
2021 年了,机器/深度学习还有哪些坑比较好挖?
导读
深度学习以及机器学习发展至今,涌入了大量的人才和资源,有很多方向已经达到了一个瓶颈,短时间内有非常大的突破有些难以实现。那么对于有学术要求与指标的学生来说,还有哪些方向可以去深挖呢?
# 回答一
作者:张趔趄
康奈尔大学 电子与计算机博士在读
来源链接:https://www.zhihu.com/question/440538267/answer/1719126442
例如MRI扫描加速。在纽约,在医院扫一次MRI,大概要2k刀左右,具体跟你需要的sequence还可能有关系。如果你能在不损失图像质量和信息的情况下对其进行加速,将具备巨大的经济价值。想当年的compressed sensing和衍生出来的sparse representation,dictionary learning等在deep learning era之前的火爆程度,这不就说明这里面解决到的是fundamental的问题,其原理不仅可以加速MRI扫描,也可以被泛化应用到其他地方,从而产生很大的影响力。
又例如medical image reconstruction, 大多数这样的问题都是ill-posed,传统解法是formulate成一个优化问题,加上一些constraint/prior,从而求解。然而这些图像每个人扫出来的虽细节不一样,但是呢大体结构又类似,那么如何让深度/机器学习能更好的学习到prior然后来更快更好的解这些优化问题呢?如果这个问题能被解决,那是不是可以直接应用到其他类似需要领域呢,
在医学图像里有一类优化问题,自身存在结构,虽然from scratch去优化可以得到正确的结果,但是深度学习是不是可以更好的去approximate这些优化问题,利用自身的提取特征的能力来助力这些优化?让模型学习到这些结构,然后在之后的优化中就可以进一步提升速度。让深度网络变成一个优化器。比如我的一个co-authro Mert Sabuncu提出的VoxelMorph,用来深度学习来实现image registration; 比如另一个co-author,Jinwei提出的用fidelity loss来对没有见过的数据进行refine.
又比如做medical image analysis的第一步,往往是对ROI进行segmentation,如何真正的利用人体结构的相似性来更好的让模型学习到一些结构,而不是直接迁移一些自然图像里的方法呢?
# 回答二
作者:微调
CMU博士在读
来源链接:https://www.zhihu.com/question/440538267/answer/1717701231
最容易的就是做交叉application,算法A在任务B上的表现等。如果发会议就能毕业的话,ccf的c类会议里有相当一部分都有>40%接受率(ICANN,IJCNN,ICPR等),你魔改一点网络结构去尝试解决一个没人在乎的问题,只要写的别太拉胯就硕士毕业了。我举一些不存在的例子,如何使用「魔改的RCNN」(这个可以替换为任何经典模型)解决「室内建筑通风能力预测」的问题。再来一个,如何集成「多个自编码器」提升「图片中太阳花」的检测率。再来一个,如何用「自监督学习」来发现「海洋图片中的污染情况评估」。怎么找应用看你有没有啥合适的数据,有的话多的是脑洞应用。不行的话,翻翻这个答案随便找点数据:机器学习需要的大量数据集从哪里找?(https://www.zhihu.com/question/342295029/answer/915272899)其实这类没啥意义的文章其实才是泛学术圈的主流,我们不鼓励这类内容,但也明白很多人只是为了毕业,不丢人。
或者现在很多人也喜欢大规模的比较和benchmark,比如讨论20种聚类算法在100个数据上的一些表现啥的。然后有些“惊人”的发现,比如原来某个领域20年来都没啥新进展。比如mlsys20上这篇arxiv.org/pdf/2003.0303 ,研究了81篇文章里的pruning的方法。
再来,就是做数据集,你去UCI上看看各种各样的数据集,能不能把它们改成其他任务的。比如把分类任务改成聚类的,把回归改成检测。很多会议也喜欢新的数据集,尤其是大数据集,或者多个数据集。
 的概率是正确的。
的概率是正确的。# 回答三
作者:金雪锋
MindSpore首席架构师
来源链接:https://www.zhihu.com/question/440538267/answer/1699917805
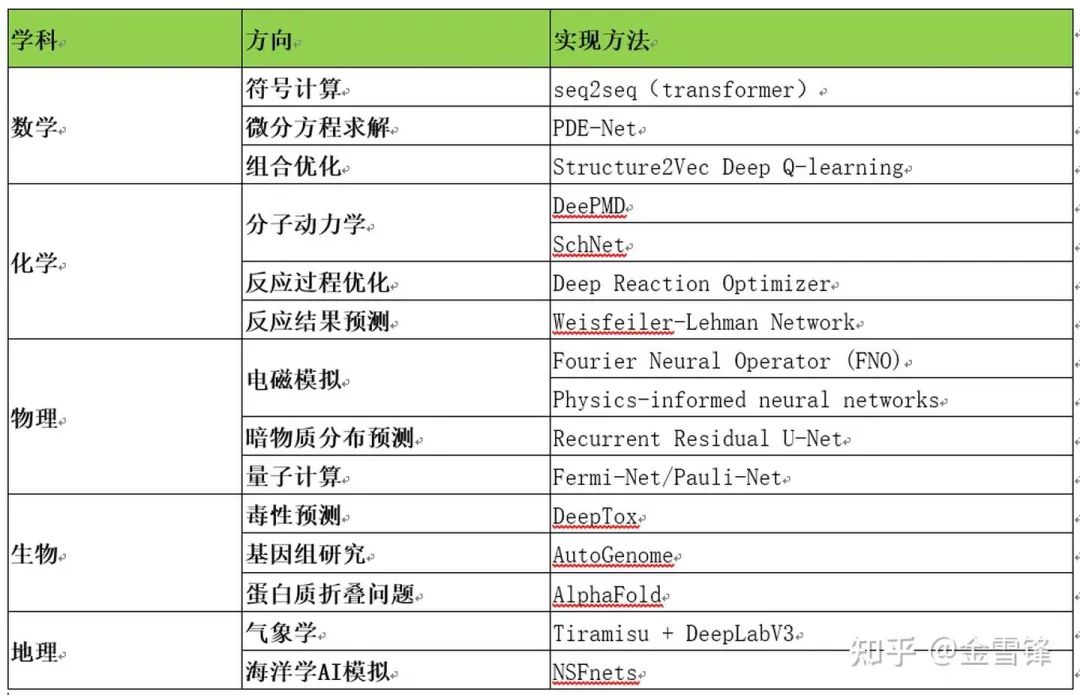
往期精彩:
点个在看