
假新闻遇上 AI,祸兮福兮?
近日,一则“机器人受尽欺压奋起反抗”的视频刷上了各大平台的排行榜。视频中,为了测试机器人的平衡性,测试人员用脚踹、凳子砸等方式对机器人进行百般折磨。

不堪其辱之下,机器人向人类展开了反抗。灵活的机械身体很快击败了人类的血肉之躯,测试人员开枪亦无济于事。在 Twitter、微博、朋友圈,评论纷纷涌现:“人类要完啦!!!”
当然,这是则谣言。
特效公司 Corridor 旋即对这一消息进行辟谣,并顺带打出了绝妙的广告:看看我们的特效技术有多好!
留下的,是社交网络之上,或惊慌失措,或信誓旦旦的,分享与转发的一地鸡毛。
假新闻,在这个信息泛滥的时代绝不会让你感到陌生。爆料、反转、再反转,我们几乎已经习惯了与谣言共生,对社交网络的所有信息打上个问号。
据 MIT 科研人员的研究,假新闻的散布速度、深度、广度均远远高于事实真相。造谣张张嘴、辟谣跑断腿,这句话一点不假。这种现象其实很容易理解:“机器人反抗人类”理所当然地比“目标检测技术又提升了零点几个百分点”来的抓人眼球,假新闻的病毒式传播因而显得顺理成章。
然而,面对假新闻,我们真的束手无策吗?
“信息癌症”特效药,AI 从何下手
为了打击谣言,人们不是没想过别的办法,但目前看来,人工审核、干预、用户举报... 这些依靠人力的手段在前所未有的海量信息面前,都显得杯水车薪。
看来,借助人工智能技术来鉴定、识别假新闻,几乎成了我们唯一的希望。

Twitter收购Fabula AI
六月三日,Twitter宣布收购初创企业Fabula AI,意图借助其独到的“图深度学习”AI技术,为Twitter构建更可靠的假新闻过滤系统。
图深度学习技术是什么?人工智能又怎么能识别假新闻呢?让我们一一厘清。
AI到底要怎么识别假新闻呢?究其根本,还是依靠假新闻不同于真实事件的各项特征。
首当其冲的,便是信息来源的可靠度。
我们知道,在大多数情况下,路透社的新闻要比路边社的消息来的可靠。AI自然不会放过这一特点。对于社交网络上的消息,AI更会结合多重信息,对信息来源的可靠度进行深入判定。

当你看到的消息来源是洋葱新闻时,你大概不会相信它(美国洋葱新闻)
对Twitter而言,发帖人的位置信息、IP地址,账号的注册、活跃时间,帖子点赞、转发与回复的比例,都可成为人工智能判定的依据。比如,你在新乡发了则“纽约时代广场今天发生暴动”,这事情的真实性就不免存疑。再比如,一个日常和其他人在评论区聊得火热的账号,自然就比每天“转发微博”的三无营销号来的可靠。
其次,消息之间的交叉验证也是重要考量。
以自然灾害信息为例,如果有很多人都在事发地附近发布了灾害相关的信息,这一消息的可靠度便大大提升,假新闻的概率随之下降。相反的是,如果搜遍全网发现只有某个自媒体小号发布了洪水报告,这消息的真实率便大打折扣。
用户的反馈也是交叉验证的一部分。假如可信度较高的账号们(如经过认证的领域专家们)纷纷对某一消息进行反驳、辟谣,这消息的谣言成分便显得毋庸置疑起来。
第三,假消息内在的结构特征,也是识别算法的重要武器。
以文字信息为例,如今的自然语言处理算法可以提取出写作的结构、特点,加以分类。“标题党”、“鼓动式描述”、“只谈观点不列数据”等等均是假新闻自露马脚的常见特征。
借助社交网络平台上的海量数据,算法更能学习到我们自身难以认知的隐含结构,对假新闻进行更好的识别。
图片信息亦然。美国时间6月15号,PS软件的开发公司—— Adobe 公布了对付自家软件的独门秘籍,借助人工智能技术,他们识别图片中修过的部分,对“俊男靓女”们赖以为生的瘦脸算法进行还原。假脸无从遁形,谣言里的合成图像就更不例外,成为AI识别假新闻的重要根据。

Adobe人工智能检测修图区域
https://gadgets.ndtv.com/apps/news/adobe-unveils-ai-tool-that-can-detect-photoshopped-faces-2053870
讲了这么多,要准确地识别假新闻,算法可提取、结合的信息源实在太多。对于单个用户的各项信息,传统机器学习算法相对有效,对于自然语言和图像信息,近年来得以大发展的神经网络模型能对其进行全面、高效的理解。
然而,面对社交平台上纵横交错的传播网络,面对这么多种纷繁复杂的数据源,我们到底怎么才能将他们结合起来,实现对假新闻的准确判定呢?
信息打假:矛与盾的较量
图深度学习算法,可能是如今最接近正确答案的选项,这也是 Twitter 选择收购 Fabula AI 的根本原因。
社交平台天然具有网络属性。利用这一属性,我们可以以用户、推文为节点,构建起庞杂繁复的网络图模型。在这基础之上,图深度学习算法便能有效融合传统算法所力不能及的海量信息,将用户特征、用户之间的交流、消息本身的传播等等一一考虑在内,实现对假新闻的准确识别。

真假新闻特征可视化,红色为经常发布假新闻的用户,蓝色为几乎不发布假新闻的用户
https://techcrunch.com/2019/02/06/fabula-ai-is-using-social-spread-to-spot-fake-news/
据 Fabula 的数据,依靠图深度学习模型,他们能够在信息扩散的前几个小时之内实现 93% 的准确识别,为假新闻识别立起一栋标杆。被 Twitter 收购以后,借助 Twitter 的数据,这一准确率有望继续提升,成为 Twitter 打击假新闻的重要手段。
然而,“以子之矛,攻子之盾”,AI 在辨别假新闻的同时,也成为了假新闻的制造者。
就在上个月,人工智能领域大名鼎鼎的 OpenAI 便放出了他们的 AI 假新闻制造器,让大家试用、体验。
在这个名为 “Talk to Transformer” (译为 “对Transformer说话”,Transformer 是自然语言处理领域的重要算法)的网站里,你可以随便输入几个单词,OpenAI 的人工智能算法便能为你编出一篇完整的“假新闻”。笔者试用了一下,输出的文章居然还真是有模有样,乍看之下,可信度极高。
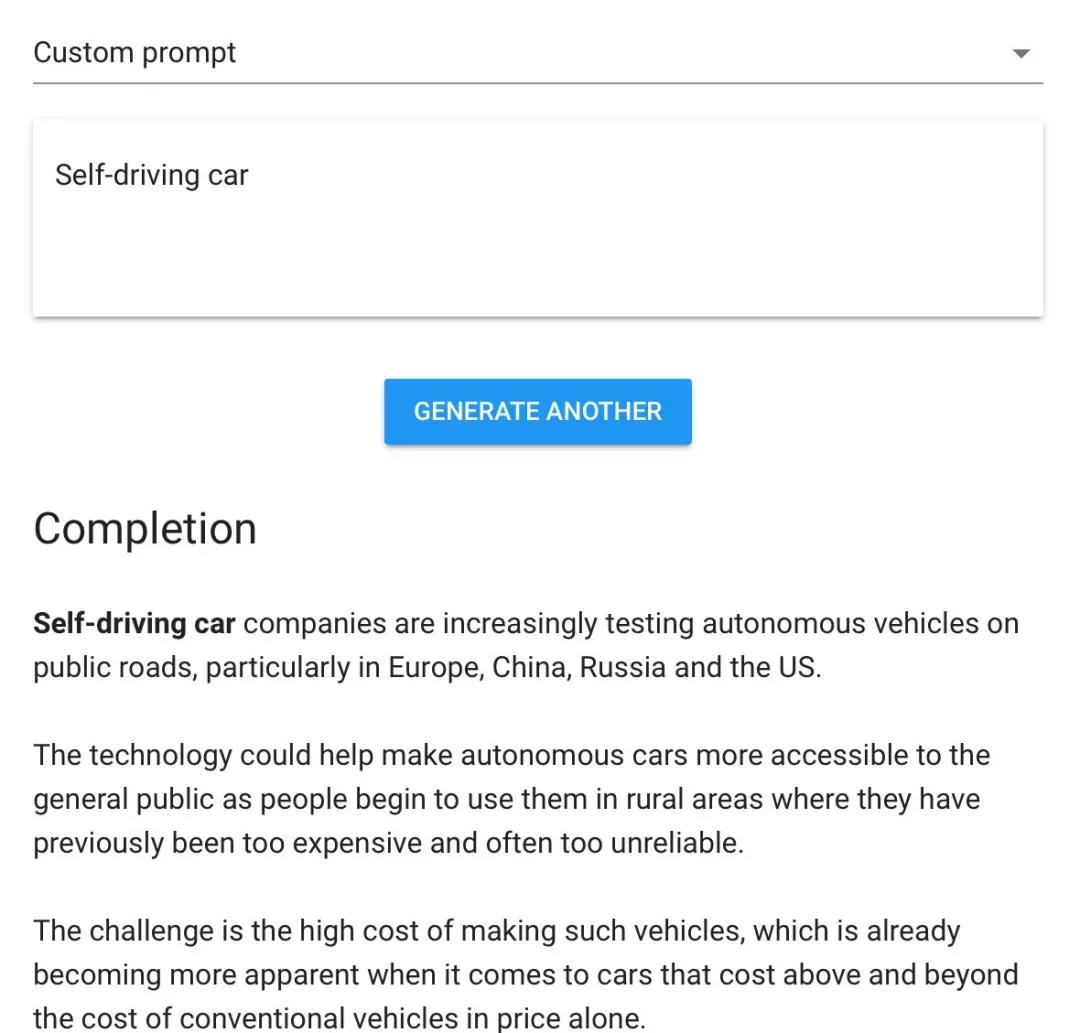
试用“Talk to Transformer”
文字之外,图像和视频更是重灾区。大名鼎鼎的 DeepFake 算法就是其中的代表:借助对抗神经网络算法,人工智能可以将一个人的表情、动作无缝对换到另一个人身上,在视频里高谈阔论的政治家可能就是你隔壁的书呆子男孩,直播间的网红女主播则可能是虎背熊腰的抠脚大汉,“眼见为实”成为历史,借助假人物的虚假背书,假新闻、假消息的扩散来的更为严重。

Deep Fake,将左上角表演者的表情动作替换到左下角人物身上
https://www.cnn.com/interactive/2019/01/business/pentagons-race-against-deepfakes/
AI 造假,精细程度上一再突破,规模上更是传统人力捏造所不能媲美,面对这一挑战,我们又该如何应对呢?
首先,技术伦理十足重要。面对假新闻的潜在威胁,OpenAI 决定不如以往一般对外公布训练好的人工智能模型,让大规模、自动化制造 AI 假新闻的门槛大大提高。DeepFake 也在舆论的压力下从 Github 删除,让造假者更难通过简单地调用实现视频换脸,让 AI 假消息的规模得以控制。
其次,“以子之矛,攻子之盾”之下,“盾”的质量便显得更为重要。只有更好地利用 AI,让它更好地鉴别、筛选假新闻,我们才能 “道高一尺、魔高一丈”,取得最终的胜利。
AI 假新闻其实也未必全是坏事,自动化的假新闻制造也为假新闻的识别算法提供了几近无限的训练集。利用类似于对抗神经网络算法 —— 一个模型造假,一个模型辨假的思路,识别算法也能得到更好的提升,让我们能更好地识别包括 AI 造假在内的各项假新闻消息。
对于假新闻的 AI 识别,中国并不落后。在查访各方文献时,中国科研人员的身影随处可见。今年愚人节当天,阿里便发布了自研的 “AI谣言粉碎机”,可以帮助诸多社交媒体平台减轻人工审核的沉重负担。
阿里发布AI谣言粉碎机
http://www.sohu.com/a/305172138_115479
算法研发之外,中国更有望借助数据、人工审核标注等多方面的独到优势,在人工智能识别假新闻的这一特定战场上,实现超越,让微博、微信、各方媒体更为可靠,让“反转再反转”的剧情少点上演。
而我们现在能做的,就是下次在转发 “震惊!99% 的中国人都不知道...” 这种文章之前,先去网上验证下信息是否真实。