
神经网络如何「动」起来?| 「动态神经网络」的六大待解难题

极市导读
本文详细介绍了动态神经网络的相关工作及其两个大类,最后提出了目前动态神经网络依然存在的难题。这一领域依然处于起步阶段,仍然有诸多开放问题和研究方向值得我们探讨。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
近年来我们不断见证了越来越强大的神经网络模型,如 AlexNet,VGG,GoogleNet,ResNet,DenseNet 以及最近大火的 Transformer 等。
这些神经网络使用的流程,基本可以概括为:1) 固定网络架构,初始化网络参数;2) 训练阶段:在训练集上优化网络参数;3) 推理阶段:固定网络架构与参数,输入测试样本进行前向传播,得到预测结果。
这种范式导致训练完成后,在测试阶段,对所有的输入样本,均采用相同的网络架构与参数进行推理。 这在一定程度上限制了模型的表征能力、推理效率和可解释性。
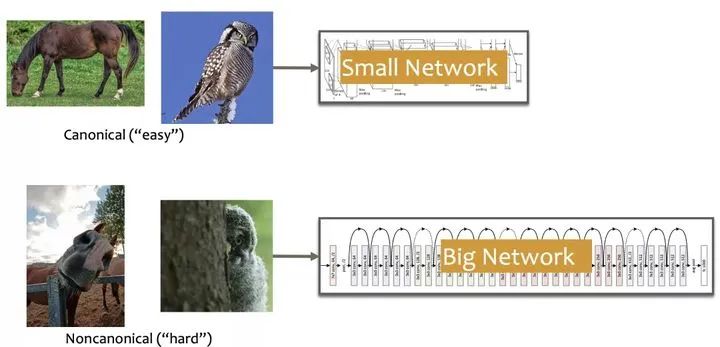
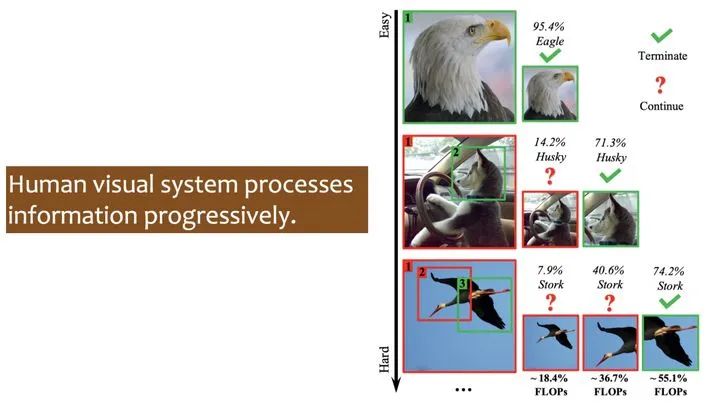
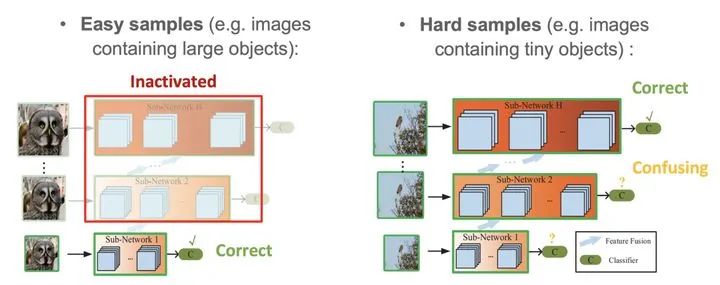
一个非常明显的例子,如下图所示,对于常见的「马」或「猫头鹰」的图片,也许只需要一个小的网络便可以正确识别;然而对于「非经典」的「马」或「猫头鹰」的图片,则需要训练一个大的网络才能正确识别。
再例如,如下图所示,对一张包含「猫」的图片进行识别,我们可以看到,提高分辨率确实可以提高准确率,但同时也伴随着计算量的极速提升。人们自然期望是否可以在不严重影响准确率的情况下,降低输入样本的分辨率,从而来节省计算量。

将这一系列要求「自适应推理」的问题总结起来,便是所谓「动态神经网络」的研究范畴。
与静态网络不同的是,动态网络的本质在于,在处理不同测试样本时,能够动态地调节自身的结构/参数,从而在推理效率、表达能力、自适应性等方面展现出卓越的优势。
内容目录
一、神经网络,如何动起来?
1)样本自适应动态网络
动态结构
动态参数
2)空间自适应动态网络
像素级
区域级
分辨率级
3)时间自适应动态网络
二、六大开放问题
1)结构设计;
2)更多样任务下的适用性;
3)实际效率与理论的差距;
4)鲁棒性;
5)可解释性;
6)动态网络理论。
01、神经网络,如何动起来?
最为经典的做法是,以串行或并行的方式,构建多个模型的动态集成,然后根据输入样本自适应地激活其中某个模型。
实际上围绕这一思想,目前已有大量相关研究工作,大致可以分为几种类别,包括「样本自适应动态网络」、「空间自适应动态网络」和「时间自适应网络」。
1)样本自适应动态网络
样本自适应动态网络对每个输入样本进行自适应计算。根据网络动态变化的主体,其主要可以分为两大类:动态结构与动态参数。
前者主要是为了在处理「简单」样本时分配更少的计算资源从而提升运算效率;而后者主要是为了在增加尽可能少计算量的情况下,提升模型表达能力。
动态结构
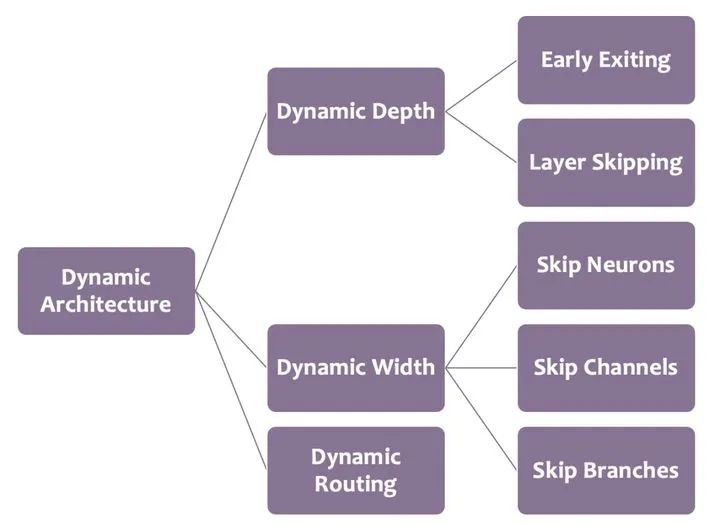
结构上的动态有两个维度,一个是深度,一个是宽度。
深度上的动态,即网络层数的变化。由于几乎所有的网络都由多个网络层堆叠而成,一个比较自然的实现动态结构的思路就是针对不同样本,选择性地执行不同的网络层。
这有两类思路:早退机制和跳层机制。
所谓「早退机制」,即在模型中间层设置出口,并根据每个样本在这些中间出口处的输出,自适应的决定对样本的推理过程是否提前退出。早退机制相当于跳过了某一分类器之后所有层的运算。
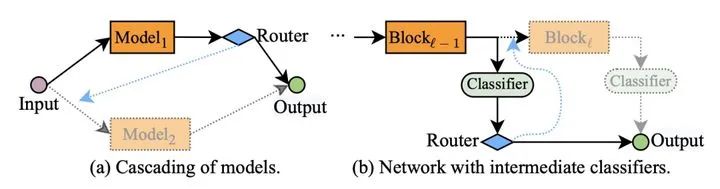
跳层机制则相对比较灵活,它会针对每个输入样本,自适应地决定网络的每个中间层是否执行。

在网络「宽度」这一维度上的动态,从不同尺度上,可以分为神经元的动态激活,动态通道剪枝和多专家混合系统(也即MoE)。
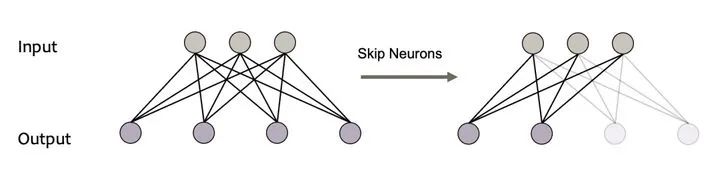
神经元的动态激活,容易理解,如下图所示,通常可以通过低秩分解等方式控制线性层中的神经元的激活。
CNN中的动态通道剪枝,相较于静态剪枝方法将某些“不重要”的通道永久性的去除,前者可以根据样本自适应地激活不同的卷积通道,从而在保持模型容量的情况下实现计算效率的提升。
多专家混合系统,则是通过并行结构建立多个“专家”,这些专家可以是完整模型,也可以是网络模块,然后对这些「专家」的输出结果进行动态加权,来得到最终的预测结果。
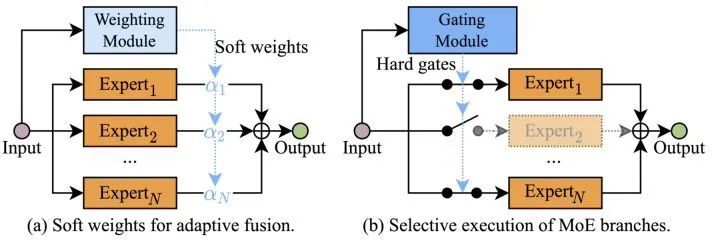
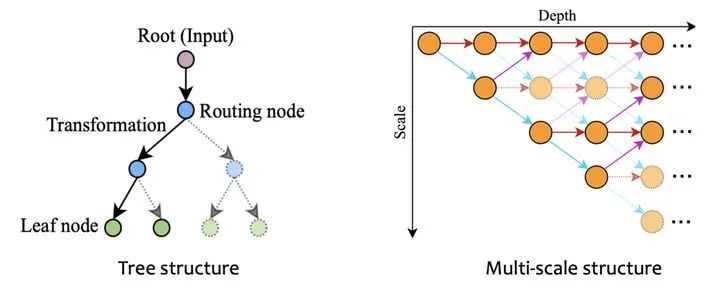
除了在网络的广度和深度上进行动态自适应外,另外还有一类工作则是首先建立具有多条前向通道的超网络 (SuperNet),然后采用一定的策略,对不同的输入样本进行动态路由。
参数动态
具有动态结构的网络往往需要特别的结构设计、训练策略或超参数的调整等。另一类工作则保持网络结构在推理过程中不变,根据输入样本自适应地调节模型的(部分)参数,从而提升模型的表达能力。
设静态网络的推理过程可表示为
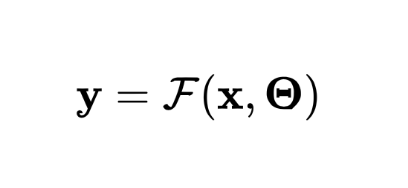
则具有动态参数的网络输出可表示为
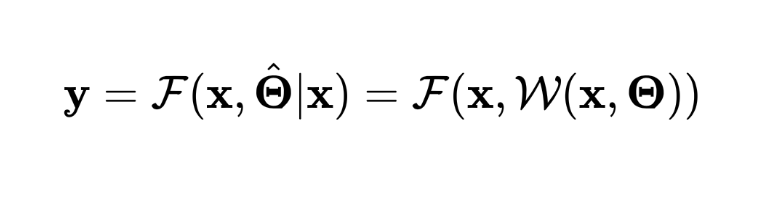
其中 是产生动态参数的操作。
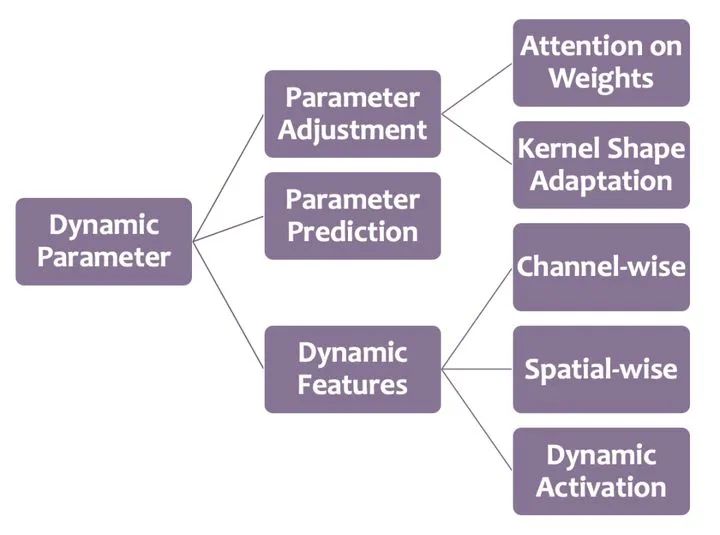
总体来说,动态参数类的研究可以分为三大类:参数的动态调节,参数预测以及基于注意力的动态特征。
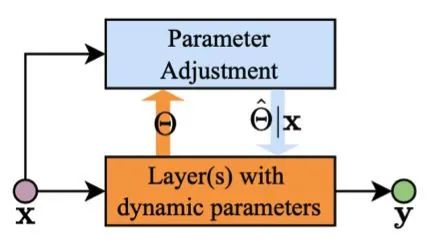
参数动态调节的核心思路有两个:1)对主干网络的参数,在测试阶段使用注意力进行重新加权,从而提升网络的表达能力;2)自适应调节卷积核的形状,从而让网络拥有动态感受野。
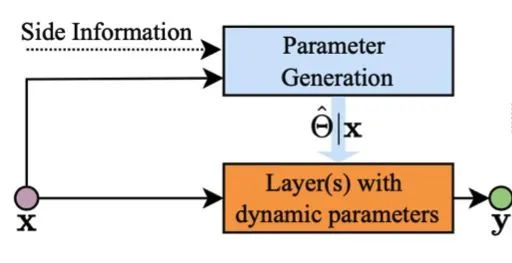
参数预测比动态调节方式更为直接,它会直接由输入来预测生成网络的(部分)参数。
动态参数方法的主要效果是生成更加动态与多样的特征,从而提升模型的表达能力。为实现这一目的,一个等效的解决方案是直接针对特征进行动态加权。
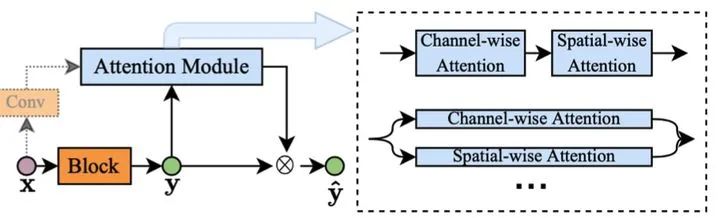
对于一个线性变换 ,对其输出进行加权,得到的结果等效于先对参数加权,再执行该变换,即
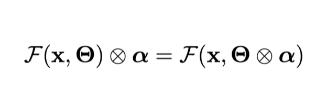
除了通道以外,注意力也可以被用来对特征的不同空间位置进行自适应加权。这两种注意力范式(通道、空间)可以被以多种形式组合起来进一步提升模型表达能力。
上述动态特征方法通常在非线性激活函数(如 ReLU)前对特征进行重新加权。近期也有一些工作直接设计动态激活函数,并替换传统网络中的静态激活函数 ,同样能够大幅提高模型的表达能力。
2)空间自适应动态网络
在视觉任务中,已有研究表明输入中不同的空间位置对CNN的最终预测起着不同的作用。也就是说,做一个精确的预测,可能只需要自适应的处理输入中一部分空间位置,而无需对整张输入图像的不同位置进行相同计算量的运算。

另有研究表明,对输入图像仅使用较低的分辨率,已经可以使网络取得不错的准确率。因此,传统CNN中对所有输入图像采用相同分辨率表征的做法会带来无可避免的冗余计算。
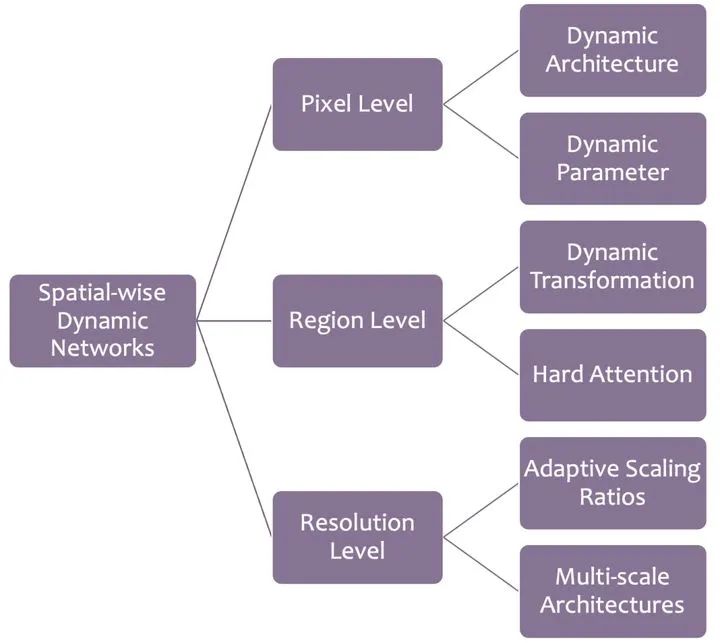
为此,可以设计空间自适应的动态网络,对图像输入从空间的角度进行自适应推理。根据动态运算的粒度,可以将空间自适应网络分为三个级别:像素级,区域级以及分辨率级。
像素级
像素级动态网络,即对输入特征图的每个空间位置进行自适应计算。针对这种问题,同样可以从动态结构和动态参数两个角度来做。
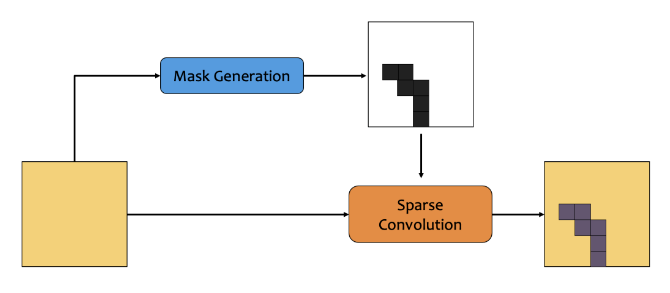
像素级动态结构网络,顾名思义,即对不同的像素点,调用不同的网络模块,从而避免在背景区域等与任务无关的区域上进行冗余计算。
而针对参数,基本可以将前述的几种动态参数方法运用到这里。
区域级
像素级动态网络中的稀疏采样操作往往导致模型在实际运行中难以取得理论上的加速效果。区域级动态网络则从原输入中选择一块整体区域进行自适应计算。
具体的,区域级动态网络可以分为两种类型。第一种基于输入图像学习一组变换(如仿射、投影等)参数,并对原图(部分区域)进行参数化的变换,从而提升模型对图像畸变的鲁棒性,或者对图像中任务相关的区域进行放大 ,从而提升模型识别的准确率。
第二种类型则采用空间硬注意力机制,自适应的选择输入中包含重要目标的图像块,将该图像块裁剪下来进行识别。
具体流程可以如下:
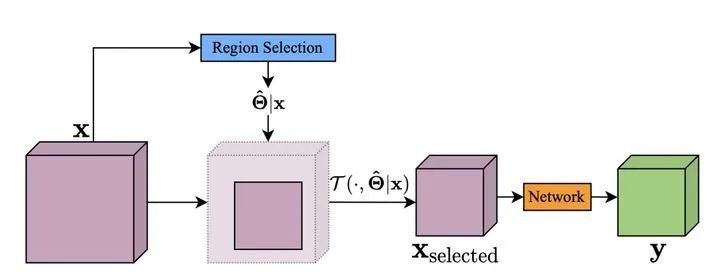
分辨率级
上述工作通常需要将一张输入图像划分为不同区域,并对每个区域进行自适应计算。其中的稀疏采样/裁剪操作往往会影响模型实际运行时的效率。
分辨率级的动态网络则不同,它会将每张输入样本仍然作为整体来处理,但为了减少“简单”样本的高分辨率表征带来的冗余计算,会对不同的输入图像采用动态分辨率进行数据表示。
动态分辨率主要有两种实现思路,一种是动态的放缩比例,一种则是采用多尺度架构。
3)时间自适应动态网络
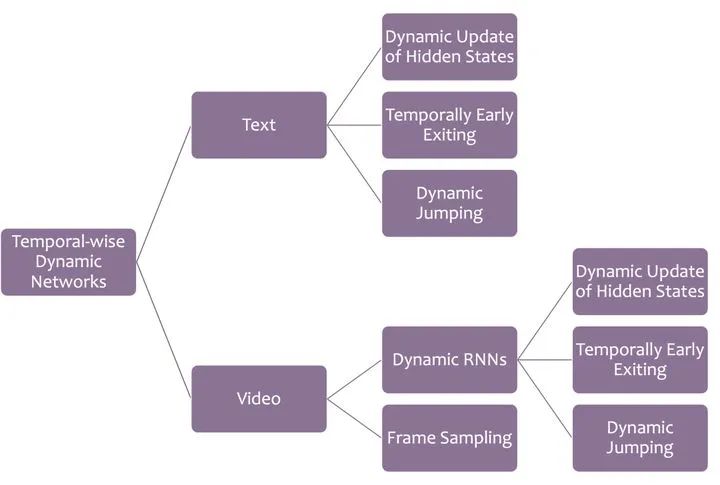
时序数据(如文本、视频等)在时间维度上具有较大的冗余性。因此,设计一个动态网络,针对不同时间位置的数据进行自适应计算,将使得网络本身更加高效。

总体来说,时间自适应动态网络可以从两个方面减少冗余计算:1)对于某些「不重要」位置的输入,分配较少的计算;2)仅在一部分采样出的时间位置上执行计算。
常规的静态 RNN对于长度为 T 的时序数据处理流程为,迭代式地更新其隐状态,即
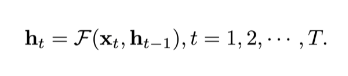
然而,由于不同时刻的输入对于任务的贡献程度(重要性)不同 ,对每个时刻的输入均采用相同复杂度的操作会导致无法避免的冗余计算。因此,可以设计不同形式的动态 RNN,根据不同时刻的输入自适应地决定是否分配计算,或者采用何等复杂度的计算。
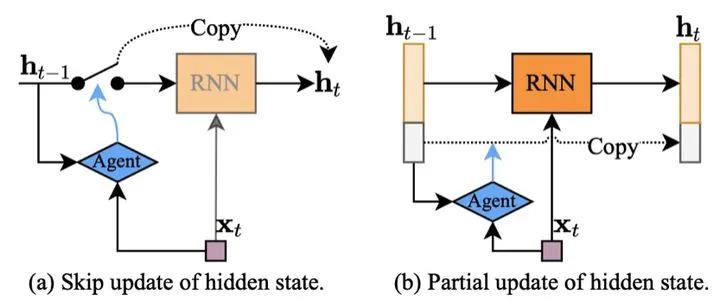
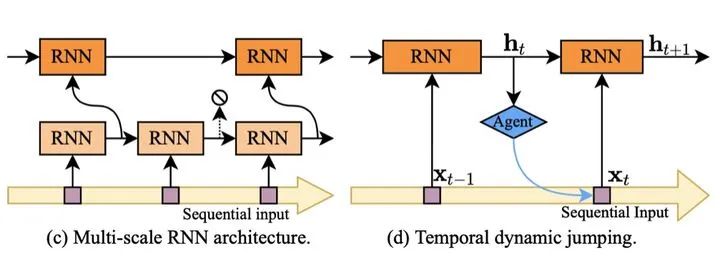
第一种方式是隐状态的动态更新。考虑到不同时刻输入数据的重要性不同,可以在RNN的每一个时间步,采用自适应计算的方式更新其隐状态,例如可以跳过隐状态的更新,或进行粗略的更新,再或者采用多尺度架构进行选择性更新。
但这种方式依然需要将所有时刻的样本输入进去,然后再进行自适应地计算所需的决策。在很多场景中,只根据时序数据的开头就可以解决所需的问题。例如,人类只需阅读文章的摘要就可以对文章的大意有一定的了解。因此可以采用「早退」机制,在某一中间时刻提前终止「阅读」。
「早退」机制中网络只能决定是否终止运算,但却不能决定去「看」输入中哪些位置的数据。如果能够采用前文提到的「跳跃」机制,则能够跳过一定数量的输入。
02、开放问题
动态神经网络,其优点显而易见。特别是当下,市场急需将深度学习模型部署到各个移动终端,如何使用更小的模型,耗费更少的计算量,且还能够确保足够高的精度,这些迫切需求正推动着动态神经网络的研究大踏步向前。
但尽管如此,这一领域依然处于起步阶段,仍然有诸多开放问题和研究方向值得探讨,我们认为有以下六大问题:
1、动态网络结构设计。 目前大多数网络结构方面的工作致力于设计静态网络,而多数动态网络设计方法也都是基于已有的经典静态模型架构,选择性的执行其中的不同单元。这对于动态网络的结构设计可能只是一个次优解。因此,针对于自适应计算的动态网络结构设计可以进一步提升其性能和运算效率。
2、更多样任务下的适用性。 目前大多数动态网络仍只是针对分类任务设计,难以直接运用于其他视觉任务,如目标检测和语义分割。其难点在于这些任务中没有一个简单的准则来判断样本的难易程度,而一个样本中又包含多个不同复杂度的目标/像素点。现有的一些方法,如空间自适应网络,已经可以用于分类之外的更多任务。然而,设计一个统一而简洁优雅,并可以直接作为其他任务主干网络的动态网络结构仍然具有一定的挑战性。
3、实际效率与理论的差距。 现有的深度学习计算硬件和软件库大多针对静态模型开发,对于动态模型的加速尚不够友好,从而导致动态模型的实际加速可能落后于理论效果。因此,设计硬件友好的动态网络是一个有价值和挑战性的课题。另一个有趣的方向则是进一步优化计算硬件和软件平台,从而更好的收获动态网络带来的理论效率提升。
4、鲁棒性。 近期工作已经显示,动态模型可以为深度网络的鲁棒性带来新的研究角度。另外,通常的对抗攻击致力于降低模型准确率,而对于动态网络,可以同时攻击模型的准确率和效率。因此,动态网络的鲁棒性是一个有趣而尚未被充分研究的课题。
5、可解释性。 动态网络继承了深度神经网络的「黑箱」特性,带来了解释其工作机制的研究方向。特别之处在于,动态网络的自适应推理机制,如空间/时间上的自适应性,与人类的视觉系统相符合。另外,对于一个给定样本,可以很方便的分析动态网络做出预测需要激活哪些部分。我们期望这些性质可以启发新的深度学习可解释性方面的工作。
6、动态网络理论。 包括:1)最优决策问题:决策是大多数动态网络推理过程中一个本质性的操作。现有方法(基于置信度、策略网络或门函数)均缺乏一定的理论保障,且并不一定是最优的决策方式。因此,设计具有理论保障的决策函数是未来很有价值的研究方向。2)泛化性能。在动态模型中,不同的子网络被不同的测试样本激活,导致这些子网络在训练和测试阶段所面临数据分布存在一定偏差。因此,对于动态网络泛化性能的新理论将是一个有趣的课题。
本文亮点总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
