
每个数据科学家该知道的五种检测异常值方法(附Python代码)
大数据文摘授权转载自数据派THU

什么是异常值?
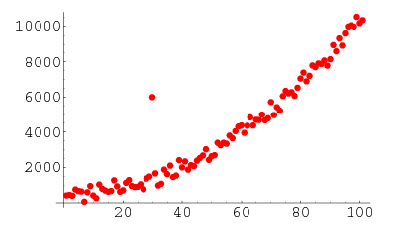
为什么我们要关注异常值?
检测异常值是数据挖掘中的核心问题之一。数据的不断扩增和持续增长,以及物联网设备的普及,让我们重新思考处理异常值的方法和观测异常值构建出的用例。
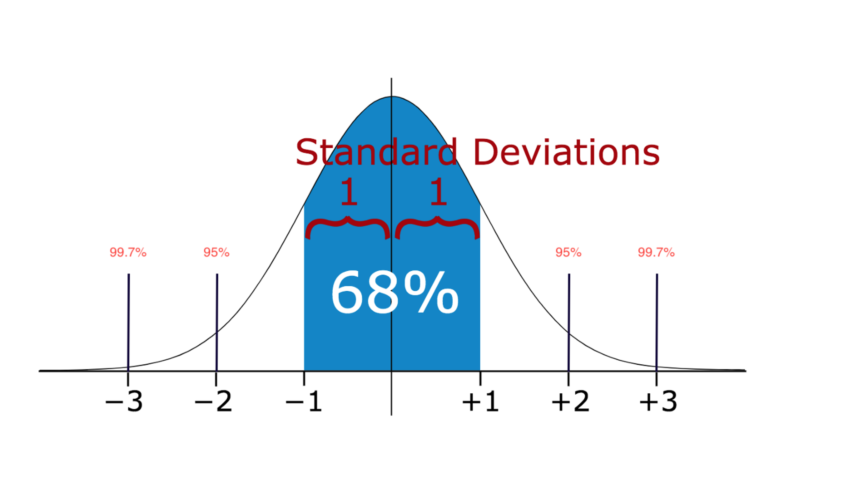
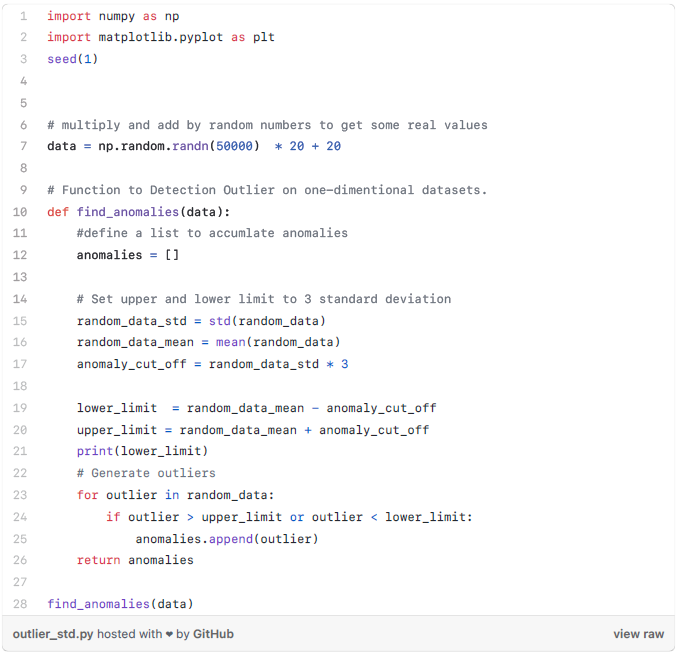
方法1——标准差:
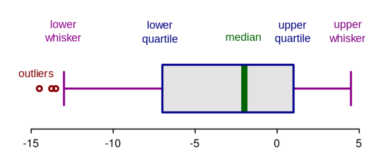
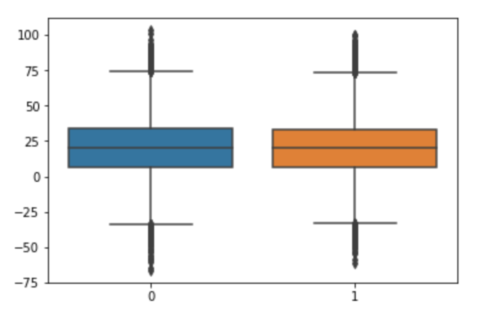
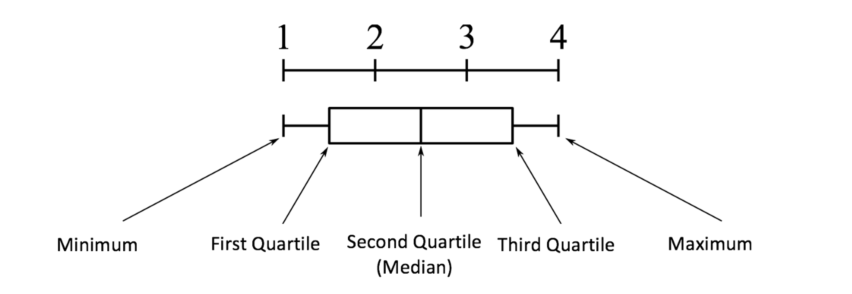
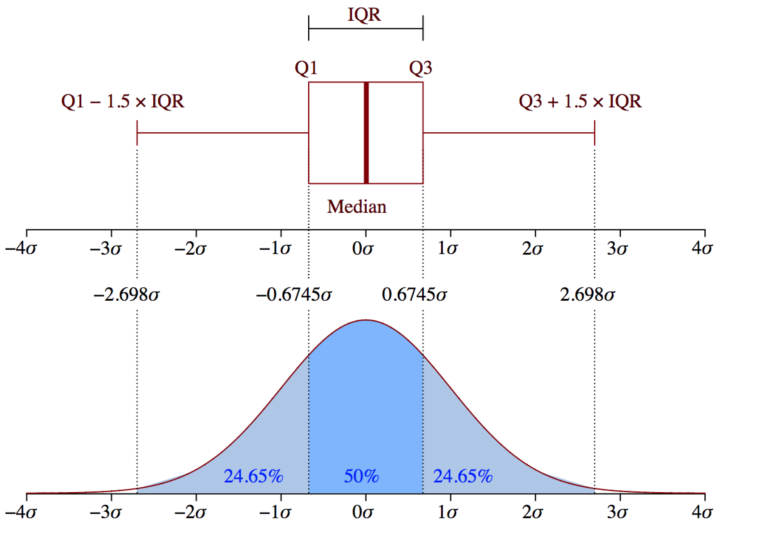
方法2——箱线图:

方法3——DBScan集群:
核心点:为了理解核心点,我们需要访问一些用于定义DBScan工作的超参数。第一个超参数是最小值样本(min_samples)。这只是形成集聚的核心点的最小数量。第二重要的超参数eps,它是两个被视为在同一个簇中的样本之间的最大距离。
边界点:是与核心点在同一集群的点,但是要离集群中心远得多。
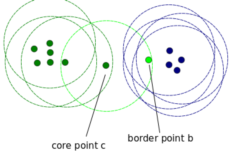
其他的点被称为噪声点,那些数据点不属于任何集群。它们可能是异常点,可能是非异常点,需要进一步调查。现在让我们看看代码。
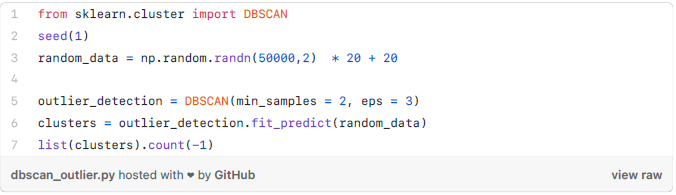
方法4——孤立森林
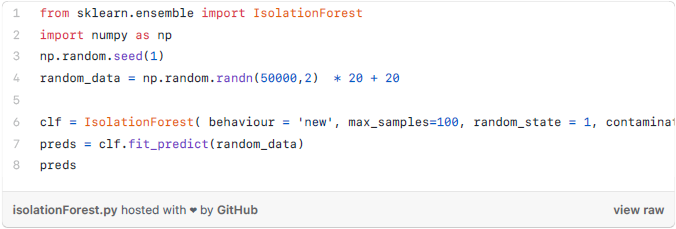
方法5——Robust Random Cut Forest
结论
评论