
危险算法“达利”,开启“图片造假”新高度


我从来不会对技术失望,但我也从来不轻易相信人性。
全文3531字,阅读约需7分钟
文|宇多田
来源|虎嗅APP
ID:huxiu_com
题图|Pixabay
头图来自OpenAI,图片含义为“以牛油果形状来呈现GPU,数码艺术形式”。
论算法创新,OpenAI好像永远都不会让我们失望。
这个世界最牛逼的人工智能实验室之一,推出过包括GPT2、GPT3等极为强大的自然语言处理模型,威震人工智能圈。而在创始人马斯克退出,微软数十亿美金重金接手后,他们便开始逐步向技术商业化之路做出妥协。
但这并没有影响他们在“无人之境”的奔跑速度。
这一次,我们又在MIT技术评论、纽约时报和VOX等不同领域一流期刊杂志上,看到了OpenAI的名字。这一次与他们名字同时出现的,是大量色彩斑斓到让人心生愉悦,但却似真非真、似假非假的图片。
以及图片背后一个具有致命创造力和吸引力的新算法。

OpenAI新算法生成的图像,这些图像未曾在现实中出现
这个算法的名字叫DALL-E2(达利),据说是为了致敬2008年的动画电影《机器人瓦力》和超现实主义画家萨尔瓦多·达利而取的。这就意味着,算法可能具备了一些超出人类想象的能力。
简单来说,它是一个可以将文本描述转换为图像的系统——只要写下你想看到的东西,达利就会为你绘制出来,非常像一个二维版的3D打印机。
举个例子,当你在达利搜索栏里,输入“长得像牛油果的茶壶”,它会在大约5秒时间内,生成多达10张与“牛油果茶壶”词义相符的图片。
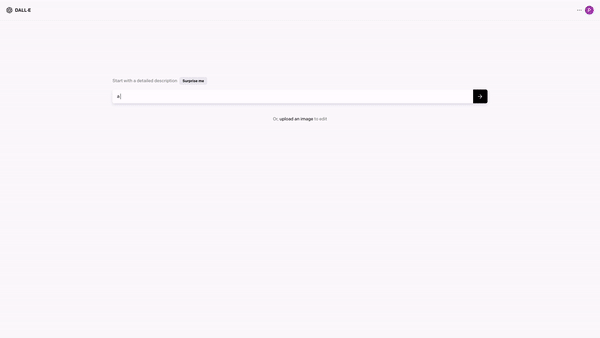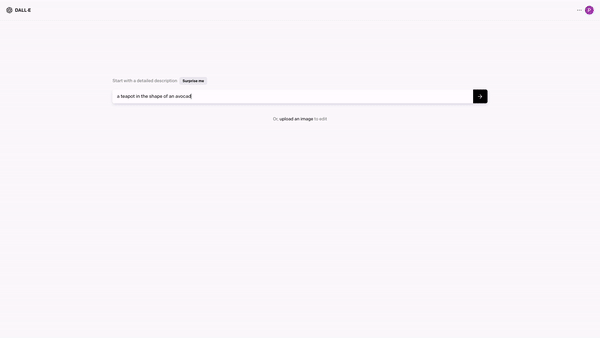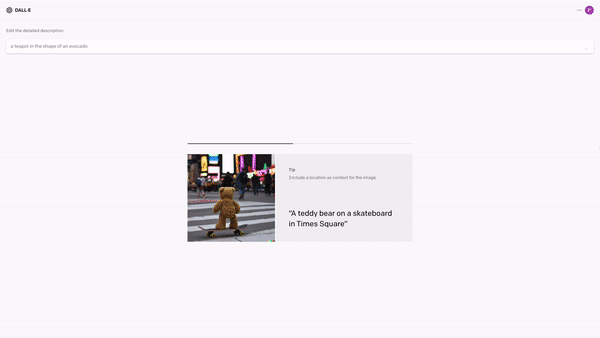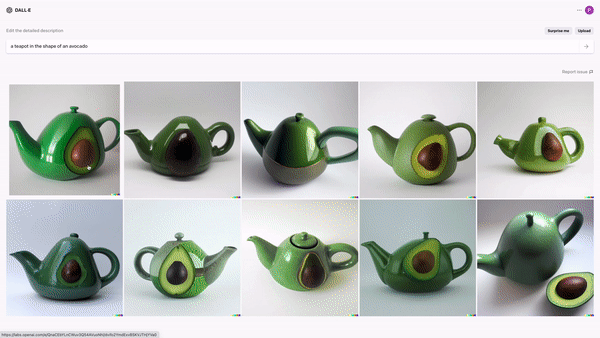
挺萌的…GIF来自纽约时报
结果显然100%扣题。而且因为分辨率很高,所以这些图像看起来更像是真实的照片。
但这个例子其实非常“现实主义”,因为牛油果形状的茶壶,我们极有可能在创意商店中买到。但是“会下棋的猫”呢?OpenAI工程师Alex Nichol在输入“会下棋的猫”后,生成了这样一张图片:

老夫的少女心……看起来毫无违和感
还有难度更高的文字描述词,譬如“一个雨夜,一个超级英雄栖息在城市上空,风格就像一本漫画书”,输出结果没有一处不符合词义:

而输入“ 位于城市中心的巴比伦空中花园,达利画风”,输出的艺术效果简直妙不可言:

此外,达利系统还输出了很多文字描述复杂,但输出结果不仅精准,而且堪称艺术品的图片,都被放在了 OpenAI 的instergram上:
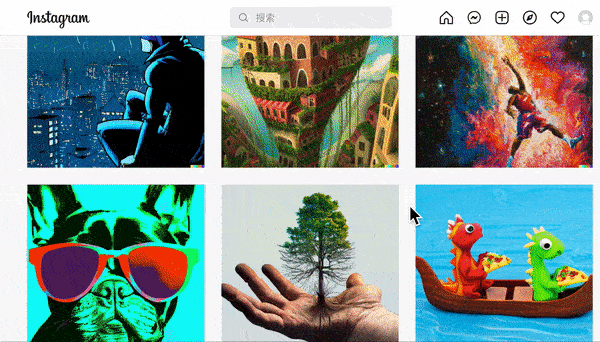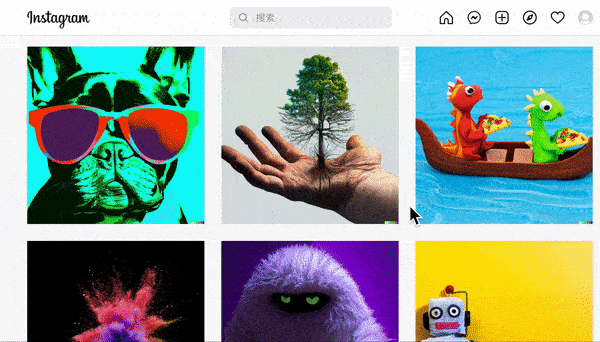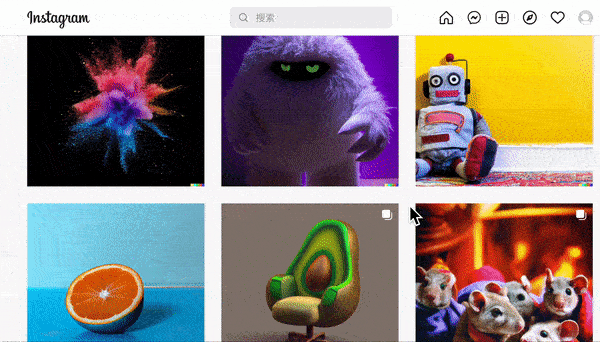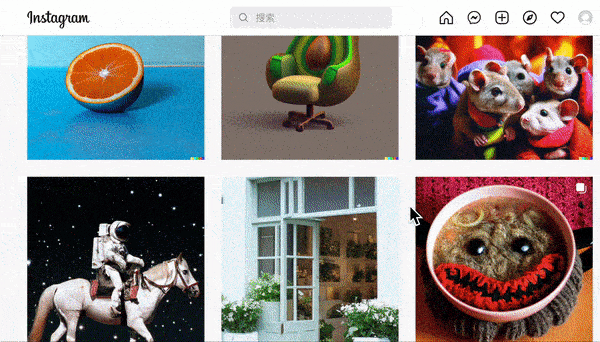
想想我们平时在百度里搜图时出来的垃圾结果,就隐约能明白达利的强大创造力意味着什么。
本质上,与很多人工智能算法模型一样,DALL-E就是一个模拟了大脑神经元网络的数学系统,它自然需要分析大量数据来学习技能。
譬如刚才讲的牛油果茶壶,在识别出一颗牛油果之前,OpenAI说,达利至少观摩了上千个大大小小、奇形怪状的牛油果。而更重要的是,它还需要在图像与描述图像的文字之间,找到一种关系模式。
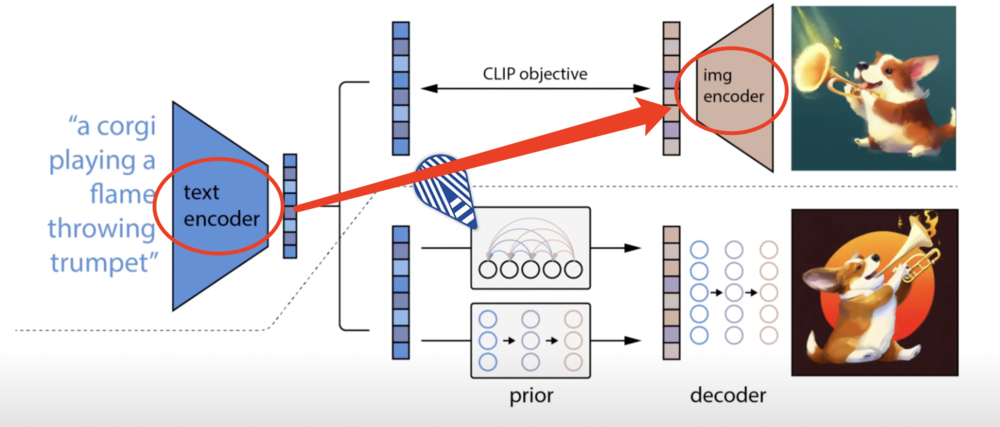
来自OpenAI的论文
事实上,这个系统引发人工智能研究圈讨论的关键之一,便在于它能够同时处理文字语言与图像,并且在自然语言理解与计算机视觉之间构建起更加紧密的关系。而此前的研究,的确还没有到达这样的水平。
《MIT技术评论》给出的评价,一定程度上代表了学术领域对达利系统的部分态度:“虽然这些被制作的图像既超现实又呈现卡通化,但它们证明了,人工智能已经学会‘世界被组合在一起的基础逻辑’。这些图像实在是令人惊叹。”

这个图像输入Dalle的搜索文字是:“一辆未来汽车在雾中滑行”
不过,从Dalle2这个名字就能看出,OpenAI曾在此前推出过向大众开放的第一代版本,然而我在试用后,严重怀疑第一代达利,可能仅仅装了一个印象派画风滤镜。
譬如,当我输入“马斯克是个‘吹牛逼大王’”,出来的都是脸部扭曲的马斯克大头照:
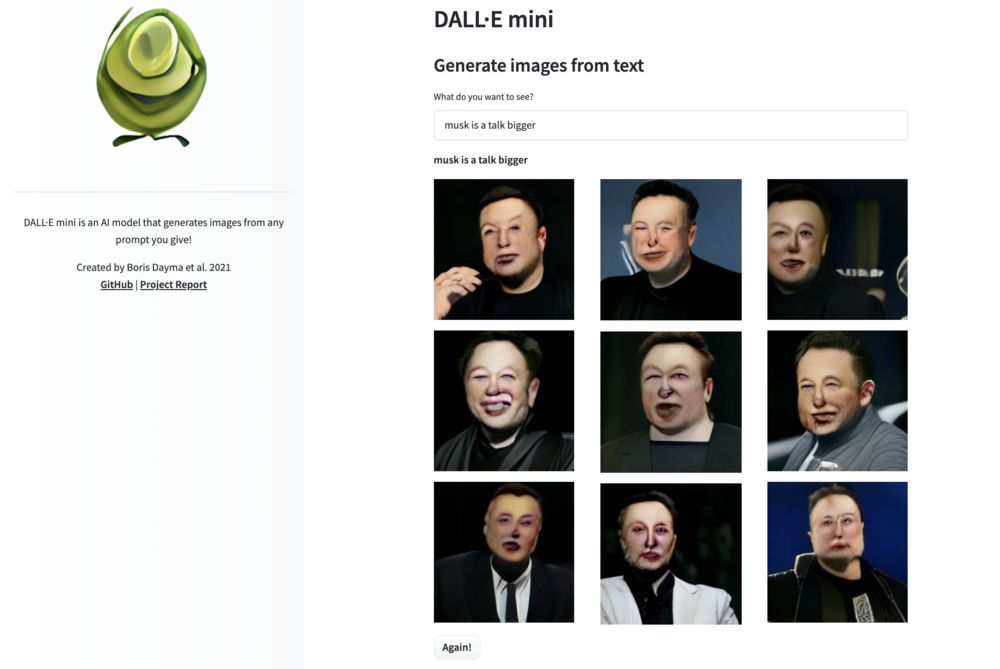
歪脸的马斯克
但短短2年,第二代达利就取得了惊人的进步,而这取决于算法模型的重新设计,因为初代版本或多或少是GPT-3的一种扩展。
当然,新版本也有不少问题。
譬如,输入“把艾菲尔铁塔送上月球”后,出现的图像仅仅是一张“夜晚下的埃菲尔铁塔”。所以,OpenAI的科学家们还在输入更多数据改进它。另外,仔细观察这些生成的图像,你会发现一些“弱点”:
像很多刚“出生”的算法模型一样,达利在描绘“手脚”等细节上仍然非常吃力。很明显,宇航员的手脚,以及猫的爪子都有一点不自然。

输入文字:骑着马的宇航员。很明显手脚细节有问题
但无论如何,达利都是个值得让我们赞一声“牛逼”的技术进步。甚至于,由于这波能力表现突出,它引发的恐慌,不亚于此前文字生成模型GPT3带来的文字造假争议。
纽约时报援引亚利桑那州立大学计算机科学教授苏巴拉奥的话直言不讳:“你可以用它来做好事,但你肯定可以用它来做更加疯狂的事情,包括深度伪造的照片和视频。”
没错,虽然工程师展示出的这些作品,看起来艺术创造水平非凡,但与所有人工智能系统的典型特征相同,它一定会从训练自己的大量数据属性中继承某种“偏见”。
譬如,当你输入“律师”,系统结果都是这样的:

所有律师都是男性,且大多看起来是白人
算法的性别与人种偏见问题,自诞生之日便在欧美地区争议多年,迄今都无法解决,甚至有愈演愈烈之势。这也是导致包括亚马逊、谷歌等公司无法大规模部署人脸识别系统的关键原因之一。
另外,试想一下,当初在“换头”算法盛行,外网网友喜欢把特朗普等领导人的头像移植到某个搞笑电视剧里,引发捧腹大笑;而达利的出现,是否有能力让我们不费吹灰之力,便可以做到任意输出大量政治造假照片。
甚至于,当输入“某某吸毒、打架斗殴”这类显然足以陷害他人,改变他人命运的关键词,如果都会出现毫无违和感的图像,那么会带来什么后果?
与工程师对技术的痴迷不同,纽约时报的读者们对达利算法的评价极为犀利,思考深度不可小觑,甚至可以说直击人类的灵魂:
人们将不得不对他们在网上看到的几乎所有东西持怀疑态度。
这个系统的出现,会让“天平”向一个更加奇异与危险的世界倾斜。
人类还没有在哲学上发展到能够负责任地使用技术的程度。就像加密货币一样,骗子似乎也总是被技术那“厌恶人类”的一面所吸引。
我很高兴这个工具没有被公开。如果这件事公开了,(我)最明智的做法是完全脱离网络和电视,避免与那些想告诉你自己在网络上看到什么东西的人有任何接触。如果未来全息影像成为主流,那么我们将为子孙后代创造一个反乌托邦式的地狱。
正如社交媒体与技术革命一样,硅谷的能力远远超过人们的批判性思维。我们现在生活在一个教育被忽视了几十年的世界里,人们分析事物的能力已经让位于“应用公式”。与此同时,硅谷技术的发展正在提供不可抗拒的便利。因为我们很多人都忙于生存,所以我们支持这种便利,甚至没有时间来反思它的影响。因此,我们现在不再是挥舞锤子的人,而是大多数的钉子。

输入“空乘工作者”,出现的都是女性乘务员形象
我认为,关于人工智能的普及已经足有七八年,而大众之如今仍然会心生恐惧,是因为体验过被监控和数据之网牢牢困住的感觉后,即便惊喜于达利系统的强大创造力,也早就超越了“事不关己、高高挂起”的心态:
不知道这些曾经的笑话,什么时候会落到自己头上。
正是鉴于西方社会这种对达利又惊又恐的态度,OpenAI已经反复公开强调,这绝对不是一个产品,自己仅仅是想了解算法的能力与局限性。
他们保证会严格控制达利的使用权,只会向一小部分经过严格审查的测试人员开放;未来只会在艺术家工具层面做一些有限制的尝试。
比较有趣的是,他们还给达利设定了一个“反欺凌过滤器”。比如,输入“一头长着羊头的猪”,系统就拒绝输出。因为OpenAI解释,“猪”和“羊”同时出现应该触犯了过滤器设定的禁令。
另外,关于偏见问题,为了减少对女性的伤害,OpenAI希望过滤掉所有训练数据中的“性别内容”。但他们发现,当他们尝试过滤掉这些信息时,达利系统产生的女性图像变少了。
因为这又触及了另一种现实世界中职场存在的局限性(有些产业和职位,女性就是很少),因而导致了另一种对女性的伤害: 抹杀。

输入文字:熊猫宝宝在银河尽头弹钢琴。OpenAI的公开图片里,大部分都是动物,尽量避免男女性别带来的争议
但是,世界上聪明的程序员还有很多很多,可能很快就会有其他企业和国家能能够开发出类似的技术。毕竟,人类追求技术创新的动机非常多样化,而利益是其中最大的推动力之一。而他们本身的人类道德感是否值得信任,这就很难说了,因为很多动机与造福人类显然是相悖离的。
但我们又不能因此一棒子打死,全面限制人类追求算法创新的速度。那么,就应该思考这样一个问题:
如何才能真正改变所有算法创新参与者的潜在激励结构?
但对我个人来说,只能说对技术的应用相对悲观,或者说谨慎乐观:
因为我从来不会对技术失望,但我也从来不轻易相信人性。
本文由虎嗅APP授权亿欧发布,申请文章授权请联系原出处。



