
(附论文)弱光下的人脸准确检测识别
全网搜集目标检测文章,人工筛选最优价值知识,避免垃圾信息轰炸

作为许多人脸相关系统的基石,人脸检测一直吸引着长期的研究关注。

它在以人为中心的重识别,人工分析中有广泛的应用。尽管近十年取得了巨大的进展,但人脸检测仍然具有挑战性,尤其是在恶劣光照条件下的图像。在弱光条件下捕获的图像通常会使其亮度降低,强度对比度被压缩,从而混淆了特征提取,损害了人脸检测的性能。光照差也会引起恼人的噪音,进一步破坏人脸检测的结构信息。更糟糕的是,一张图像中的照明状态可能在空间上变化很大。为了对不利光照条件下的人脸检测算法进行系统评估,最近构建了一个具有挑战性的基准-DARK FACE,它显示了最先进的人脸检测器有明显的性能下降。例如,DSFD产生的mAP为15.3%,与流行的WIDER FACE基准测试的90%以上形成鲜明对比。DARK FACE数据集上的人脸探测器的显著性能退化清楚地表明,在弱光条件下检测人脸仍然极具挑战性,这是本此分享的主要重点。
可以通过下图简单了解下检测的效果对比:

然而如上图所示(b-c),还有一个很大的改进空间。由于一个原因,图像增强的目的是提高整个图像的视觉/感知质量,而这与人脸检测的目标并不完全一致。例如,增强有噪声图像的平滑操作可能会破坏对检测至关重要的特征可识别性。这表明增强和检测组件之间的紧密集成,并指出了端到端“增强检测”解决方案。
Low-Light Face Detection
弱光人脸检测一直吸引着长期的研究。在手工制作特征的时代,人们一直在努力理解和解决非均匀照明的问题。近年来,人们对低分辨率图像、低光图像、弱光图像等低质量图像的数据驱动人脸检测的方法越来越感兴趣。光照变化是现代人脸检测算法的一个主要挑战。开创性的方法是通过强度映射来预处理图像,如对数变换和伽马变换。光度归一化是另一种常用的方法,它可以在手工制作的特征和基于深度学习的方法中抵消不同的光照条件。手工制作的基本特征的方法从图像差异或梯度等各种先验得到光照不变性,而基于深度学习的方法使用随机光度作为增强,以隐式地增强光照不变性。
尽管之前有研究,在极其恶劣的光条件下的人脸检测已经被探索中,部分原因是缺乏高质量的标签数据。针对这个问题,有研究者提出了一个大型的人工标记的低光人脸检测数据集——DARK FACE,并表明现有的人脸探测器在任务上表现很差。因此,今天分享的工作是在基准上的激励和评估,并明显优于以前的艺术。基线实验表明,尽管现在取得了显著的成功,但即使只是使用现有的低光增强方法预处理图像,即使是训练良好的人脸检测器也不太理想。
三、新框架及分析

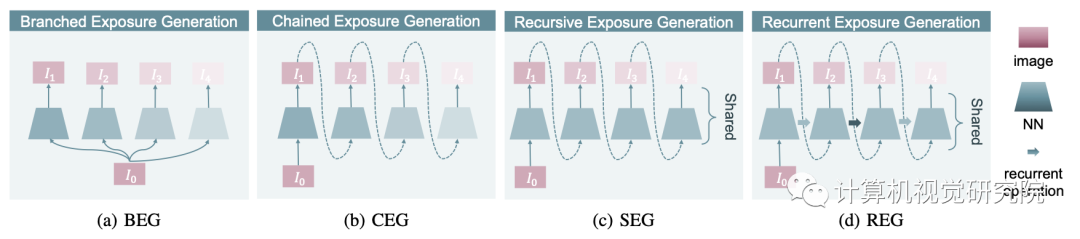
Recurrent Exposure Generation Module
所提出的REG模块利用历史生成的图像来维护递归神经网络(RNN)框架中的关键区域细节。从I和初始隐藏状态H=0开始,REG递归生成递归的T中间伪曝光I,表述为:
其中,Fθ和Gω分别表示该模块的编码器和解码器,并具有对应的参数θ和ω。由四个级联卷积递归层组成的编码器负责将输入图像转换为多个尺度(层)的特征图,而由两个卷积层组成的解码器学习将特征映射解码回图像,如上图所示。
第l层中的REGUFL可用以下方程式来描述:
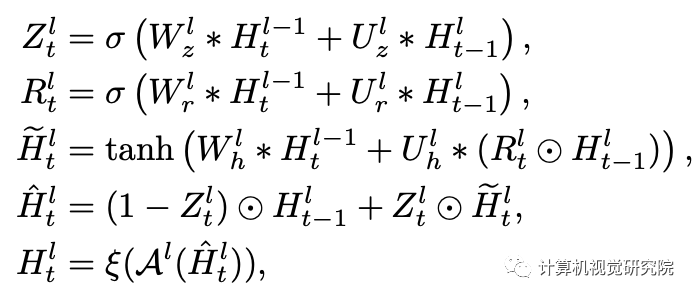
Pseudo-Supervised Pre-Training of the REG Module
研究者采用了[Z. Ying, G. Li, and W. Gao. A Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement. arXiv:1711.00591 [cs]]中提出的相机响应模型,该模型可以描述在没有相机信息可用时像素值和曝光比之间的一般关系。它的BTF是贝伽玛修正的形式:
作为一个端到端系统,REGDet允许在学习期间联合优化REG和MED模块。直观地说,MED提供了面部位置信息来引导REG,以便面部区域可以被特别地增强来进行检测。下图的最右栏显示了一个示例检测结果。结果表明,REGDet成功地定位了更多的中间图像,而不是简单地应用基础检测器定位更多的人脸。

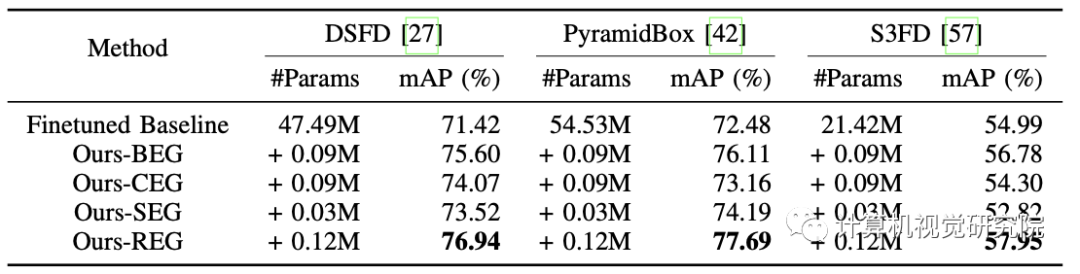
值得注意的是,MED在选择基础探测器方面很灵活。在实验中,一些最先进的算法,如DSFD、PyramidBox和S3FD,在嵌入REGDet时都显示了明显的性能改进。
四、实验及可视化
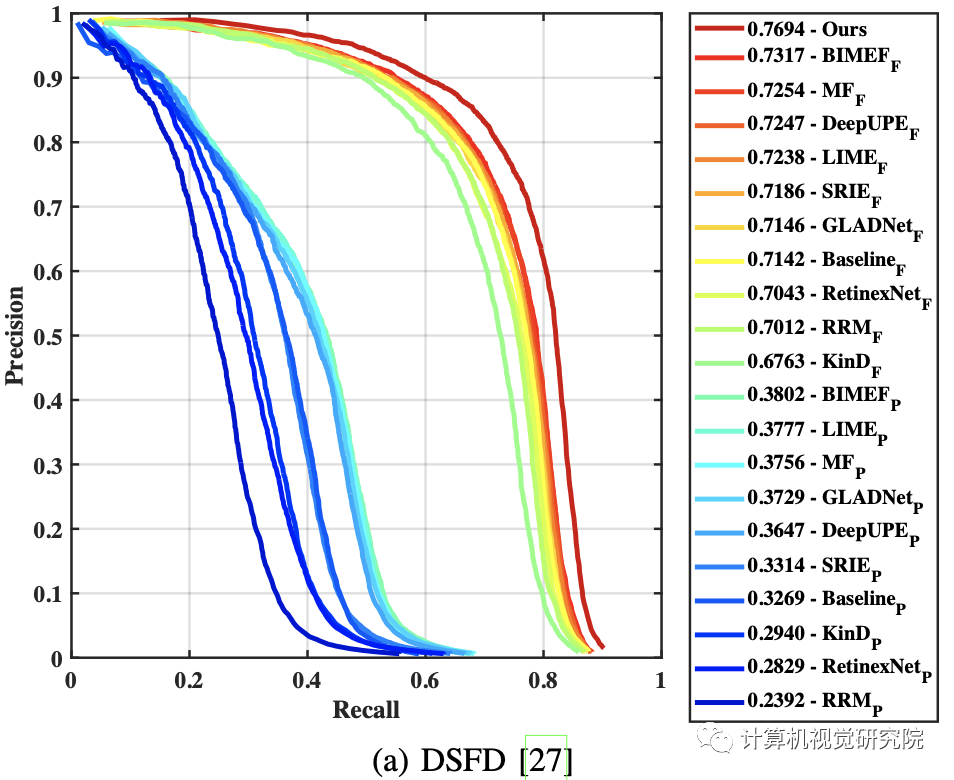
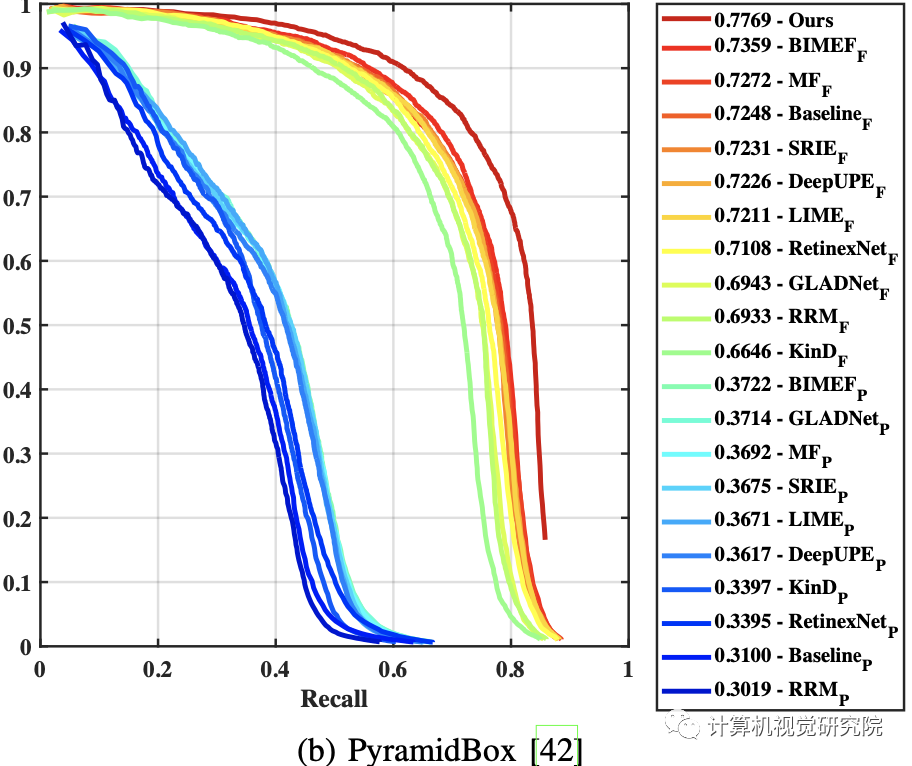


𝐼𝐼 𝐼𝐼
Results of a4blation study on the proposed REG module
双一流高校研究生团队创建 ↓
专注于目标检测原创并分享相关知识 ☞
整理不易,点赞三连!