
ORM 是“反模式” 吗?

【编者按】ORM(对象关系映射)在软件开发中受到争议,常见批评包括违反 SOLID 原则和效率低,但实际问题在于透明性和调试困难。如果能够正确使用 ORM ,那么它的执行效率也会很高,但很多开发者往往过度依赖主机语言而没有充分利用 ORM 的原生 SQL 功能。
原文
链接:
ht
tps:/
/githu
b.com/getlago/lago/wiki/Is-ORM-still-an-%27a
nti-pattern%27
%3F
未经允许,禁止转载!
作者 | lago 译者
| 明明如月
责编 | 夏萌
出品 | CSDN(ID:CSDNnews)

前言
对象关系映射(ORM)常常是软件开发者热议的焦点。
你可以在网络上发现大量文章唱反调:“ORM 是反模式,它们只是创业公司的小玩具,整体来说弊大于利。” 这其实有些过分夸大其词。ORM 并非全无用处。正如软件领域里的技术一样,完美的 ORM 并不存在。然而,对 ORM 的批评也在意料之中——若是两年前,我可能也会全盘接受这些刻板印象。我也曾有过类似 "你是说 ORM 把服务器的内存耗尽了?" 的遭遇。
但是,实际情况是 ORM 框架被误用的例子要比被滥用的例子还要多。
这篇试图辩护 ‘ORM 其实并没有那么糟糕’ 的文章,源自我们在 Lago 公司因为 ORM 遭遇的一次不愉快经历。这次经历使我们开始对我们对 Ruby on Rails ORM,即 Active Record 的依赖产生疑问。如果要为这篇文章取一个更具吸引力的标题的话,可能会是 “ORM 的确有些问题”。但在深入思考这个问题后,我们认为 ORM 框架并不糟。它们只是一种抽象工具,有其优点和缺点——它们抽象化了一些可见性,偶尔会导致一些性能损失。仅此而已。
今天,我们就来深入探讨 ORM,分析常见的批评和聊聊真正的问题所在。

两种范式的对比
我们从一个简单的问题开始:ORM 和数据库遵循两种不同的范式。
ORM 创建对象(这就是 O 的来源)。对象就像有向图——节点指向其他节点,但并不一定互相指向。而相反,数据库的关系表包含的数据总是通过共享键(也就是无向图)进行双向链接。
从技术角度来看,ORM 可以通过强制实现双向指针来模拟无向图。但实际上,这样做并不容易;很多开发者最后可能得到的是缺少
Posts
数组的
User
对象 或者
Posts
数组实体缺少对同一
User
对象的反向引用(但可能是一个克隆对象)。
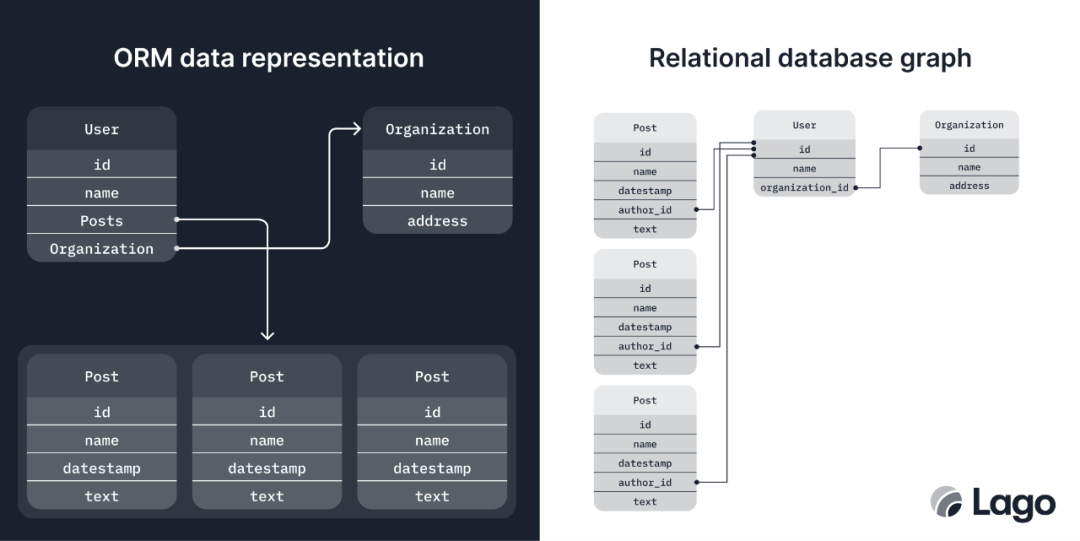
ORM 和关系数据库遵循两种不同的范式。例如,ORM 可能会将用户(User)的帖子(Post)以数组的形式返回,但不会在每个帖子(Post)中包含对 User(作者)的反向引用。
然而,这种范式的不匹配并非无法解决。ORM 和关系数据库最终都只是图形呈现;只是数据库只有非定向边。尽管这对 ORM 来说是一个学术上较有道理的批评,但 ORM 的真正问题其实更为“深刻”。

打破的原则
在深入讨论"细节问题"之前,我们首先讨论一些更基础的原则。关于 ORM 框架的常见抱怨之一就是它们违反了在软件设计课程中所教授的 SOLID 原则中的两条。如果你不了解 SOLID,它是一个首字母缩略词,代表了一些重要的设计原则。
单一职责原则(SRP)
ORM 被批评违反了单一职责原则(SRP)。SRP 要求一个类应该只有一个存在的目的。然而,ORM 并未达到这一标准。在较高的抽象层面上,它们处理了"所有的数据库事务",但这就好比创建一个处理"所有应用事务"的单一类。JohnoTheCoder 对此有一个非常好的解释:ORM (i) 创建了用于和数据库交互的类,(ii) 代表了一个记录,以及 (iii) 定义了关系。我还会进一步补充说,ORM (iv) 创建并执行了迁移。
除了你,还有其他人对这种针对 ORM 的语义上的批评感到不满。我也认为这种常见的反对 ORM 的论点有点模糊。毕竟,ORM 的主要工作就是弥补两种根本不同的数据范式之间的差距;它当然会打破一些原则。
关注点分离(SOC)
关注点分离(SOC)的思想和 SRP 相似,但是应用在不同的层面。SOC 规定,强调将不同的功能分离开来,使得每个模块可以独立地开发、测试和维护。然而,ORM 将数据库管理从后端转移到了数据库本身,违反了 SOC。但在如今 SOC 这种原则已经有些过时了。现在,基础设施组件和编码模式正在协同合作,以实现更好的性能(比如在 OLAP 数据库中的 CPU 聚合器)、更低的延迟(例如在前后端中间的边缘计算)以及更清晰的代码(例如使用 Monorepo 仓库代码管理模式)。

真正的问题
现在我们已经详细地讨论了这些"假"问题,让我们来看看 ORM 的真正面临的问题。ORM 框架采取较为守旧的方法。它们使用一种可预测和可重复的查询系统,这种系统本身并没有被优化或可视化。然而,ORM 框架的开发者们意识到了这一点;他们已经添加了许多功能来解决这些问题,自 Active Record 首次亮相以来,他们已经取得了巨大的进步。
效率
开发者普遍认为 ORM 框架性能不佳。
这种说法在很大程度上是不准确的。实际上,ORM 框架的效率通常要比许多开发者想象的要高。然而,由于依赖主机语言(例如 JavaScript 或 Ruby)来组合数据过于简单,ORM 的使用确实引导了一些不良的开发实践。
例如,看一看这段使用 JavaScript 扩展数据条目的效率低下的 TypeORM 代码:
const authorRepository = connection.getRepository(Author);
const postRepository = connection.getRepository(Post);
// Fetch all authors who belong to a certain company
const authors = await authorRepository.find({ where: { company: 'Hooli' } });
// Loop through each author and update their posts separately
for (let i = 0; i < authors.length; i++) {
const posts = await postRepository.find({ where: { author: authors[i] } });
// Update each post separately
for (let j = 0; j < posts.length; j++) {
posts[j].status = 'archived';
await postRepository.save(posts[j]);
}
}
相反,开发者应该使用 TypeORM 的内置功能构造单个查询:
const postRepository = connection.getRepository(Post);
await postRepository
.createQueryBuilder()
.update(Post)
.set({ status: 'archived' })
.where("authorId IN (SELECT id FROM author WHERE company = :company)", { company: 'Hooli' })
.execute();
在 Lago 的对账单 SQL 重构中有一个很好的例子。Active Record 的问题与其可见性有关(下面会详细讨论)。我们的 ORM 和原生 SQL 查询的性能相当。由于我们大量使用了 Active Record 的数据联接功能,我们的查询已经过优化:
InvoiceSubscription
.joins('INNER JOIN subscriptions AS sub ON invoice_subscriptions.subscription_id = sub.id')
.joins('INNER JOIN customers AS cus ON sub.customer_id = cus.id')
.joins('INNER JOIN organizations AS org ON cus.organization_id = org.id')
.where("invoice_subscriptions.properties->>'timestamp' IS NOT NULL")
.where(
"DATE(#{Arel.sql(timestamp_condition)}) = DATE(#{today_shift_sql(customer: 'cus', organization: 'org')})",
today,
)
.recurring
.group(:subscription_id)
.select('invoice_subscriptions.subscription_id, COUNT(invoice_subscriptions.id) AS invoiced_count')
.to_sql
它被下面这个重写的原生 SQL 所替代:
SELECT
invoice_subscriptions.subscription_id,
COUNT(invoice_subscriptions.id) AS invoiced_count
FROM invoice_subscriptions
INNER JOIN subscriptions AS sub ON invoice_subscriptions.subscription_id = sub.id
INNER JOIN customers AS cus ON sub.customer_id = cus.id
INNER JOIN organizations AS org ON cus.organization_id = org.id
WHERE invoice_subscriptions.recurring = 't'
AND invoice_subscriptions.properties->>'timestamp' IS NOT NULL
AND DATE(
(
-- TODO: A migration to unify type of the timestamp property must performed
CASE WHEN invoice_subscriptions.properties->>'timestamp' ~ '^[0-9\.]+$'
THEN
-- Timestamp is
stored as an integer
to_timestamp((invoice_subscriptions.properties->>'timestamp')::integer)::timestamptz
ELSE
-- Timestamp is stored as a string representing a datetime
(invoice_subscriptions.properties->>'timestamp')::timestamptz
END
)#{at_time_zone(customer: 'cus', organization: 'org')}
) = DATE(:today#{at_time_zone(customer: 'cus', organization: 'org')})
GROUP BY invoice_subscriptions.subscription_id
不过,请别误会,相比于原生 SQL 查询,ORM 并非总是那么高效。
在通常情况下,它们可能稍显低效,而在某些特定情况下,可能会变得非常低效。
第一个问题是,有时 ORM 在将查询转换为对象时会产生大量的计算开销,TypeORM 就是这个问题的罪魁祸首。
第二个问题是 ORM 有时会通过循环遍历一对多或多对多的关系来对数据库进行多次请求。这就是所谓的 N+1 问题(1个原始查询 + N个子查询)。例如,下面这个 Prisma 查询会为每一条评论都进行一次新的数据库请求!
首个
问题是 ORM 有时在将查询转化为对象时会产生大量的计算开销(TypeORM 是此问题的主要罪犯)。
第二个
问题是 ORM 有时会通过循环遍历一对多或多对多的关系,导致对数据库的多次请求。这就是所谓的 N+1 问题(1个原始查询 + N个子查询)。例如,下面的 Prisma 查询会为每一条评论都进行一次新的数据库请求!
{
users(take: 3) {
id
name
posts(take: 3) {
id
text
comments(take: 5) {
id
text
}
}
}
}
使用 ORM 框架经常会遇到 N + 1 问题。然而,它通常可以通过使用 data loaders 来处理,这些 data loaders 将查询合并为两个查询,而不是 N + 1。因此,就像大多数其他常见的 ORM “问题”一样,N+1 场景通常可以通过充分利用 ORM 的功能集来避免。
透明性
ORM 的主要问题在于透明性。由于 ORM 本质上是查询生成器,因此除了明显的场景(如错误的原始类型)之外,它们并不是最终的错误传递者。相反,ORM 需要处理返回的 SQL 错误并将其解释给用户。
在这方面,Active Record 遇到了挑战,这也是我们重构我们的计费订阅查询的原因。每当我们得到未预期的结果时,我们就需要检查生成的 SQL 查询,再次运行它,然后将 SQL 错误转化为 Active Record 的修改。这个反复的过程背离了 Active Record 的设计初衷,即避免直接与 SQL 数据库进行交互。

结语
实际上,并不能说 ORM 本身有什么问题。当我们正确地使用它们时,它们几乎可以和原生 SQL 一样高效。然而,遗憾的是,开发者们常常错误使用ORM,可能过分依靠主机语言的逻辑结构来创建数据结构,却没有充分利用 ORM 提供的与原生 SQL 类似的特点。
然而,ORM 在透明性和调试方面确实存在问题——这正是我们在 Lago 遇到的情况。当一个复杂的查询给开发者带来困扰时,将其转换为原生 SQL 查询可能是一个好的投资。幸运的是,大多数 ORM 本身也支持 SQL 查询的执行。
推荐阅读:
▶腾讯回应与Meta VR头显合作传闻;美国考虑限制中国用户使用美国云计算服务;ChatGPT暂停联网测试|极客头条
▶
2023 年嵌入式开发现状:Linux、FreeRTOS位居榜首,专有软件代码复用更常见!
▶
突发!ChatGPT 紧急暂停 Bing 集成,下线搜索功能
评论