没有数分分析项目经历,如何在面试展示自己?
“找实习好难啊,没有相关经历是不是可以放弃了?”
“没有实习/项目怎么找第一份实习啊?”
“没有数据项目怎么在面试中展示自己呀?”
——这是我在公众号后台中收到最多的连环问题……

天池-数智教育可视化
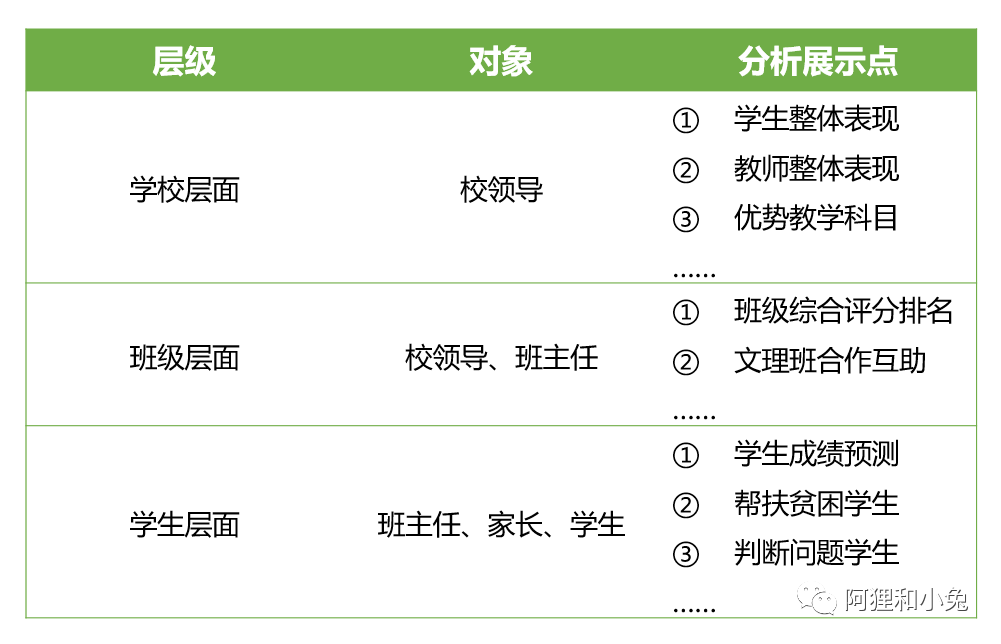
天池-aribnb短租数据集分析赛
Kaggle – hotel booking demand
评论
 下载APP
下载APP“找实习好难啊,没有相关经历是不是可以放弃了?”
“没有实习/项目怎么找第一份实习啊?”
“没有数据项目怎么在面试中展示自己呀?”
——这是我在公众号后台中收到最多的连环问题……
天池-数智教育可视化
天池-aribnb短租数据集分析赛
Kaggle – hotel booking demand