
Redis 主从复制、哨兵模式、集群
公众号关注“杰哥的IT之旅”,
选择“星标”,重磅干货,第一时间送达!

1、单机模式
持久化是最简单的高可用方法(有时甚至不被归为高可用的手段),主要作用是数据备份,即将数据存储在硬盘,保证数据不会因进程退出而丢失。
缺点
单机故障,无法保证数据的安全
读写操作无法负载均衡
容量瓶颈,存储能力受到限制
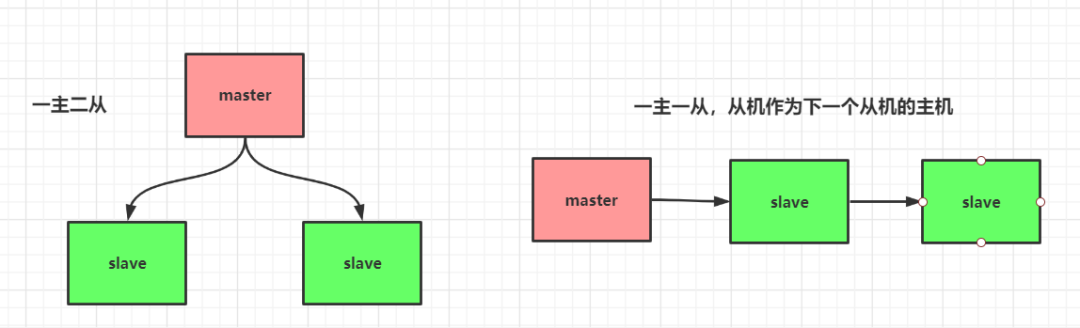
2、主从复制
复制是高可用 Redis 的基础,哨兵和集群都是在复制基础上实现高可用的。复制主要实现了数据的多机备份(容灾备份),以及对于读操作的负载均衡(写操作仍然在主机)和简单的故障恢复。
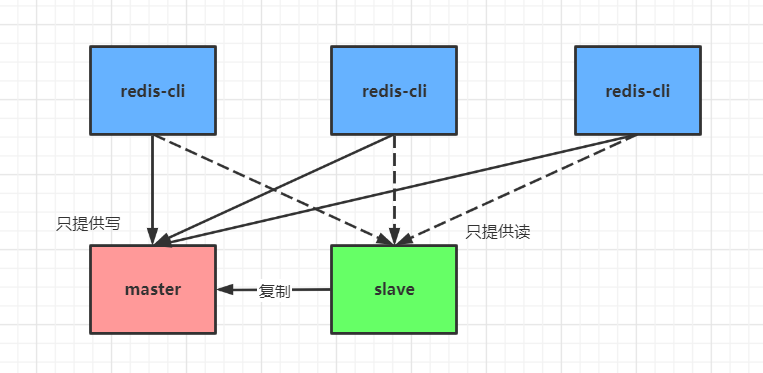
master:写操作
slave:读操作(负载均衡),不能写
配置
公共配置(端口,文件保存路径,根据环境配置)
bind 0.0.0.0
port 6000
daemonize yes
pidfile "/home/eric/redis-masterslave/redis6000/redis_6000.pid"
logfile "/home/eric/redis-masterslave/redis6000/redis.log"
dbfilename "dump.rdb"
dir "/home/eric/redis-masterslave/redis6000"
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
配置主机地址与密码(配从不配主)
masterauth:主要是针对 master 对应的 slave 节点设置的,在 slave 节点数据同步的时候用到。
requirepass:对登录权限做限制,redis 每个节点的 requirepass 可以是独立、不同的。
replicaof 127.0.0.1 6000
masterauth 123456 # 如果主机设置密码的话,需要填写(主机使用 requirepass, 从机使用 masterauth)
查看节点信息
127.0.0.1:6000> info replication
配置建议
主机通常不配置 RDB 和 AOF 持久化
save ""
appendonly no
工作流程
建立连接
设置 master 的地址和端口,发送 slaveof ip port 指令,master 会返回响应客户端,根据响应信息保存 master 的 run id 和 ip port 信息(连接测试)
根据保存的信息创建连接 master 的 socket
周期性发送 ping,master 会相应 pong
发送指令 auth password(身份验证),master 验证身份
发送 slave 端口信息,master 保存 salve 端口号
数据同步
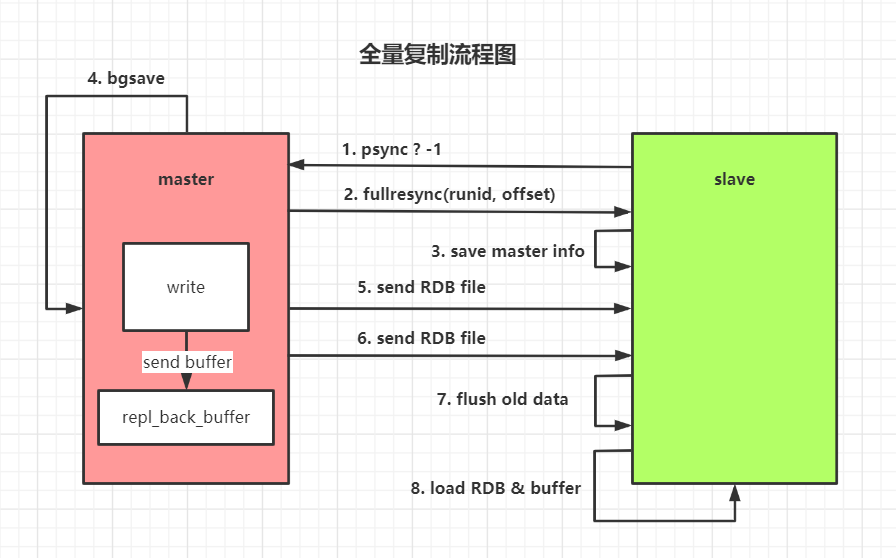
slave 发送指令 psync2(psync2 run_id -1)
主机返回当前的 runid 和 offset 给 salve
salve 保存主机的相关信息
master 执行 bgsave
在第一个 salve 连接时,创建命令缓存区
生产 RDB 文件,通过 socket 发送给 slave
slave 接收 RDB 文件,清空数据,执行 RDB 文件恢复过程
发送命令告知 RDB 恢复已经完成(告知全量复制完成)
master 发送复制缓冲区信息
slave 接收信息,执行重写后恢复数据
注意 master 会保存 slave 从我这里拿走了多少数据,保存 slave 的偏移量
全量复制消耗
bgsave 时间
RDB 文件网络传输
从节点请求数据时间
从节点加载 RDB 的时间
可能的 AOF 重写时间
# 查看 runid
127.0.0.1:6001> info server
# Server
...
run_id:ac11dde108fa5288af0f7d72c6c0f20e4611157d
...
# 查看 offset
127.0.0.1:6002> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6000,state=online,offset=3482,lag=1
slave1:ip=127.0.0.1,port=6001,state=online,offset=3482,lag=1
master_repl_offset:3482
...
命令传播
slave 心跳:replconf ack (offset)汇报 slave 自己的 offset,获取最新的数据指令
命令传播阶段出现断网:
1) 网络闪断、闪连:忽略
2) 短时间断网:增量
3) 长时间断网:全量
全量复制核心三个要素
1) 服务器运行ID
用于服务器之间通信验证身份,master 首次连接 slave 时,会将自己的 run id 发送给 slave,slave 保存此 ID
主服务器积压的命令缓冲区
先进先出队列主服务器的复制偏移量
用于比对偏移量,然后判断出执行全量还是增量
切换主从命令
将当前服务器转变为指定服务器的从属服务器
slaveof 127.0.0.1 6000
将从属服务器用作新的主服务器
slaveof no noe
缺点
存储能力受到单机的限制
缺陷是故障恢复无法自动化
写操作无法负载均衡
3、哨兵模式
在 Redis 2.8 版本开始引入,在主从复制的基础上,哨兵实现了自动化的故障恢复。通俗的来说哨兵模式的出现时为了解决主从复制模式中需要人为操作的东西,变为自动操作
功能
监控(Monitoring):哨兵会不断的检查主节点和从节点是否正常工作
自动故障转移(Automatic Failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会选择失效的主节点里其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点中的数据
配置提供者(Configuration Provider):客户端在初始化时,通过连接哨兵来获取当前 Redis 服务的地址
通知(Notification):哨兵可以将故障转移的结果发送给客户端
其中,监控和自动故障转移功能,使得哨兵可以及时发现主节点的故障并完成转移,而配置提供者和通知功能,则需要在与客户端交互中才能体现
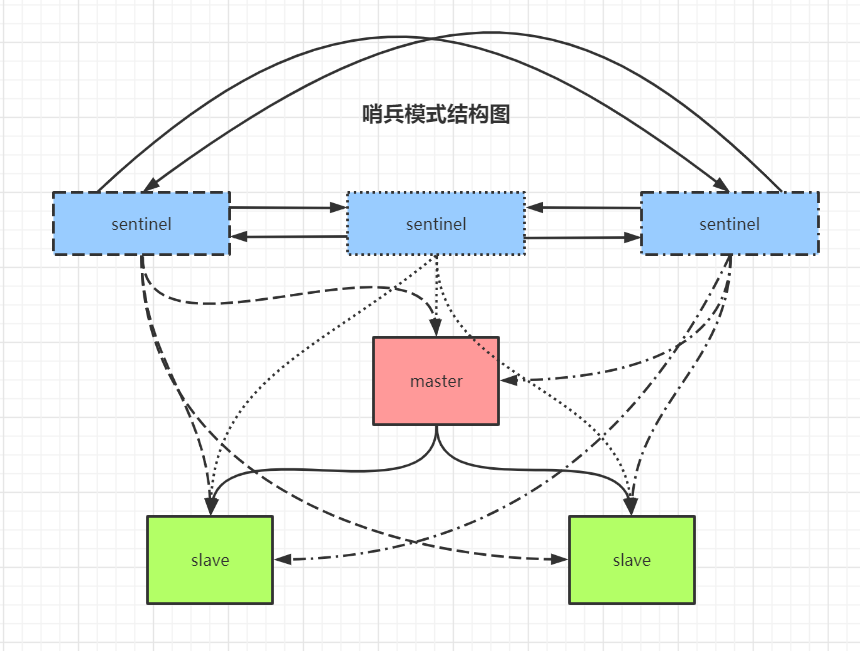
架构
哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的 Redis 节点,不存储数据
数据节点:主节点和从节点都是数据节点
配置
配置哨兵
复制 sentinel.conf 至目标目录下,并进行修改
bind 0.0.0.0
port 8000
daemonize yes
pidfile /home/eric/redis-sentinel/redis8000/redis-sentinel-8000.pid
logfile "/home/eric/redis-sentinel/redis8000/sentinel-8000.log"
dir /home/eric/redis-sentinel/redis8000
sentinel monitor mymaster 127.0.0.1 7000 2
# sentinel auth-pass <master-name> <password>
其中 sentinel monitor mymaster 127.0.0.1 7000 2 的含义是:该节点监控 127.0.0.1 7000 这个主节点,该主节点的名称定义为 mymaster,最后的 2 的含义与主节点故障判定有关,即至少需要 2 个哨兵同意(认为该主机点已经不能提供服务),才能判断该主节点发生故障并进行故障转移。
配置数据(主从)节点
同主从配置
启动
启动数据(主从)节点
哨兵系统的主从节点与普通的主从节点配置完全相同,并不需要做额外的处理
replicaof <masterip> <masterport>
启动哨兵
redis-sentinel ./redis8000/sentinel.conf
redis-sentinel ./redis8001/sentinel.conf
redis-sentinel ./redis8002/sentinel.conf
当发送故障转移的时候,哨兵会自己修改配置文件中的 sentinel monitor 配置
客户端(Jedis)访问哨兵系统
Set<String> set = new HashSet<>();
set.add("127.0.0.1:8000");
set.add("127.0.0.1:8001");
set.add("127.0.0.1:8002");
JedisSentinelPool jedisSentinelPool= new JedisSentinelPool("mymaster", set, "pwd");
Jedis jedis = jedisSentinelPool.getResource();
jedis.set("key", "value");
原理
相关概念
主观下线:在心跳检测的定时任务中,如果其他节点超过一定的时间没有响应,哨兵节点就会将其进行主观下线,顾名思义,主观下线是一个哨兵节点“主观的”判断下线,与其对应的是客观下线
客观下线:哨兵节点在对主节点进行主观下线后,会通过 sentinel is-maste-down-by-addr 命令询问其他哨兵节点该主节点的状态,如果判断主节点下线的哨兵达到一定数量后,则对该主节点进行客观下线
需要注意的是:客观下线是主节点才有的概念,如果哨兵发现从节点故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
定时任务:每个哨兵节点维护了 3 个定时任务,定时任务的功能分别如下:
每 10 秒通过向该主节点发送 info 命令获取最新的主从结构
发现 slave 节点
确定主从关系每 2 秒通过发布/订阅功能获取其他哨兵的信息
每 1 秒通过向其他节点发送 ping 命令,进行心跳检测,判断是否下线(Monitor)
选举领导者哨兵节点
当主节点被判断客户下线后,各个哨兵会协商,选举出一个领导者哨兵节点,并由改领导者节点对其进行故障转移操作。
监视改主节点的哨兵都有可能成为领导者,选举使用的算法是 Raft 算法,Raft 算法的思路是先到先得,即在一轮选举中,哨兵 A 向哨兵 B 发送称为领导者的申请,如果哨兵 B 没有同意过其他哨兵,则会同意哨兵 A 成为领导者,选举的过程很快,通常,谁先完成客观下线,一般就能成为领导者,成为领导者后,就可以开始进行故障转移,即选举新的主节点
选举主节点原则
1、首先过滤掉不健康的从节点(ping 不通,或延迟比较久)
2、过滤掉响应慢的从节点
3、过滤掉与 master 断开时间最久的从节点
4、优先原则
优先选择优先级最高(replica-priority)的从节点
如果优先级无法区分,则选择复制偏移量最大的从节点(偏移量越大,表示与主机数据越接近)
如果仍无法区分,则选择 runid 最小的从节点
实践建议
哨兵节点数量应不止一个,一方面增加哨兵节点的冗余,避免哨兵节点成为高可用的瓶颈,另一方面减少对客观下线的误判,此外哨兵节点通常放再不同的物理主机上
哨兵节点数量最好是奇数,以便于哨兵通过投票选出“领导者”以及对客观下线的“决策”
各个哨兵节点配置应保持一致,包括硬件、网络等参数,此外应保证时间的准确性
缺点
存储能力受到单机的限制
写操作无法负载均衡
4、Redis Cluster 高可用集群
通过集群,Redis 解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案
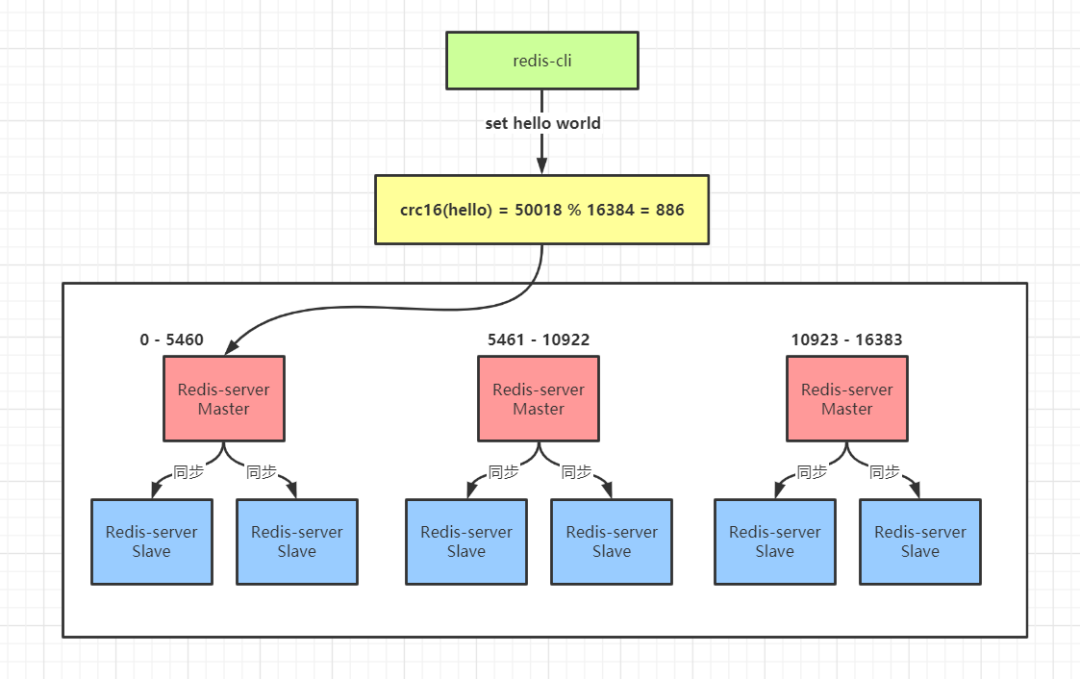
Redis Cluster 集群是一个由多个主从节点群组成的分布式服务器群(至少要有 3 个主节点),它具有复制、高可用和分片特性。Redis Custer 集群不需要 sentinel 哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到 1000 节点。Redis Cluster 集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单
集群搭建
redis-cli --cluster help
原生搭建
1) 基本配置文件
bind 0.0.0.0
port 7000
daemonize yes
pidfile /home/eric/redis-cluster/redis7000/redis_7000.pid
logfile "/home/eric/redis-cluster/redis7000/redis_7000.log"
dir /home/eric/redis-cluster/redis7000/
masterauth 123456
requirepass 123456
2) 配置开启 cluster 节点(集群配置)
cluster-enabled yes(启动集群模式)
cluster-config-file nodes-7000.conf(节点配置文件,这里 7000 最好和 port 对应上)
cluster-require-full-coverage no (主机宕机了,且没有从机可进行故障转移,那么整个集群是否可以继续使用)
# 替换配置文件
sed 's/7000/7001/g' redis7000/redis.conf > redis7001/redis.conf
sed 's/7000/7002/g' redis7000/redis.conf > redis7002/redis.conf
...
sed 's/7000/7005/g' redis7000/redis.conf > redis7005/redis.conf
# 启动
redis-server ./redis7000/redis.conf
redis-server ./redis7001/redis.conf
redis-server ./redis7002/redis.conf
redis-server ./redis7003/redis.conf
redis-server ./redis7004/redis.conf
redis-server ./redis7005/redis.conf
# 检查进程启动情况
ps -ef | grep redis
eric 252 1 0 13:32 ? 00:00:00 redis-server 0.0.0.0:7000 [cluster]
eric 257 1 0 13:32 ? 00:00:00 redis-server 0.0.0.0:7001 [cluster]
eric 262 1 0 13:32 ? 00:00:00 redis-server 0.0.0.0:7002 [cluster]
eric 267 1 0 13:32 ? 00:00:00 redis-server 0.0.0.0:7003 [cluster]
eric 272 1 0 13:32 ? 00:00:00 redis-server 0.0.0.0:7004 [cluster]
eric 277 1 0 13:32 ? 00:00:00 redis-server 0.0.0.0:7005 [cluster]
eric 282 7 0 13:32 tty1 00:00:00 grep --color=auto redis
# 测试连接
redis-cli -h 127.0.0.1 -p 7000 -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:7000> set k1 v1
(error) CLUSTERDOWN Hash slot not served // 没有分配槽位,所以不能添加数据
127.0.0.1:7000> cluster nodes
7b777e4abce4e3427dd9a7a42721e46bdc42af88 :7000@17000 myself,master - 0 0 0 connected
3) meet
让所有的集群相互认识(通讯)
cluster meet ip port
cluster meet 127.0.0.1 7001
cluster meet 127.0.0.1 7002
4) 指派槽
查看 crc16 算法算出 key 的槽位命令 cluster keyslot key
cluster keyslot key
16384/3 0-5461 5462-10922 10923-16383
16384/4 4096
cluster addslots slot(槽位下标)
5) 分配主从
cluster replicate node-id
使用 redis-cli 配置集群
Redis Cluster 集群需要至少要三个 master 节点,我们这里搭建三个 master 节点,并且给每个 master 再搭建一个 slave 节点,总共 6 个 Redis 节点。
由于节点数较多,这里采用在一台机器上创建 6 个 Redis 实例,并将这 6 个 Redis 实例配置成集群模式,所以这里搭建的是伪集群模式,当然真正的分布式集群的配置方法几乎一样
查看集群命令:
redis-cli --cluster help
1、分配主机
create host1:port1 … hostN:portN --cluster-replicas
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1 -a 123456
其中--cluster-replicas 1 表示 6 个节点按 1:1 分配,那么就是 3 个 master 节点,3 个 slave 节点,如果 --cluster-replicas 2 则 6 个节点表示按照 1:2 分配,那么就会使 2 个 master 节点,4 个 slave 节点,如果这样依赖,则不满足最少 3 个 master 节点,就会失败
主节点:取最前面的
从节点:依次取后面的,做为主节点的从节点,随机分配
槽位:根据主机数量,平均分配
查看节点状态
redis-cli -h 127.0.0.1 -p 7000 -a 123456 cluster nodes
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
7fd64ce350df005c963ab355e7e5551b00c6dc7e 127.0.0.1:7002@17002 master - 0 1599406449000 2 connected 5461-10922
fe9183edd29a1c1c9a34eccc1b638f46a1c59aab 127.0.0.1:7005@17005 slave 87e7956a0513ea3da005c78224d728e3cd77f609 0 1599406448000 3 connected
87e7956a0513ea3da005c78224d728e3cd77f609 127.0.0.1:7003@17003 master - 0 1599406450945 3 connected 10923-16383
4f9d051cb178f5078df51eb6e52f1be3ae30a2d2 127.0.0.1:7001@17001 myself,master - 0 1599406449000 1 connected 0-5460
43d57aff953c58a223a528c689ec6a397eb85481 127.0.0.1:7006@17006 slave 4f9d051cb178f5078df51eb6e52f1be3ae30a2d2 0 1599406449938 1 connected
3f468212653a046626e2869aeff46ee9bcb61c4a 127.0.0.1:7004@17004 slave 7fd64ce350df005c963ab355e7e5551b00c6dc7e 0 1599406451954 2 connected
以集群方式登录
-C 代表以集群方式登录,写值成功后会自动跳转到所属主机,否则就是以正常方式登录,当写数据时,可能会提示 hash 计算的槽位,并不属于当前主机
redis-cli -h 127.0.0.1 -p 7000 -a 123456 -c
127.0.0.1:7000> set k1 v1
-> Redirected to slot [12706] located at 127.0.0.1:7002
OK
127.0.0.1:7002> keys *
1) "k1"
扩容和缩容
启动需要加入集群的节点
redis-server ./redis7006/redis.conf
redis-server ./redis7007/redis.conf
添加节点
add-node new_host:new_port existing_host:existing_port --cluster-slave --cluster-master-id
添加 master 节点
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 -a 123456
添加 slave 节点
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7000 --cluster-slave --cluster-master-id master的ID -a 123456
分配槽位
reshard host:port --cluster-from
利用导航模式分配,根据提示一步一步完成
要分配的槽位数 -> 接收槽位的 node id -> 分配策略(all / 指定要分出槽位的 node id)-> done -> yes
all:所有节点平均分配
输入要分配的 node id -> 继续输入要分配的 node id -> … -> done
redis-cli --cluster reshard 127.0.0.1:7000 -a 123456
删除节点
1、先对槽位进行缩容
redis-cli --cluster reshard 127.0.0.1:7000
--cluster-from 要迁移的节点ID --cluster-to 要接收的节点ID --cluster-slots 要迁出的槽位数量
再进行删除
删除的时候,通常都是先删除从节点,然后再删除主节点,否则会进行故障转移,发生不必要的资源浪费
redis-cli --cluster del-node 127.0.0.1:7000 要删除的节点ID -a 123456
source: https://www.yuque.com/nashihuakai/qlwgtg/zk5qz7
公众号后台回复「搜索」即可搜索你所需要的文章;
公众号后台回复「wx」添加杰哥微信即可加入读者交流群;
Redis 相关文章推荐:
杰哥的另一个公众号,主要分享关于个人成长经历的那点事,欢迎您的关注。
