
例如,爬取赵丽颖,赵本山,赵文卓,赵欢,赵日天的图片分别保存在赵丽颖,赵本山,赵文卓,赵欢,赵日天命名的文件夹中,
测试代码
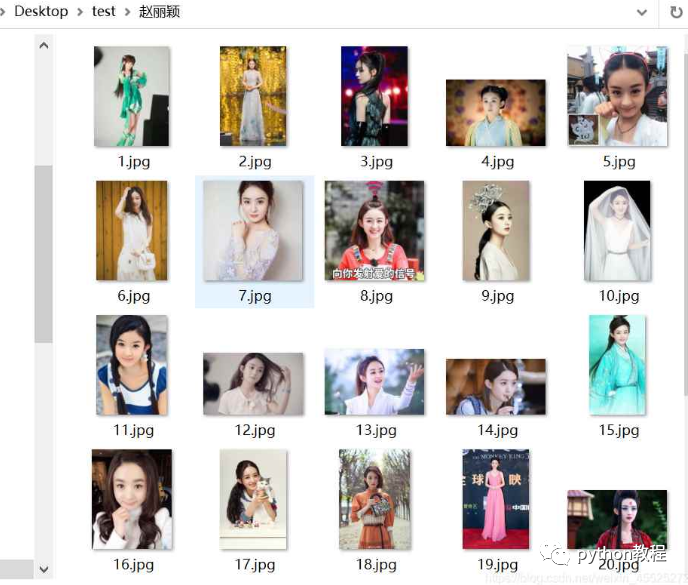
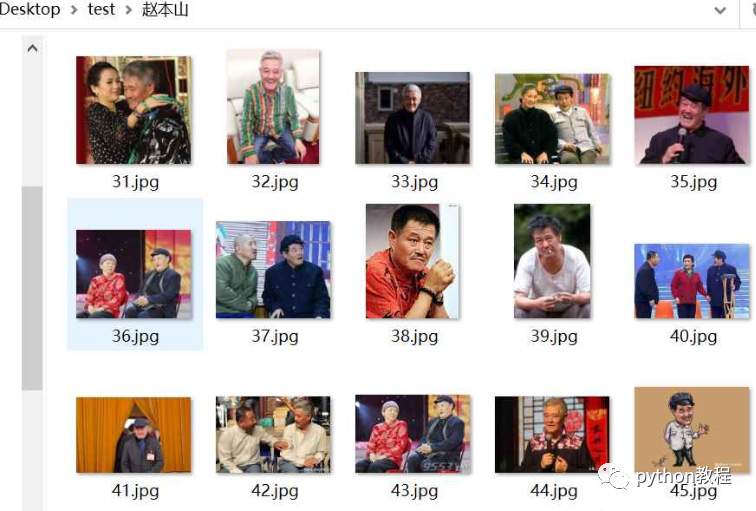
别的图就不放了
import requests
import time
import os
# 请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
# keyword = '云斑白条天牛' # 关键字
keywords = ['赵丽颖','赵本山','赵文卓','赵欢','赵日天']
max_page = 2
i=1 # 记录图片数
for keyword in keywords:
os.makedirs(keyword)
for page in range(1,max_page):
page = page*30
# 网址
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord='\
+keyword+'&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word='\
+keyword+'&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=wallpaper&pn='\
+str(page)+'&rn=30&gsm=1e&1596899786625='
# 请求响应
response = requests.get(url=url,headers=headers)
# 得到相应的json数据
json = response.json()
if json.get('data'):
for item in json.get('data')[:30]:
# 图片地址
img_url = item.get('thumbURL')
# 获取图片
image = requests.get(url=img_url)
# 下载图片
newstr = './'+keyword+'/'+str(i)+'.jpg'
# with open('./%s/%d.jpg'%keywords ,%i,'wb') as f:
with open(newstr,'wb') as f:
f.write(image.content) # 图片二进制数据
time.sleep(1) # 等待1s
print('第%d张%s图片下载完成...'%(i,keyword))
i+=1
print('End!')
你要修改的参数
将你想要爬的数据填入keywords 数组中即可
# 这里放你要查询的数组
keywords = ['','','',']
max_page是爬取百度图片的页数,一页是30张,这里写2的话就能爬30张,3能爬60张,以此类推
max_page = 3
你要的代码
代码如下:
import requests
import time
import os
# 请求头,伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
# 这里放你要查询的数组
keywords = ['','','',']
max_page = 4
i=1 # 记录图片数
for keyword in keywords:
os.makedirs(keyword)
for page in range(1,max_page):
page = page*30
# 网址
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord='\
+keyword+'&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word='\
+keyword+'&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&cg=wallpaper&pn='\
+str(page)+'&rn=30&gsm=1e&1596899786625='
# 请求响应
response = requests.get(url=url,headers=headers)
# 得到相应的json数据
json = response.json()
if json.get('data'):
for item in json.get('data')[:30]:
# 图片地址
img_url = item.get('thumbURL')
# 获取图片
image = requests.get(url=img_url)
# 下载图片
newstr = './'+keyword+'/'+str(i)+'.jpg'
# with open('./%s/%d.jpg'%keywords ,%i,'wb') as f:
with open(newstr,'wb') as f:
f.write(image.content) # 图片二进制数据
time.sleep(1) # 等待1s
print('第%d张%s图片下载完成...'%(i,keyword))
i+=1
print('End!')
到此这篇关于python爬不同图片分别保存在不同文件夹中的实现的文章就介绍到这了
 扫下方二维码加老师微信
扫下方二维码加老师微信
或是搜索老师微信号:XTUOL1988【切记备注:学习Python】
邀您来听Python web开发,Python爬虫,Python数据分析,人工智能 免费精品教程,0基础入门到企业项目实战教学!
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
万水千山总是情,点个【在看】行不行
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜
