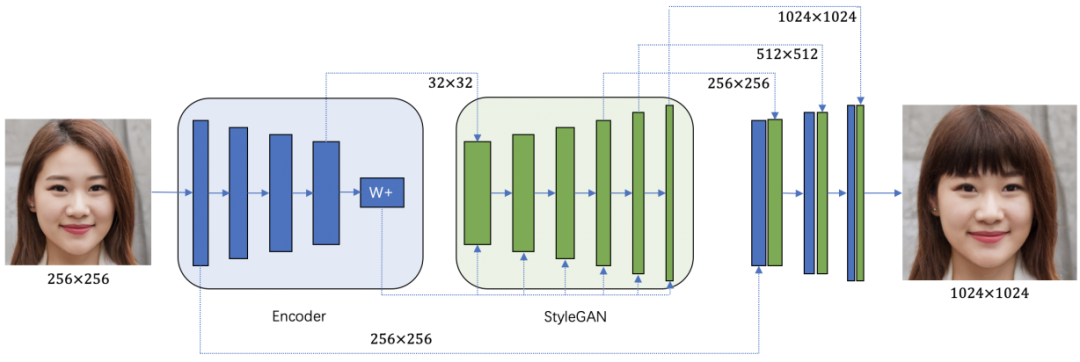
真实的头发数据没有,自己造“假”又太假,针对上述情况, MT Lab基于庞大的数据资源与突出的模型设计能力,借助StyleGAN解决了头发生成任务所面临的配对数据生成与高清图像细节两大核心问题。
StyleGAN作为当前生成领域的主要方向(Gan生成式对抗网络),是一种基于风格输入的无监督高清图像生成模型。能够基于7万张1024*1024的高清人脸图像训练数据FFHQ,通过精巧的网络设计与训练技巧生成清晰逼真的图像效果。

基于StyleGAN生成的图片
此外,StyleGAN还能基于风格输入的方式拥有属性编辑的能力,通过隐变量的编辑,实现图像语意内容的修改。
具体有三步:配对数据生成(生发)——配对数据增益(控制发量)——image-to-image生成(高清)。
1.配对数据生成
StyleGAN生成配对数据最为直接的方式就是在w+空间直接进行相关属性的隐向量编辑,生成相关属性。其中隐向量编辑方法包括GanSpace、InterFaceGAN以及StyleSpace等等。
但这种图像生成方式通常隐含着属性向量不解耦的情况,即在生成目标属性的同时往往伴随其他属性(背景和人脸信息等)产生变化。
因此,MT Lab结合StyleGAN Projector、PULSE及Mask-Guided Discovery等迭代重建方式来解决生成头发配对数据的问题。该方案的主要思路是通过简略编辑原始图片,获得一张粗简的目标属性参考图像,将其与原始图像都作为参考图像,再通过StyleGAN进行迭代重建。
以为头发染浅色发色为例,需要先对原始图片中的头发区域染上统一的浅色色块,经由降采样获得粗略编辑简图作为目标属性参考图像,在StyleGAN的迭代重建过程中,生成图片在高分辨率尺度下与原始图片进行相似性监督,以保证头发区域以外的原始信息不发生改变。
另一方面,生成图片通过降采样与目标属性参考图像进行监督,以保生成的浅色发色区域与原始图片的头发区域一致,二者迭代在监督平衡下生成期望中的图像,与此同时也获得了一个人有无浅色头发的配对数据。
值得强调的是,在该方案执行过程中既要保证生成图片的目标属性与参考图像一致,也要保证生成图像在目标属性区域外与原始图片信息保持一致;还需要保证生成图像的隐向量处于StyleGAN的隐向量分布中,才能够确保最终的生成图像是高清图像。
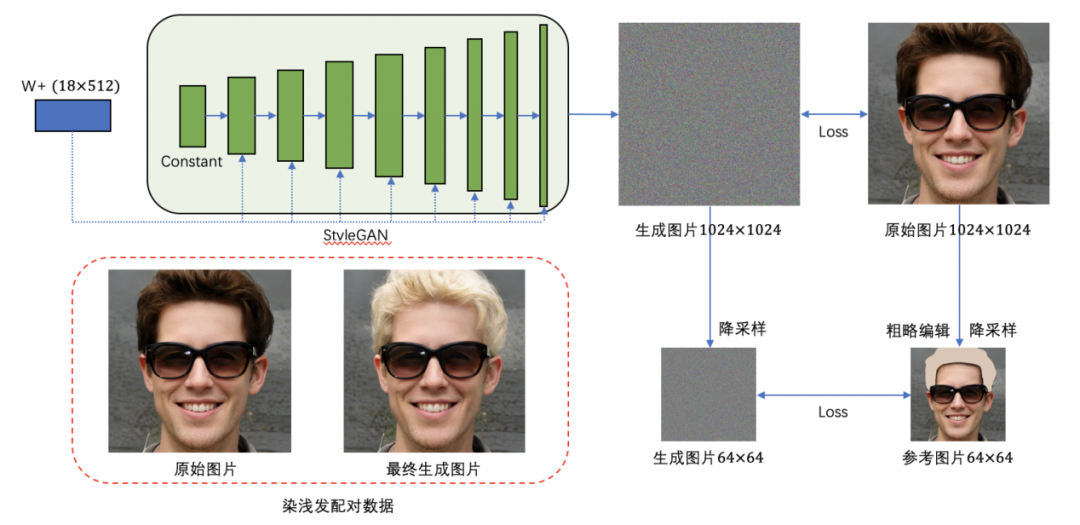
染浅色头发 StyleGAN 迭代重建示意图
此外,基于该方案的思路,在头发生成领域还可以获取到发际线调整的配对数据、刘海生成的配对数据以及头发蓬松的配对数据。
但是想用补发功能,前提得还没毛光光。不然基于头发原本颜色的补色,系统一律按肤色计算了。

不同肤色做出来的发色不一致(左图为冲浪达人阿怡视频中的网红爷爷)
2.配对数据增益
基于迭代重建,还能够获得配对数据所对应的StyleGAN隐向量,通过隐向量插值的方式还能实现数据增益,进而获得足够数量的配对数据。
以发际线调整的配对数据为例,在每一组配对数据间,可以通过插值获得发际线不同程度调整的配对数据。同样的,两组配对数据间也可以通过隐向量插值获得更多配对数据。
此外,通过插值获得的配对数据也能够生成新的配对数据,基于此可以满足对理想的发际线调整配对数据的需求。



点个在看 paper不断!