
准确识别技术债务才是改造遗留系统的破解之道丨IDCF

来源:InfoQ作者:白嗣健,华为 云化平台技术专家,软件特战队队长,华为人报战斗在 0 与 1 的世界作者,管理千万级代码规模行平台产品。编辑:支小亚
今天来聊聊大规模的遗留系统。大厂的遗留系统一般会呈现什么样的特点呢?第一是存量代码规模特别大,其次是技术栈特别全,最后是架构的演进时间长,10 年至 20 年的祖传遗留系统非常常见。

祖传代码
遗留系统的架构通常如上图所示:它可以完整运行,整个系统功能也比较稳定。然而由于技术栈过时造成演进性不足,文档过时或丢失导致与真实的系统脱节,当初的设计者可能已经离开公司,或者升迁到管理层,轻易的改动带来的连锁反应很容易导致整个系统的不稳定。面对这样的遗留系统一般人都会比较谨慎,技术人员更愿意重写而不是做遗留系统的改造。
但从成本上来看改造比推倒重来短期成本要高(分析问题,制定策略),长期成本要低得多(变化及规格丢失导致客户投诉)。考虑到风险成本,我更愿意去做遗留系统的改造而非重构。重写过程中面临需求的双重交付压力,文档缺失规格很容易丢失,在测试阶段仅仅补齐规格就需要很长一段时间,技术人员很容易陷入到技术情结中,重写前承诺的收益往往很难兑现,更换架构和编程语言极易造成团队不稳定,架构师通常会选择他喜欢的语言,程序员通常会选择他擅长的语言,仅仅选择语言就是一门很难的功课,通常 App 开发的选择是 Java、Scala、Go,高性能系统开发选择是 Rust,C++,而胶水类脚本语言开发选择 TS/JS、Python、Lua。
如果你是一个信心满满的架构师,选择了更具挑战的遗留系统改造,动手前你应该知道这个遗留系统有哪些呆账坏账,这些欠账称为技术债务。你不仅要搞清楚都有哪些债务,还要搞清楚欠债的根因是什么。架构与代码代表工程师写的瞬间对架构、代码、业务、环境的认知,随着技术进步,环境变化技术债务就自然产生了,这部分债务属于良性债务,或者说无法避免的债务。另一种债务可能是快速迭代追求商业价值的妥协产物,如果没有重构的投资,或团队缺乏重构的基因,就需要要去改进流程和工具。以我的经验债务的消减需要雷锋,团队文化要求不能让雷锋吃亏。
不同规模遗留系统的特点

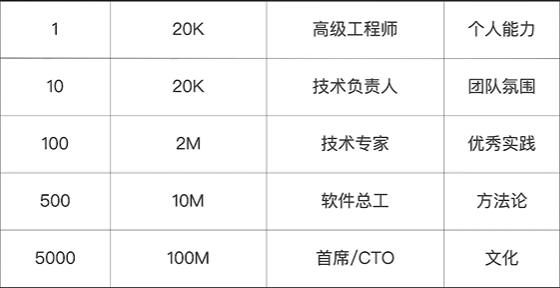
规模系统
管理的规模不同,面临的问题就不一样,面临的问题不一样,所采用的方法就不一样。如果你管理一个代码规模 20K 左右的微服务,相信你通过个人能力很快可以将其改造为最佳状态。如果你是一个技术负责人,管理 10 个微服务约 200K 代码,依靠个人能力很难将其改造为最佳状态。你需要想办法在团队中建立起某个机制,比如每日代码集体检视,它解决了日常的管理、能力提升、review 设计思路,每一个 commit等问题,避免了错误的设计落入版本的尴尬场面。那些在检视中投入度比较高,经常能够给别人提出建设性建议(检视意见)的人就是可以重点培养的下一任的 Tech Lead,相信我,集体检视是小团队最有效的管理方式。
如果你是一个技术专家,管理 100 个微服务大概 200 万行规模的代码。这时你仅靠个人能力和代码检视是不够的 。100 个微服务的团队人数一般是 100+,这样的团队规模需要的是一套优秀的实践体系,从软件的架构设计(建模,设计与实现一致),到需求分解(并行,Tasking),再到代码提交(代码持续集成,小步提交,每日检视),最后是测试方法(TDD,BDD,统一测试框架)。
不过我想重点谈一谈如果管理 500 个微服务,大概千万级代码规模。想要管理这样一个组织,让这些服务都按照你想要的方式去进行演进,就要结合上面提到的所有实践,包括个人的能力、团队的氛围、优秀实践,还要多加上一些方法论的应用。其难点在于不能生搬硬套,要为团队量身打造,通过影响力形成团队共识,制定落地策略,下一篇会举例讲解。
再往上管理 5000 个左右微服务,这样的团队通常可能会跨地域。我并没有真实地管理过这么大规模的项目,所以我没有发言权。
不同规模遗留系统的应对策略
小规模策略

高级工程师
我个人认为高级工程师管理一个微服务只要熟读设计模式,可以熟练地使用,就可以把一个微服务改造得非常好。
微服务的开发,可能连使用复杂设计模式的机会都没有,在云原生的领域里已经把单体应用的架构模块设计通过微服务及基础设施解耦掉了,甚至做到了 Serverless。面向云原生开发你只需要专注于把业务代码写出来就可以。
静态扫描工具可以扫出来烂代码,因为烂代码有规则,写好出好代码是没有固定模式的,现阶段识别好代码最靠得住的方案仍然是人工识别。业界比较好的工具如 Codota,它是一款免费 AI 自动补全编码工具,可以集成在 IDEA 中,输入字符后它会自动帮你联想补全最佳代码片段,还可以片段检索。另外就是读一下 Clean Code、Clean Arch、Effective Code、设计模式等书籍,可以帮助你提升自己的代码品位。

技术负责人
如果管理 10 个服务,怎么样确保让这 10 个服务履行你的架构设计意图呢?我做团队技术负责人的时候坚持每天做代码检视。代码检视是一个非常好的手段,谁的代码是 TDD 的,谁做了重构,谁有想法都是一目了然的。前提是检视会议不能只是领导在讲,开发在开小差的状态,在我看来代码检视是每天的黄金 30 分钟。
代码检视实际上有很多优秀实践,比如检视前要求每位同学检视代码前先自己过一遍,想想怎么讲,要有逻辑,要容易让别人听懂,这样才能缩减检视时间。有时候上午写的代码,到下午就忘了今天上午我为什么这样想这样写。
其次,我们对检视的时间有要求,如果你能坚持每天检视,每天检视时间一般不会超过半个小时。检视的第一步就是把 Commit、Comments 过一下,快速地让别人知道我今天干了什么事情。接着快速地浏览每一行代码,在浏览过程中如果遇到一些常见的问题和共性的问题,我们可以在检视中讲一下。
最后,在检视中我们可以尽早发现设计方面的问题,选用更合适的设计模式。代码已经写完以后才发现设计有问题就晚了,这时技术债务就已经形成了。所以代码检视的过程是学习的过程,也是相互促进的过程。我们在代码检视中经常可以发现一些检视的意见领袖,这些意见领袖在我们团队里面就是我们后备的 Tech Lead。
除了检视,我们在团队中还落地了一些优秀实践,比如 TDD。如何落地 TDD?我们要求在新的需求中最好可以用 TDD 的方式,这个是 nice-to-have,并不是 need-to-have,所以在检视中如果谁用了 TDD 的方式,我们会给予他鼓励。
这两年通过微服务火起来的 DDD 炙手可热,今年我们也搞了一些 DDD 的实践——Event-Storming 建模、基于 DDD 的微服务实战项目。DDD 是一个概念,一套理论,如何让大家在实践中把 DDD 落到项目中需要有一个 DDD Demo Project,有先锋团队愿意去尝试,我认为这是团队氛围好的体现。
百万级代码规模策略

技术专家
如果你是一个管理 100 个微服务的技术专家,想要管理这么大的团队,你要做到前面提到的所有实践,实践是累加的过程,理论上来讲你无法跳过小团队管理经验直接到首席架构师。有一些团队的 Tech Lead 并不认可 TDD,不认可 DDD,这是很正常。在我们团队中会尊重不同的 Tech Lead 的选择,永远拒绝一刀切。
除此之外,我认为管理这么多微服务比较重要的是 Metrics。比如去度量团队的架构债务,代码债务有多少,把债务通过公式转换成时间,这样就得到 A 团队的技术债务是 30 分钟,B 团队的技术债务是 3 天。大概有一个 Metrics 的 Dashboard,我们就可以看到它每天的债务是增长的还是燃尽的,如果数据的维度比较多,那么就需要通过一个成熟度评估,比如 Level3,或 3 star 团队。
另外一个是 Backlog,Backlog 并不是一个 list 来记需要干的事情,我们通常会给团队投资一个 Backlog 去做重构或写测试。如果你要求一个团队或者一个工程师写完代码以后必须要带测试,写完代码以后必须要重构,一般来说他不会去做,因为这对他来说没有收益。我认为重构、写测试也是编码,也属于产出,所以要给团队一个 Backlog,给团队一定的比例去做重构和开发者测试。开发者测试包括了 UT、FT、AT 等等,还包括一些性能测试、集成测试。
10 年前,我第一次体验敏捷,那时我还觉得敏捷是一种管理手段。后来我接触了一些极限编程的工程实践和一些优秀的人,和这些人一起工作 1 年后,最终使我认可敏捷。像我司这样的双模 IT 企业比较少,所谓双模就是 IT 加 CT,我的感受是 IT 领域更适合遵循计划,CT 领域更适合响应变化。
给大家讲一个故事,我有一个做硬件的朋友,他每个季度都要出一趟差把他们的设计送到车间去生产出来一批样机。他每次都非常担心,如果样机出现任何设计问题他的麻烦就大了。像这样的开发模式必须充分设计、充分验证,充分测试,才能上线。
CT 领域就更适合敏捷了,尤其是互联网。我也曾在互联网工作过,互联网的诉求是要快速地试错,允许灰度发布。反馈好就加大投资,反馈平平就下线。因此软件领域更适合微服务,更适合敏捷。
其次就是 CI/CD、DevOps,很多团队有 CI/CD 流水线,他可以给你展示——看我们的流水线是这样跑的,但是点进去一看就会发现有很多问题。比如说微服务什么时候拆?很多人可能会说我们在建模时候就已经拆好了,这是架构师分析来的。多年的工作经验告诉我微服务并不是拆出来的,而是演进来的。
拆分服务最佳时机我认为是在集成的过程中。一个服务持续集成时间过长会导致团队的整体速率变弱,此时就需要改进了。如果开发人员合一次代码需要 30 分钟以上,如果团队规模是 Two Pizza,那每个人集成一次这需要很长时间,这可能导致无法准时下班。
此时通过一些手段去优化测试、优化集成效率仍然不能满足 30 分钟以下,就可以分析如何拆分服务了,然后相应地根据康威定律的需要把这个团队进行拆分,这是我用来识别什么样的服务应该要被拆分的一种方式。
千万级代码规模策略

软件总工
当你要改造千万级的代码——一般是 2000 万行左右的代码,这种情况团队可能都不在一个地域,如何去管理这么多人、这么多的服务?如果技术没有管控覆盖绝大多数技术栈,那么难度会指数暴增。在这种场景下你身为一个总工也好高级技术专家也好,首先你要构建你的通用编程框架,基础设施,通用的公共组件以及债务的识别能力。
《演进式架构》里面提到了一个非常重要的点叫 Fitness Function,这是用于遗传学的算法。大家想想如果你开了上帝视角,如何确保整个世界根据你的想法进行迭代演进?世界是随机的,我们只能定义一些系统性方程,让适合方程的活下来,淘汰掉不合格的,这就是优胜劣汰。讲到这里,如果你可以写一组方程来落地架构和代码的演进意图,就可以用适应性方程来控制整个大盘。
另外一个是 Clean Architecture,这是 Uncle Bob 的一个方法论(https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html)。我们的架构演进参考了 Clean Architecture,但是我们做了一个变种,更适合我们的 Clean Architecture Plus。
在改造过程中,架构演进难免碰到基础设施不兼容的场景,如何进行架构重构呢?第一步将基础设施比如 MQ、DB、DFS、Cache 等进行了基础设施的抽象,这一层很薄,但是却很重要。第二步是 App 开发依赖新的接口进行开发,这样就做到了应用开发与基础设施的解耦,由于应用不关心基础设施是什么,让我们服务更加 Serverless,在编程过程中也更容易写测试。第三步是基础设施团队根据 API 去实现,在架构重构中难免会出现更换基础设施的情况,对于应用来说不感知,在基础设施实现过程中去做适配,Bazel 是可以按需构建的,整个过程中接口作为了契约,通过契约测试实践进行接口及契约管控,契约测试也根据现状进行了改造,比如使用 git repo 代替 service broker,开发及构建过程通过 git 稀疏检出进行访问,操作麻烦就统一 CLI 工具集,这样基础设施架构和应用架构满足了依赖倒置及权限分离管控。如果你是一个善良的架构师,编程框架 runtime 的统一也必不可少。
落地实践闭坑指南
经常有人抱怨 A 技术不行,B 实践不好,在我脑海里就会浮现出下面这幅图:

卖家秀和买家秀
这是典型的“卖家秀”和“买家秀”。我见过太多团队把敏捷落地成了管理手段,把检视变成了批判大会,与其说没有学到精髓,不如说他们偷换了概念,我的经验是你想学会一个东西,最好最快的方式就是和他们工作过。
敏捷的精髓是什么?我认为敏捷的精髓就是敏捷宣言里面讲的 4 条价值观。在学敏捷的过程中一不小心就会学成买家秀,然后大骂这个理论是有缺陷的!理论是不对的!比如现在很多人在讨论是不是 TDD 已死?是不是设计已死?我仍然认为任何一个东西都有人可以把它玩得非常好,任何一个再好的东西都有人会把它执行得非常地偏,非常地差,以至于整个团队的动作变形。
有很多团队负责人给我讲敏捷就是骗人的,觉得敏捷就是一些流程的动作,敏捷在遗留系统改造中起不到任何作用,仅仅是一些管理的手段。很多人觉得代码检视是一件浪费时间的事情,怎么可以每天做呢?我们把代码提交给 Committer 去 Review 就可以了。这些东西见仁见智,只有你去优秀的团队践行过你才能真正体会到这里面的精髓是什么,你才能把检视做好。
我认为心得体会和经验才更有借鉴价值而非实践本身。优秀实践是如何诞生的呢?大都是把一个实践当做模板,结合团队的认知数据和现状数据,经过无数次迭代,参考会议上大家的改良意见从而形成优秀实践。软件开发之所以无法被 AI 完全替代(20 年内),恰恰因为没有银弹。
总 结
1. 不同规模遗留系统的特点
代码量特别多
技术栈特别全
架构的演进时间比较长
2. 应对策略
小规模——熟读设计模式,熟练地使用、代码检视
百万级代码规模——Metrics、度量团队的架构债务、敏捷
千万级代码规模——统计债务、Clean Code、CleanArchitecture
学到敏捷的精髓
 #IDCF DevOps黑客马拉松挑战赛,独创端到端DevOps体验,精益创业+敏捷开发+DevOps流水线的完美结合。
#IDCF DevOps黑客马拉松挑战赛,独创端到端DevOps体验,精益创业+敏捷开发+DevOps流水线的完美结合。2022年首场将在美丽的海滨城市-大连举办,8月6-7日,36小时内从0到1打造并发布一款产品。
企业组队参赛&个人参赛均可,赶紧上车~👇
