
Java Map中那些巧妙的设计
最近拜读了一些Java Map的相关源码,不得不惊叹于JDK开发者们的鬼斧神工。他山之石可以攻玉,这些巧妙的设计思想非常有借鉴价值,可谓是最佳实践。然而,大多数有关Java Map原理的科普类文章都是专注于“点”,并没有连成“线”,甚至形成“网状结构”。因此,本文基于个人理解,对所阅读的部分源码进行了分类与总结,归纳出Map中的几个核心特性,包括:自动扩容、初始化与懒加载、哈希计算、位运算与并发,并结合源码进行深入讲解,希望看完本文的你也能从中获取到些许收获(本文默认采用JDK1.8中的HashMap)。
一 自动扩容
最小可用原则,容量超过一定阈值便自动进行扩容。
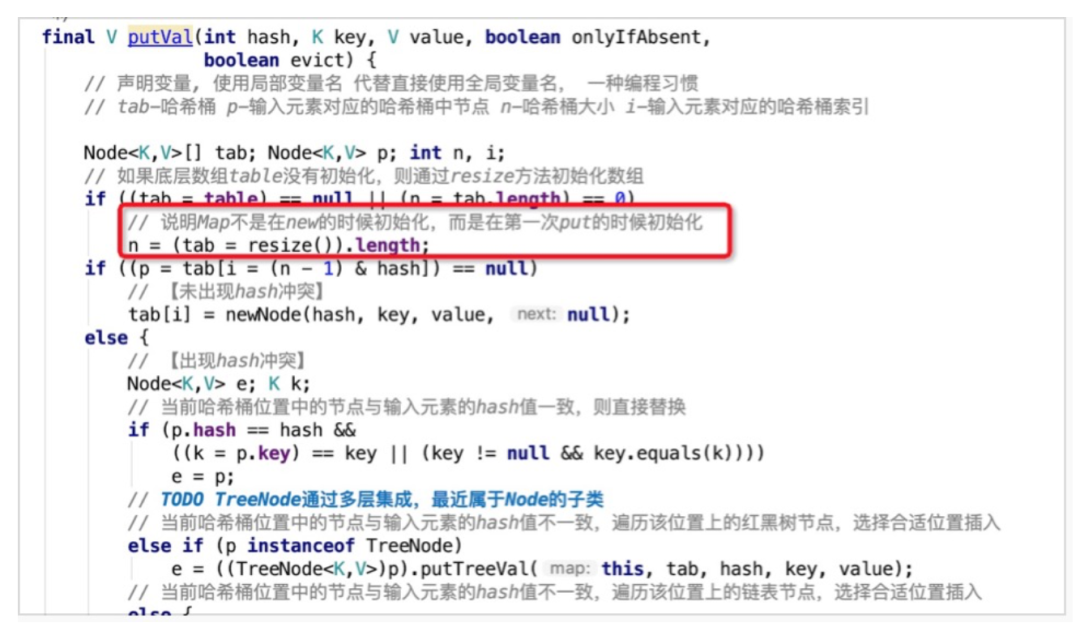
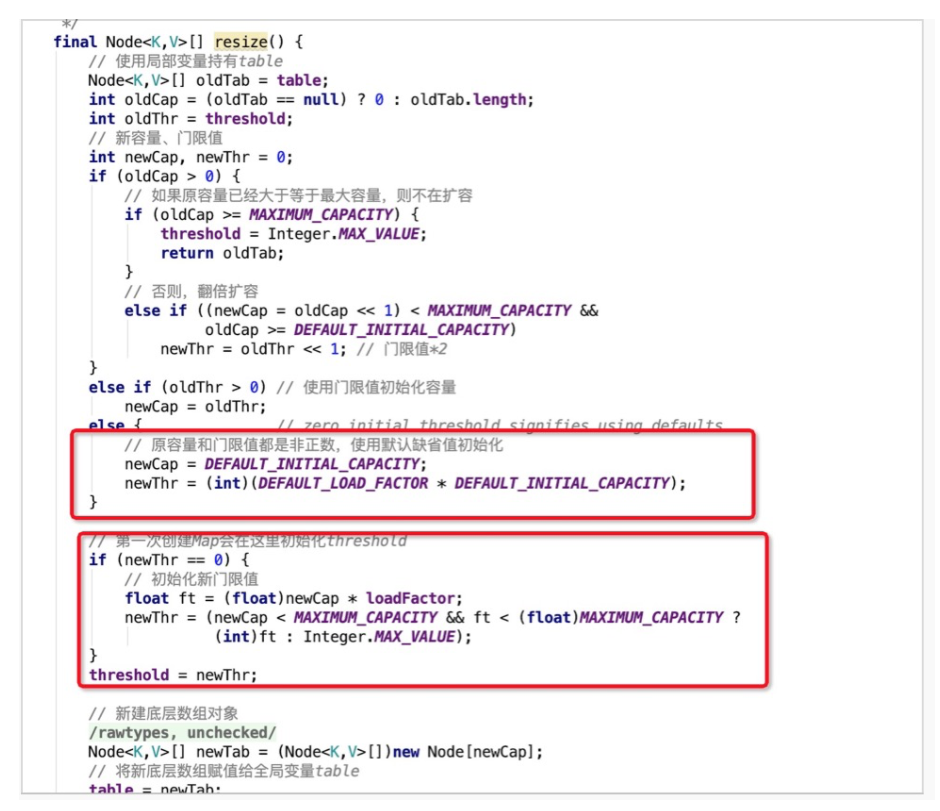
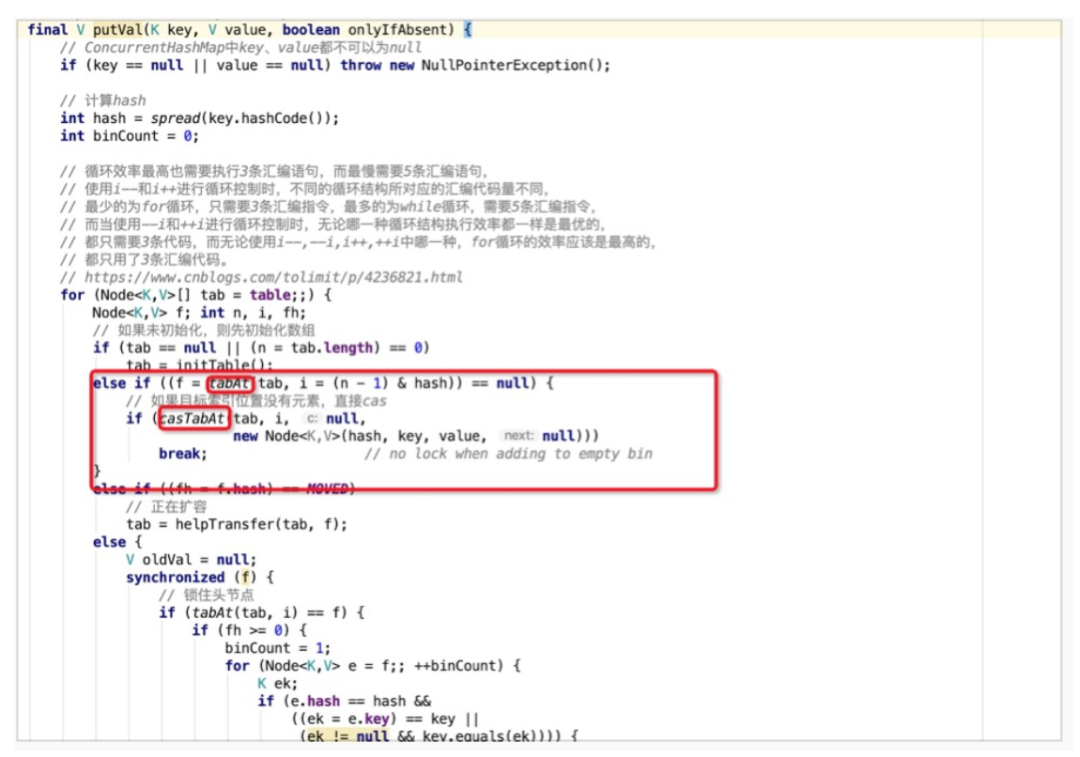
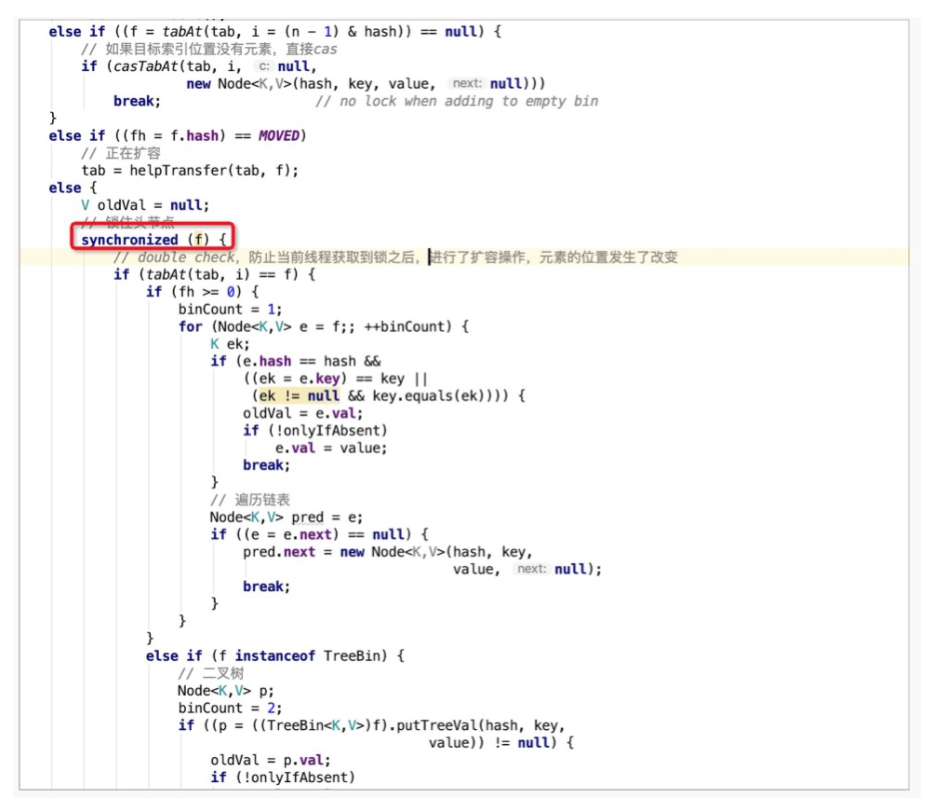
扩容是通过resize方法来实现的。扩容发生在putVal方法的最后,即写入元素之后才会判断是否需要扩容操作,当自增后的size大于之前所计算好的阈值threshold,即执行resize操作。

通过位运算<<1进行容量扩充,即扩容1倍,同时新的阈值newThr也扩容为老阈值的1倍。

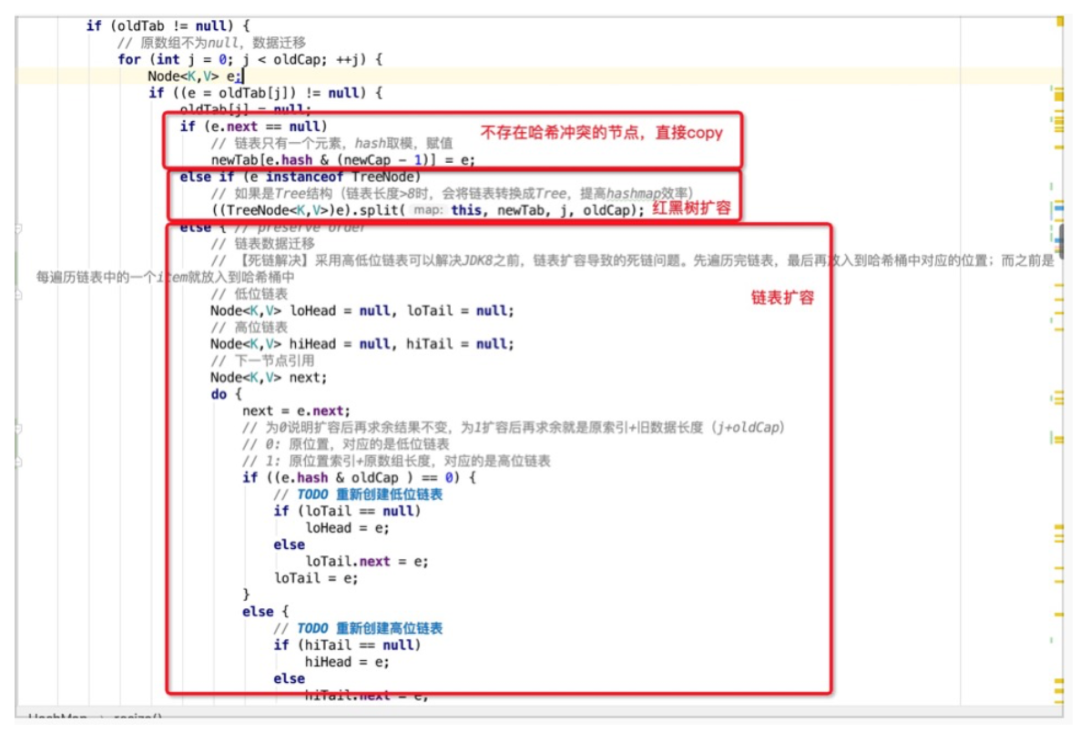
扩容时,总共存在三种情况:
哈希桶数组中某个位置只有1个元素,即不存在哈希冲突时,则直接将该元素copy至新哈希桶数组的对应位置即可。
哈希桶数组中某个位置的节点为树节点时,则执行红黑树的扩容操作。
哈希桶数组中某个位置的节点为普通节点时,则执行链表扩容操作,在JDK1.8中,为了避免之前版本中并发扩容所导致的死链问题,引入了高低位链表辅助进行扩容操作。
HashMap hashMap = new HashMap(2);hashMap.put("1", 1);hashMap.put("2", 2);hashMap.put("3", 3);
初始化的时候只会设置默认的负载因子,并不会进行其他初始化的操作,在首次使用的时候才会进行初始化。
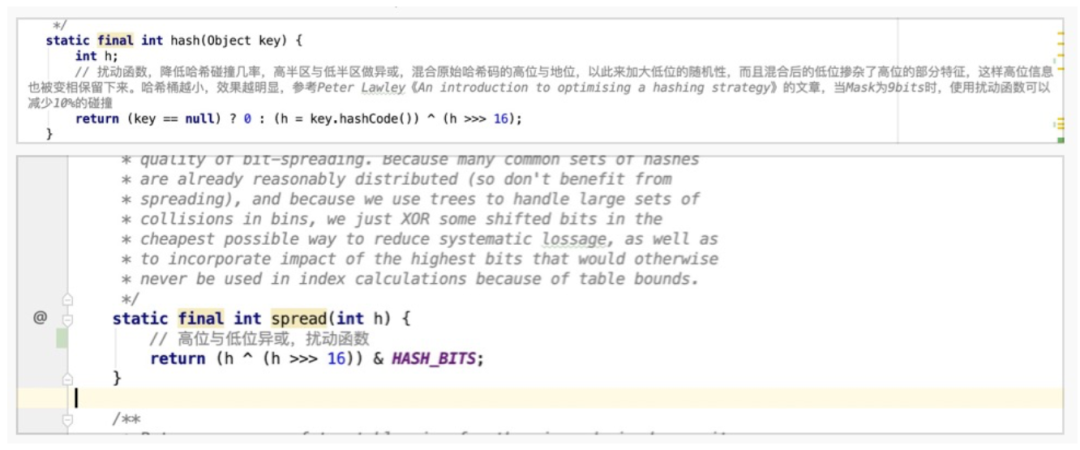
hashCode(key1) = 0000 0000 0000 1111 0000 0000 0000 0010hashCode(key2) = 0000 0000 0000 0000 0000 0000 0000 0010
hashCode(key1) ^ (hashCode(key1) 16)0000 0000 0000 1111 0000 0000 0000 1101hashCode(key2) ^ (hashCode(key2) 16)0000 0000 0000 0000 0000 0000 0000 0010

若不存在冲突,则重新进行hash取模,并copy到新buckets数组中的对应位置。
若存在冲突元素,则采用高低位链表进行处理。通过e.hash & oldCap来判断取模后是落在高位还是低位。举个例子:假设当前元素hashCode为0001(忽略高位),其运算结果等于0,说明扩容后结果不变,取模后还是落在低位[0, 7],即0001 & 1000 = 0000,还是原位置,再用低位链表将这类的元素链接起来。假设当前元素的hashCode为1001, 其运算结果不为0,即1001 & 1000 = 1000 ,扩容后会落在高位,新的位置刚好是旧数组索引(1) + 旧数据长度(8) = 9,再用高位链表将这些元素链接起来。最后,将高低位链表的头节点分别放在扩容后数组newTab的指定位置上,即完成了扩容操作。这种实现降低了对共享资源newTab的访问频次,先组织冲突节点,最后再放入newTab的指定位置。避免了JDK1.8之前每遍历一个元素就放入newTab中,从而导致并发扩容下的死链问题。
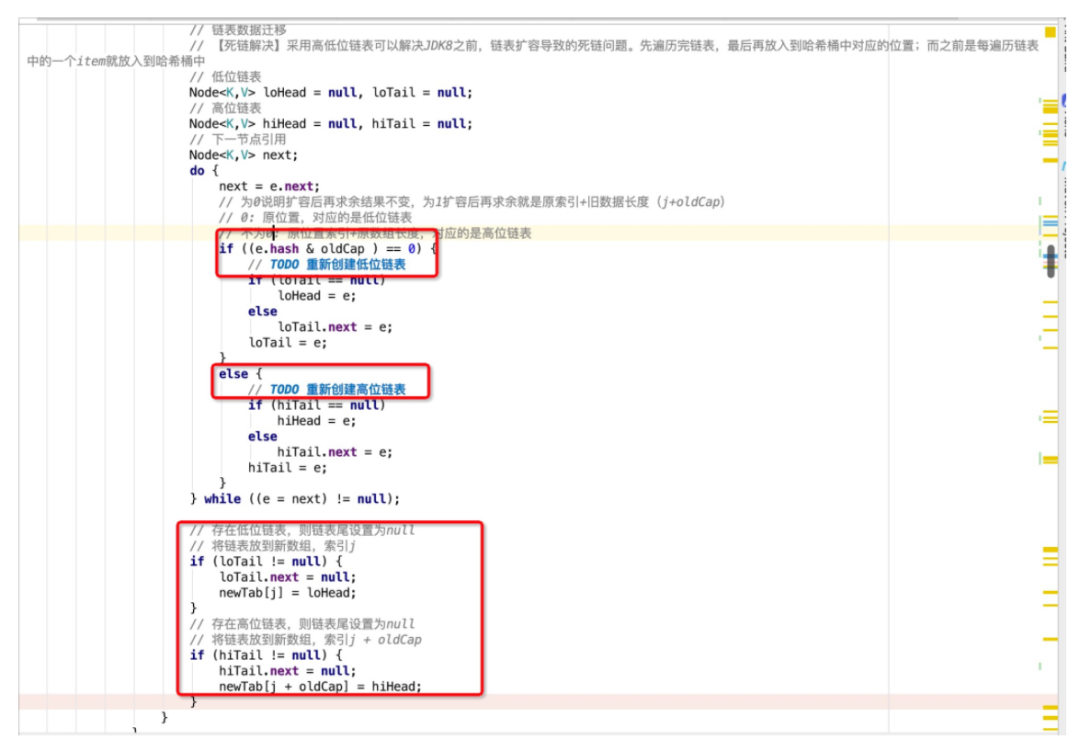
找到大于等于给定值的最小2的整数次幂。

cap = 3n = 2n |= n >>> 1 010 | 001 = 011 n = 3n |= n >>> 2 011 | 000 = 011 n = 3n |= n >>> 4 011 | 000 = 011 n = 3….n = n + 1 = 4
cap = 5n = 4n |= n >>> 1 0100 | 0010 = 0110 n = 6n |= n >>> 2 0110 | 0001 = 0111 n = 7….n = n + 1 = 8
0100 10100111 11111000 0000
获取给定值的最高有效位数(移位除了能够进行乘除运算,还能用于保留高、低位操作,右移保留高位,左移保留低位)。
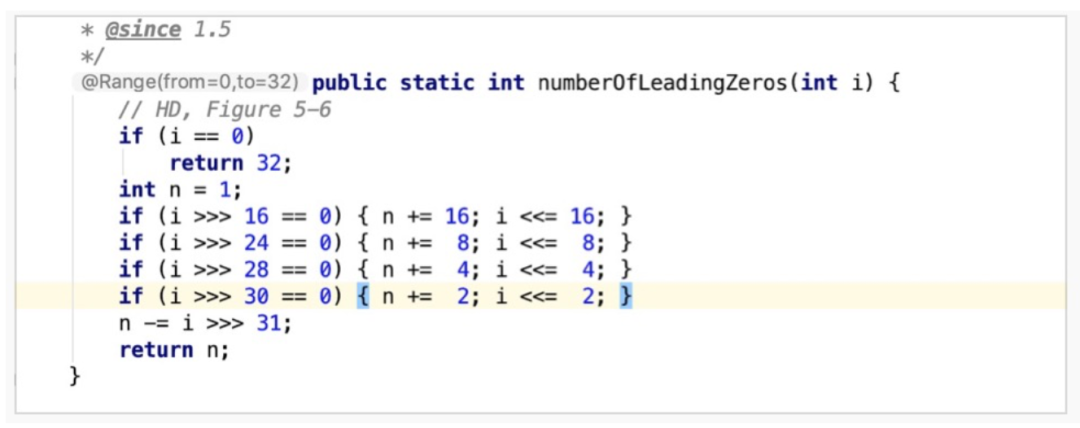
i 16 0000 0000 0000 0000 0000 0000 0000 0100 不为0i 24 0000 0000 0000 0000 0000 0000 0000 0000 等于0
i = 0000 0100 0000 0000 0000 0000 0000 0000i = 0100 0000 0000 0000 0000 0000 0000 0000i 30 0000 0000 0000 0000 0000 0000 0000 0001 不为0i 31 0000 0000 0000 0000 0000 0000 0000 0000 等于0
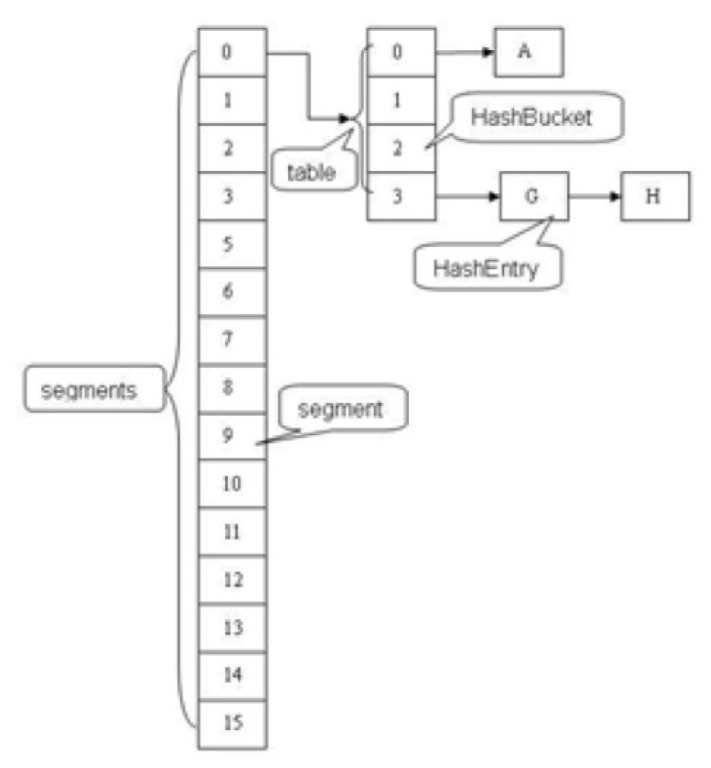
使用segment之后,会增加ConcurrentHashMap的存储空间。
当单个segment过大时,并发性能会急剧下降。


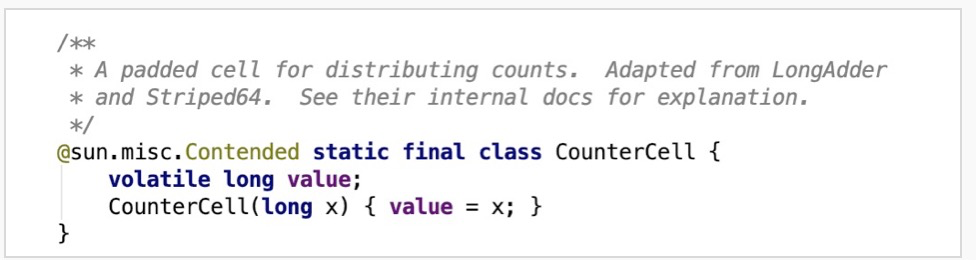
当counterCells不为空,或counterCells为空且对baseCount进行CAS操作失败时进入到后续计数处理逻辑,否则对baseCount进行CAS操作成功,直接返回。
后续计数处理逻辑中会调用核心计数方法fullAddCount,但需要满足以下4个条件中的任意一个:1、counterCells为空;2、counterCells的size为0;3、counterCells对应位置上的counterCell为空;4、CAS更新counterCells对应位置上的counterCell失败。这些条件背后的语义是,当前情况下,计数已经或曾经出现过并发冲突,需要优先借助于CounterCell来解决。若counterCells与对应位置上的元素已经初始化(条件4),则先尝试CAS进行更新,若失败则调用fullAddCount继续处理。若counterCells与对应位置上的元素未初始化完成(条件1、2、3),也要调用AddCount进行后续处理。
这里确定cell下标时采用了ThreadLocalRandom.getProbe()作为哈希值,这个方法返回的是当前Thread中threadLocalRandomProbe字段的值。而且当哈希值冲突时,还可以通过advanceProbe方法来更换哈希值。这与HashMap中的哈希值计算逻辑不同,因为HashMap中要保证同一个key进行多次哈希计算的哈希值相同并且能定位到对应的value,即便两个key的哈希值冲突也不能随便更换哈希值,只能采用链表或红黑树处理冲突。然而在计数场景,我们并不需要维护key-value的关系,只需要在counterCells中找到一个合适的位置放入计数cell,位置的差异对最终的求和结果是没有影响的,因此当冲突时可以基于随机策略更换一个哈希值来避免冲突。

A:表示counterCells已经初始化完成,因此可以尝试更新或创建对应位置的CounterCell。
B:表示counterCells未初始化完成,且无冲突(拿到cellsBusy锁),则加锁初始化counterCells,初始容量为2。
C:表示counterCells未初始化完成,且有冲突(未能拿到cellsBusy锁),则CAS更新baseCount,baseCount在求和时也会被算入到最终结果中,这也相当于是一种兜底策略,既然counterCells正在被其他线程锁定,那当前线程也没必要再等待了,直接尝试使用baseCount进行累加。
a1:对应位置的CounterCell未创建,采用锁+Double Check的策略尝试创建CounterCell,失败的话则continue进行重试。这里面采用的锁是cellsBusy,它保证创建CounterCell并放入counterCells时一定是串行执行,避免重复创建,其实就是使用了DCL单例模式的策略。在CounterCells的创建、扩容中都需要使用该锁。
a2:冲突检测,变量wasUncontended是调用方addCount中传入的,表示前置的CAS更新cell失败,有冲突,需要更换哈希值【a7】后继续重试。
a3:对应位置的CounterCell不为空,直接CAS进行更新。
a4:
冲突检测,当counterCells的引用值不等于当前线程对应的引用值时,说明有其他线程更改了counterCells的引用,出现冲突,则将collide设为false,下次迭代时可进行扩容。 容量限制,counterCells容量的最大值为大于等于NCPU(实际机器CPU核心的数量)的最小2的整数次幂,当达到容量限制时后面的扩容分支便永远不会执行。这里限制的意义在于,真实并发度是由CPU核心来决定,当counterCells容量与CPU核心数量相等时,理想情况下就算所有CPU核心在同时运行不同的计数线程时,都不应该出现冲突,每个线程选择各自的cell进行处理即可。如果出现冲突,一定是哈希值的问题,因此采取的措施是重新计算哈希值a7,而不是通过扩容来解决。时间换空间,避免不必要的存储空间浪费,非常赞的想法~
a5:更新扩容标志位,下次迭代时将会进行扩容。
a6:进行加锁扩容,每次扩容1倍。
a7:更换哈希值。
private final void fullAddCount(long x, boolean wasUncontended) {int h;// 初始化probeif ((h = ThreadLocalRandom.getProbe()) == 0) {ThreadLocalRandom.localInit(); // force initializationh = ThreadLocalRandom.getProbe();wasUncontended = true;}// 用来控制扩容操作boolean collide = false; // True if last slot nonemptyfor (;;) {CounterCell[] as; CounterCell a; int n; long v;// 【A】counterCells已经初始化完毕if ((as = counterCells) != null && (n = as.length) > 0) {// 【a1】对应位置的CounterCell未创建if ((a = as[(n - 1) & h]) == null) {// cellsBusy其实是一个锁,cellsBusy=0时表示无冲突if (cellsBusy == 0) { // Try to attach new Cell// 创建新的CounterCellCounterCell r = new CounterCell(x); // Optimistic create// Double Check,加锁(通过CAS将cellsBusy设置1)if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {boolean created = false;try { // Recheck under lockCounterCell[] rs; int m, j;// Double Checkif ((rs = counterCells) != null &&(m = rs.length) > 0 &&rs[j = (m - 1) & h] == null) {// 将新创建的CounterCell放入counterCells中rs[j] = r;created = true;}} finally {// 解锁,这里为什么不用CAS?因为当前流程中需要在获取锁的前提下进行,即串行执行,因此不存在并发更新问题,只需要正常更新即可cellsBusy = 0;}if (created)break;// 创建失败则重试continue; // Slot is now non-empty}}// cellsBusy不为0,说明被其他线程争抢到了锁,还不能考虑扩容collide = false;}//【a2】冲突检测else if (!wasUncontended) // CAS already known to fail// 调用方addCount中CAS更新cell失败,有冲突,则继续尝试CASwasUncontended = true; // Continue after rehash//【a3】对应位置的CounterCell不为空,直接CAS进行更新else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))break;//【a4】容量限制else if (counterCells != as || n >= NCPU)// 说明counterCells容量的最大值为大于NCPU(实际机器CPU核心的数量)最小2的整数次幂。// 这里限制的意义在于,并发度是由CPU核心来决定,当counterCells容量与CPU核心数量相等时,理论上讲就算所有CPU核心都在同时运行不同的计数线程时,都不应该出现冲突,每个线程选择各自的cell进行处理即可。如果出现冲突,一定是哈希值的问题,因此采取的措施是重新计算哈希值(h = ThreadLocalRandom.advanceProbe(h)),而不是通过扩容来解决// 当n大于NCPU时后面的分支就不会走到了collide = false; // At max size or stale// 【a5】更新扩容标志位else if (!collide)// 说明映射到cell位置不为空,并且尝试进行CAS更新时失败了,则说明有竞争,将collide设置为true,下次迭代时执行后面的扩容操作,降低竞争度// 有竞争时,执行rehash+扩容,当容量大于CPU核心时则停止扩容只进行rehashcollide = true;// 【a6】加锁扩容else if (cellsBusy == 0 &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {// 加锁扩容try {if (counterCells == as) {// Expand table unless stale// 扩容1倍CounterCell[] rs = new CounterCell[n << 1];for (int i = 0; i < n; ++i)rs[i] = as[i];counterCells = rs;}} finally {cellsBusy = 0;}collide = false;continue; // Retry with expanded table}//【a7】更换哈希值h = ThreadLocalRandom.advanceProbe(h);}// 【B】counterCells未初始化完成,且无冲突,则加锁初始化counterCellselse if (cellsBusy == 0 && counterCells == as &&U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {boolean init = false;try { // Initialize tableif (counterCells == as) {CounterCell[] rs = new CounterCell[2];rs[h & 1] = new CounterCell(x);counterCells = rs;init = true;}} finally {cellsBusy = 0;}if (init)break;}// 【C】counterCells未初始化完成,且有冲突,则CAS更新baseCountelse if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))break; // Fall back on using base}
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论