
Scrapy源码剖析:Scrapy如何完成抓取任务?
运行入口
调用 cmdline.py的execute方法找到对应的 命令实例解析命令行构建 CrawlerProcess实例,调用crawl和start方法开始抓取
crawl 方法最终是调用了 Cralwer 实例的 crawl,这个方法最终把控制权交给了Engine,而 start 方法注册好协程池,就开始异步调度执行了。Cralwer 的 crawl 方法:@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 创建爬虫实例
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用spider的start_requests 获取种子URL
start_requests = iter(self.spider.start_requests())
# 调用engine的open_spider 交由引擎调度
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
if six.PY2:
exc_info = sys.exc_info()
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise
spider 的 start_requests 方法,这个方法就是我们平时写的最多爬虫类的父类,它在 spiders/__init__.py 中定义:def start_requests(self):
# 根据定义好的start_urls属性 生成种子URL对象
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
# 构建Request对象
return Request(url, dont_filter=True)
构建请求
start_urls 属性,原来就是在这里用来构建 Request 的,来看 Request 的定义:class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None):
# 编码
self._encoding = encoding
# 请求方法
self.method = str(method).upper()
# 设置url
self._set_url(url)
# 设置body
self._set_body(body)
assert isinstance(priority, int), "Request priority not an integer: %r" % priority
# 优先级
self.priority = priority
assert callback or not errback, "Cannot use errback without a callback"
# 回调函数
self.callback = callback
# 异常回调函数
self.errback = errback
# cookies
self.cookies = cookies or {}
# 构建Header
self.headers = Headers(headers or {}, encoding=encoding)
# 是否需要过滤
self.dont_filter = dont_filter
# 附加信息
self._meta = dict(meta) if meta else None
Request 对象比较简单,就是封装了请求参数、请求方法、回调以及可附加的属性信息。start_requests 和 make_requests_from_url 这 2 个方法,用来自定义逻辑构建种子请求。引擎调度
crawl 方法,构建好种子请求对象后,调用了 engine 的 open_spider:@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
assert self.has_capacity(), "No free spider slot when opening %r" % \
spider.name
logger.info("Spider opened", extra={'spider': spider})
# 注册_next_request调度方法 循环调度
nextcall = CallLaterOnce(self._next_request, spider)
# 初始化scheduler
scheduler = self.scheduler_cls.from_crawler(self.crawler)
# 调用爬虫中间件 处理种子请求
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
# 封装Slot对象
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
# 调用scheduler的open
yield scheduler.open(spider)
# 调用scrapyer的open
yield self.scraper.open_spider(spider)
# 调用stats的open
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
# 发起调度
slot.nextcall.schedule()
slot.heartbeat.start(5)
CallLaterOnce,之后把 _next_request 方法注册了进去,看此类的实现:class CallLaterOnce(object):
# 在twisted的reactor中循环调度一个方法
def __init__(self, func, *a, **kw):
self._func = func
self._a = a
self._kw = kw
self._call = None
def schedule(self, delay=0):
# 上次发起调度 才可再次继续调度
if self._call is None:
# 注册self到callLater中
self._call = reactor.callLater(delay, self)
def cancel(self):
if self._call:
self._call.cancel()
def __call__(self):
# 上面注册的是self 所以会执行__call__
self._call = None
return self._func(*self._a, **self._kw)
twisted 的 reactor 中异步执行,以后执行只需调用 schedule,就会注册 self 到 reactor 的 callLater 中,然后它会执行 __call__ 方法,最终执行的就是我们注册的方法。_next_request,也就是说,此方法会循环调度,直到程序退出。process_start_requests 方法,你可以定义多个自己的爬虫中间件,每个类都重写此方法,爬虫在调度之前会分别调用你定义好的爬虫中间件,来处理初始化请求,你可以进行过滤、加工、筛选以及你想做的任何逻辑。调度器
Scheduler 的 open:def open(self, spider):
self.spider = spider
# 实例化优先级队列
self.mqs = self.pqclass(self._newmq)
# 如果定义了dqdir则实例化基于磁盘的队列
self.dqs = self._dq() if self.dqdir else None
# 调用请求指纹过滤器的open方法
return self.df.open()
def _dq(self):
# 实例化磁盘队列
activef = join(self.dqdir, 'active.json')
if exists(activef):
with open(activef) as f:
prios = json.load(f)
else:
prios = ()
q = self.pqclass(self._newdq, startprios=prios)
if q:
logger.info("Resuming crawl (%(queuesize)d requests scheduled)",
{'queuesize': len(q)}, extra={'spider': self.spider})
return q
open 方法中,调度器会实例化出优先级队列,以及根据 dqdir是否配置,决定是否使用磁盘队列,最后调用了请求指纹过滤器的 open 方法,这个方法在父类 BaseDupeFilter 中定义:class BaseDupeFilter(object):
# 过滤器基类,子类可重写以下方法
@classmethod
def from_settings(cls, settings):
return cls()
def request_seen(self, request):
# 请求过滤
return False
def open(self):
# 可重写 完成过滤器的初始化工作
pass
def close(self, reason):
# 可重写 完成关闭过滤器工作
pass
def log(self, request, spider):
pas
RFPDupeFilter 过滤器实现过滤重复请求的逻辑,这里先对这个类有个了解,后面会讲具体是如何过滤重复请求的。Scraper
Scraper 的 open_spider 方法,在之前的文章中我们提到过,Scraper 类是连接 Engine、Spider、Item Pipeline 这 3 个组件的桥梁:@defer.inlineCallbacks
def open_spider(self, spider):
self.slot = Slot()
# 调用所有pipeline的open_spider
yield self.itemproc.open_spider(spider)
Scraper 调用所有 Pipeline 的 open_spider 方法,如果我们定义了多个 Pipeline 输出类,可以重写 open_spider 完成每个 Pipeline 在输出前的初始化工作。循环调度
open 方法后,最后调用了 nextcall.schedule() 开始调度,也就是循环执行在上面注册的 _next_request 方法:def _next_request(self, spider):
# 此方法会循环调度
slot = self.slot
if not slot:
return
# 暂停
if self.paused:
return
# 是否等待
while not self._needs_backout(spider):
# 从scheduler中获取request
# 注意:第一次获取时,是没有的,也就是会break出来
# 从而执行下面的逻辑
if not self._next_request_from_scheduler(spider):
break
# 如果start_requests有数据且不需要等待
if slot.start_requests and not self._needs_backout(spider):
try:
# 获取下一个种子请求
request = next(slot.start_requests)
except StopIteration:
slot.start_requests = None
except Exception:
slot.start_requests = None
logger.error('Error while obtaining start requests',
exc_info=True, extra={'spider': spider})
else:
# 调用crawl,实际是把request放入scheduler的队列中
self.crawl(request, spider)
# 空闲则关闭spider
if self.spider_is_idle(spider) and slot.close_if_idle:
self._spider_idle(spider)
def _needs_backout(self, spider):
# 是否需要等待,取决4个条件
# 1. Engine是否stop
# 2. slot是否close
# 3. downloader下载超过预设
# 4. scraper处理response超过预设
slot = self.slot
return not self.running \
or slot.closing \
or self.downloader.needs_backout() \
or self.scraper.slot.needs_backout()
def _next_request_from_scheduler(self, spider):
slot = self.slot
# 从scheduler拿出下个request
request = slot.scheduler.next_request()
if not request:
return
# 下载
d = self._download(request, spider)
# 注册成功、失败、出口回调方法
d.addBoth(self._handle_downloader_output, request, spider)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
def crawl(self, request, spider):
assert spider in self.open_spiders, \
"Spider %r not opened when crawling: %s" % (spider.name, request)
# request放入scheduler队列,调用nextcall的schedule
self.schedule(request, spider)
self.slot.nextcall.schedule()
def schedule(self, request, spider):
self.signals.send_catch_log(signal=signals.request_scheduled,
request=request, spider=spider)
# 调用scheduler的enqueue_request,把request放入scheduler队列
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signal=signals.request_dropped,
request=request, spider=spider)
_next_request 方法首先调用 _needs_backout 检查是否需要等待,等待的条件有以下几种情况:引擎是否主动关闭 Slot是否关闭 下载器在网络下载时是否超过预设参数 Scraper处理输出是否超过预设参数
_next_request_from_scheduler,此方法从名字上就能看出,主要是从 Schduler 中获取 Request。Scheduler 中是没有放入任何 Request 的,这里会直接break 出来,执行下面的逻辑,而下面就会调用 crawl 方法,实际是把请求放到 Scheduler 的请求队列,放入队列的过程会经过请求过滤器校验是否重复。_next_request_from_scheduler 时,就能从 Scheduler 中获取到下载请求,然后执行下载动作。crawl:def crawl(self, request, spider):
assert spider in self.open_spiders, \
"Spider %r not opened when crawling: %s" % (spider.name, request)
# 放入Scheduler队列
self.schedule(request, spider)
# 进行下一次调度
self.slot.nextcall.schedule()
def schedule(self, request, spider):
self.signals.send_catch_log(signal=signals.request_scheduled,
request=request, spider=spider)
# 放入Scheduler队列
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signal=signals.request_dropped,
request=request, spider=spider)
crawl 实际就是把请求放入 Scheduler 的队列中,下面看请求是如何入队列的。请求入队
Scheduler 请求入队方法:def enqueue_request(self, request):
# 请求入队 若请求过滤器验证重复 返回False
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
# 磁盘队列是否入队成功
dqok = self._dqpush(request)
if dqok:
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
# 没有定义磁盘队列 则使用内存队列
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
def _dqpush(self, request):
# 是否定义磁盘队列
if self.dqs is None:
return
try:
# Request对象转dict
reqd = request_to_dict(request, self.spider)
# 放入磁盘队列
self.dqs.push(reqd, -request.priority)
except ValueError as e: # non serializable request
if self.logunser:
msg = ("Unable to serialize request: %(request)s - reason:"
" %(reason)s - no more unserializable requests will be"
" logged (stats being collected)")
logger.warning(msg, {'request': request, 'reason': e},
exc_info=True, extra={'spider': self.spider})
self.logunser = False
self.stats.inc_value('scheduler/unserializable',
spider=self.spider)
return
else:
return True
def _mqpush(self, request):
# 入内存队列
self.mqs.push(request, -request.priority)
Scheduler 时候传入 jobdir,则使用磁盘队列,否则使用内存队列,默认使用内存队列。指纹过滤
request_seen:def request_seen(self, request):
# 生成请求指纹
fp = self.request_fingerprint(request)
# 请求指纹如果在指纹集合中 则认为重复
if fp in self.fingerprints:
return True
# 不重复则记录此指纹
self.fingerprints.add(fp)
# 实例化如果有path则把指纹写入文件
if self.file:
self.file.write(fp + os.linesep)
def request_fingerprint(self, request):
# 调用utils.request的request_fingerprint
return request_fingerprint(request)
utils.request 的 request_fingerprint 逻辑如下:def request_fingerprint(request, include_headers=None):
"""生成请求指纹"""
# 指纹生成是否包含headers
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
# 使用sha1算法生成指纹
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
Request 对象生成一个请求指纹,在这里使用 sha1 算法,并记录到指纹集合,每次请求入队前先到这里验证一下指纹集合,如果已存在,则认为请求重复,则不会重复入队列。enqueue_request 的第一行判断,仅需将 Request 实例的 dont_filter 设置为 True 就可以重复抓取此请求,非常灵活。下载请求
_next_request_from_scheduler 方法,此时调用调度器的 next_request 方法,就是从调度器队列中取出一个请求,这次就要开始进行网络下载了,也就是调用 _download:def _download(self, request, spider):
# 下载请求
slot = self.slot
slot.add_request(request)
def _on_success(response):
# 成功回调 结果必须是Request或Response
assert isinstance(response, (Response, Request))
if isinstance(response, Response):
# 如果下载后结果为Response 返回Response
response.request = request
logkws = self.logformatter.crawled(request, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
self.signals.send_catch_log(signal=signals.response_received, \
response=response, request=request, spider=spider)
return response
def _on_complete(_):
# 此次下载完成后 继续进行下一次调度
slot.nextcall.schedule()
return _
# 调用Downloader进行下载
dwld = self.downloader.fetch(request, spider)
# 注册成功回调
dwld.addCallbacks(_on_success)
# 结束回调
dwld.addBoth(_on_complete)
return dwld
Downloader 的 fetch:def fetch(self, request, spider):
def _deactivate(response):
# 下载结束后删除此记录
self.active.remove(request)
return response
# 下载前记录处理中的请求
self.active.add(request)
# 调用下载器中间件download 并注册下载成功的回调方法是self._enqueue_request
dfd = self.middleware.download(self._enqueue_request, request, spider)
# 注册结束回调
return dfd.addBoth(_deactivate)
download,并注册下载成功的回调方法是 _enqueue_request,来看下载方法:def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process_request(request):
# 如果下载器中间件有定义process_request 则依次执行
for method in self.methods['process_request']:
response = yield method(request=request, spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_request must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, response.__class__.__name__)
# 如果下载器中间件有返回值 直接返回此结果
if response:
defer.returnValue(response)
# 如果下载器中间件没有返回值,则执行注册进来的方法 也就是Downloader的_enqueue_request
defer.returnValue((yield download_func(request=request,spider=spider)))
@defer.inlineCallbacks
def process_response(response):
assert response is not None, 'Received None in process_response'
if isinstance(response, Request):
defer.returnValue(response)
# 如果下载器中间件有定义process_response 则依次执行
for method in self.methods['process_response']:
response = yield method(request=request, response=response,
spider=spider)
assert isinstance(response, (Response, Request)), \
'Middleware %s.process_response must return Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if isinstance(response, Request):
defer.returnValue(response)
defer.returnValue(response)
@defer.inlineCallbacks
def process_exception(_failure):
exception = _failure.value
# 如果下载器中间件有定义process_exception 则依次执行
for method in self.methods['process_exception']:
response = yield method(request=request, exception=exception,
spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_exception must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, type(response))
if response:
defer.returnValue(response)
defer.returnValue(_failure)
# 注册执行、错误、回调方法
deferred = mustbe_deferred(process_request, request)
deferred.addErrback(process_exception)
deferred.addCallback(process_response)
return deferred
process_request,可对 Request 进行加工、处理、校验等操作,然后发起真正的网络下载,也就是第一个参数 download_func,在这里是 Downloader 的 _enqueue_request 方法:Downloader的 _enqueue_request:def _enqueue_request(self, request, spider):
# 加入下载请求队列
key, slot = self._get_slot(request, spider)
request.meta['download_slot'] = key
def _deactivate(response):
slot.active.remove(request)
return response
slot.active.add(request)
deferred = defer.Deferred().addBoth(_deactivate)
# 下载队列
slot.queue.append((request, deferred))
# 处理下载队列
self._process_queue(spider, slot)
return deferred
def _process_queue(self, spider, slot):
if slot.latercall and slot.latercall.active():
return
# 如果延迟下载参数有配置 则延迟处理队列
now = time()
delay = slot.download_delay()
if delay:
penalty = delay - now + slot.lastseen
if penalty > 0:
slot.latercall = reactor.callLater(penalty, self._process_queue, spider, slot)
return
# 处理下载队列
while slot.queue and slot.free_transfer_slots() > 0:
slot.lastseen = now
# 从下载队列中取出下载请求
request, deferred = slot.queue.popleft()
# 开始下载
dfd = self._download(slot, request, spider)
dfd.chainDeferred(deferred)
# 延迟
if delay:
self._process_queue(spider, slot)
break
def _download(self, slot, request, spider):
# 注册方法 调用handlers的download_request
dfd = mustbe_deferred(self.handlers.download_request, request, spider)
# 注册下载完成回调方法
def _downloaded(response):
self.signals.send_catch_log(signal=signals.response_downloaded,
response=response,
request=request,
spider=spider)
return response
dfd.addCallback(_downloaded)
slot.transferring.add(request)
def finish_transferring(_):
slot.transferring.remove(request)
# 下载完成后调用_process_queue
self._process_queue(spider, slot)
return _
return dfd.addBoth(finish_transferring)
self.handlers.download_request:def download_request(self, request, spider):
# 获取请求的scheme
scheme = urlparse_cached(request).scheme
# 根据scheeme获取下载处理器
handler = self._get_handler(scheme)
if not handler:
raise NotSupported("Unsupported URL scheme '%s': %s" %
(scheme, self._notconfigured[scheme]))
# 开始下载 并返回结果
return handler.download_request(request, spider)
def _get_handler(self, scheme):
# 根据scheme获取对应的下载处理器
# 配置文件中定义好了http、https、ftp等资源的下载处理器
if scheme in self._handlers:
return self._handlers[scheme]
if scheme in self._notconfigured:
return None
if scheme not in self._schemes:
self._notconfigured[scheme] = 'no handler available for that scheme'
return None
path = self._schemes[scheme]
try:
# 实例化下载处理器
dhcls = load_object(path)
dh = dhcls(self._crawler.settings)
except NotConfigured as ex:
self._notconfigured[scheme] = str(ex)
return None
except Exception as ex:
logger.error('Loading "%(clspath)s" for scheme "%(scheme)s"',
{"clspath": path, "scheme": scheme},
exc_info=True, extra={'crawler': self._crawler})
self._notconfigured[scheme] = str(ex)
return None
else:
self._handlers[scheme] = dh
return self._handlers[scheme]
request 的 scheme 来获取对应的下载处理器,默认配置文件中定义的下载处理器如下:DOWNLOAD_HANDLERS_BASE = {
'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler',
'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler',
'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler',
}
download_request 方法,完成网络下载,这里不再详细讲解每个处理器的实现,简单来说,你可以把它想象成封装好的网络下载库,输入URL,它会给你输出下载结果,这样方便理解。process_exception 方法,每个中间件只需定义自己的异常处理逻辑即可。process_response 方法,每个中间件可以进一步处理下载后的结果,最终返回。process_request 方法是每个中间件顺序执行的,而 process_response 和 process_exception 方法是每个中间件倒序执行的,具体可看一下 DownaloderMiddlewareManager 的 _add_middleware 方法,就可以明白是如何注册这个方法链的。ExecuteEngine 的 _next_request_from_scheduler 中,会看到调用了 _handle_downloader_output,也就是处理下载结果的逻辑:def _handle_downloader_output(self, response, request, spider):
# 下载结果必须是Request、Response、Failure其一
assert isinstance(response, (Request, Response, Failure)), response
# 如果是Request 则再次调用crawl 执行Scheduler的入队逻辑
if isinstance(response, Request):
self.crawl(response, spider)
return
# 如果是Response或Failure 则调用scraper的enqueue_scrape进一步处理
# 主要是和Spiders和Pipeline交互
d = self.scraper.enqueue_scrape(response, request, spider)
d.addErrback(lambda f: logger.error('Error while enqueuing downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
如果返回的是 Request实例,则直接再次放入Scheduler请求队列如果返回的是是 Response或Failure实例,则调用Scraper的enqueue_scrape方法,做进一步处理
处理下载结果
Scraper 的 enqueue_scrape,看Scraper 组件是如何处理后续逻辑的:def enqueue_scrape(self, response, request, spider):
# 加入Scrape处理队列
slot = self.slot
dfd = slot.add_response_request(response, request)
def finish_scraping(_):
slot.finish_response(response, request)
self._check_if_closing(spider, slot)
self._scrape_next(spider, slot)
return _
dfd.addBoth(finish_scraping)
dfd.addErrback(
lambda f: logger.error('Scraper bug processing %(request)s',
{'request': request},
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
self._scrape_next(spider, slot)
return dfd
def _scrape_next(self, spider, slot):
while slot.queue:
# 从Scraper队列中获取一个待处理的任务
response, request, deferred = slot.next_response_request_deferred()
self._scrape(response, request, spider).chainDeferred(deferred)
def _scrape(self, response, request, spider):
assert isinstance(response, (Response, Failure))
# 调用_scrape2继续处理
dfd = self._scrape2(response, request, spider)
# 注册异常回调
dfd.addErrback(self.handle_spider_error, request, response, spider)
# 出口回调
dfd.addCallback(self.handle_spider_output, request, response, spider)
return dfd
def _scrape2(self, request_result, request, spider):
# 如果结果不是Failure实例 则调用爬虫中间件管理器的scrape_response
if not isinstance(request_result, Failure):
return self.spidermw.scrape_response(
self.call_spider, request_result, request, spider)
else:
# 直接调用call_spider
dfd = self.call_spider(request_result, request, spider)
return dfd.addErrback(
self._log_download_errors, request_result, request, spider)
Scraper 的处理队列中,然后从队列中获取到任务,如果不是异常结果,则调用爬虫中间件管理器的 scrape_response 方法:def scrape_response(self, scrape_func, response, request, spider):
fname = lambda f:'%s.%s' % (
six.get_method_self(f).__class__.__name__,
six.get_method_function(f).__name__)
def process_spider_input(response):
# 执行一系列爬虫中间件的process_spider_input
for method in self.methods['process_spider_input']:
try:
result = method(response=response, spider=spider)
assert result is None, \
'Middleware %s must returns None or ' \
'raise an exception, got %s ' \
% (fname(method), type(result))
except:
return scrape_func(Failure(), request, spider)
# 执行完中间件的一系列process_spider_input方法后 执行call_spider
return scrape_func(response, request, spider)
def process_spider_exception(_failure):
# 执行一系列爬虫中间件的process_spider_exception
exception = _failure.value
for method in self.methods['process_spider_exception']:
result = method(response=response, exception=exception, spider=spider)
assert result is None or _isiterable(result), \
'Middleware %s must returns None, or an iterable object, got %s ' % \
(fname(method), type(result))
if result is not None:
return result
return _failure
def process_spider_output(result):
# 执行一系列爬虫中间件的process_spider_output
for method in self.methods['process_spider_output']:
result = method(response=response, result=result, spider=spider)
assert _isiterable(result), \
'Middleware %s must returns an iterable object, got %s ' % \
(fname(method), type(result))
return result
# 执行process_spider_input
dfd = mustbe_deferred(process_spider_input, response)
# 注册异常回调
dfd.addErrback(process_spider_exception)
# 注册出口回调
dfd.addCallback(process_spider_output)
return dfd
回调爬虫
call_spider 方法,这里回调我们写好的爬虫类:def call_spider(self, result, request, spider):
# 回调爬虫模块
result.request = request
dfd = defer_result(result)
# 注册回调方法 取得request.callback 如果未定义则调用爬虫模块的parse方法
dfd.addCallbacks(request.callback or spider.parse, request.errback)
return dfd.addCallback(iterate_spider_output)
parse 则是第一个回调方法。之后爬虫类拿到下载结果,就可以定义下载后的 callback 方法,也是在这里进行回调执行的。处理输出
Scraper 调用了 handle_spider_output 方法处理爬虫的输出结果:def handle_spider_output(self, result, request, response, spider):
# 处理爬虫输出结果
if not result:
return defer_succeed(None)
it = iter_errback(result, self.handle_spider_error, request, response, spider)
# 注册_process_spidermw_output
dfd = parallel(it, self.concurrent_items,
self._process_spidermw_output, request, response, spider)
return dfd
def _process_spidermw_output(self, output, request, response, spider):
# 处理Spider模块返回的每一个Request/Item
if isinstance(output, Request):
# 如果结果是Request 再次入Scheduler的请求队列
self.crawler.engine.crawl(request=output, spider=spider)
elif isinstance(output, (BaseItem, dict)):
# 如果结果是BaseItem/dict
self.slot.itemproc_size += 1
# 调用Pipeline的process_item
dfd = self.itemproc.process_item(output, spider)
dfd.addBoth(self._itemproc_finished, output, response, spider)
return dfd
elif output is None:
pass
else:
typename = type(output).__name__
logger.error('Spider must return Request, BaseItem, dict or None, '
'got %(typename)r in %(request)s',
{'request': request, 'typename': typename},
extra={'spider': spider})
Request 或 BaseItem 实例。Scheduler 进入请求队列,如果是 BaseItem 实例,则调用 Pipeline 管理器,依次执行 process_item。我们想输出结果时,只需要定义 Pepeline 类,然后重写这个方法就可以了。ItemPipeManager 处理逻辑:class ItemPipelineManager(MiddlewareManager):
component_name = 'item pipeline'
@classmethod
def _get_mwlist_from_settings(cls, settings):
return build_component_list(settings.getwithbase('ITEM_PIPELINES'))
def _add_middleware(self, pipe):
super(ItemPipelineManager, self)._add_middleware(pipe)
if hasattr(pipe, 'process_item'):
self.methods['process_item'].append(pipe.process_item)
def process_item(self, item, spider):
# 依次调用Pipeline的process_item
return self._process_chain('process_item', item, spider)
ItemPipeManager 也是一个中间件,和之前下载器中间件管理器和爬虫中间件管理器类似,如果子类有定义 process_item,则依次执行它。_itemproc_finished:def _itemproc_finished(self, output, item, response, spider):
self.slot.itemproc_size -= 1
if isinstance(output, Failure):
ex = output.value
# 如果在Pipeline处理中抛DropItem异常 忽略处理结果
if isinstance(ex, DropItem):
logkws = self.logformatter.dropped(item, ex, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
return self.signals.send_catch_log_deferred(
signal=signals.item_dropped, item=item, response=response,
spider=spider, exception=output.value)
else:
logger.error('Error processing %(item)s', {'item': item},
exc_info=failure_to_exc_info(output),
extra={'spider': spider})
else:
logkws = self.logformatter.scraped(output, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
return self.signals.send_catch_log_deferred(
signal=signals.item_scraped, item=output, response=response,
spider=spider)
Pipeline 中丢弃某个结果,直接抛出 DropItem 异常即可,Scrapy 会进行对应的处理。Request 则会再次进入请求队列,等待引擎下一次调度,也就是再次调用 ExecutionEngine 的 _next_request,直至请求队列没有新的任务,整个程序退出。CrawlerSpider
CrawlerSpider 类,我们平时用的也比较多,它其实就是继承了 Spider 类,然后重写了 parse 方法(这也是继承此类不要重写此方法的原因),并结合 Rule 规则类,来完成 Request 的自动提取逻辑。总结
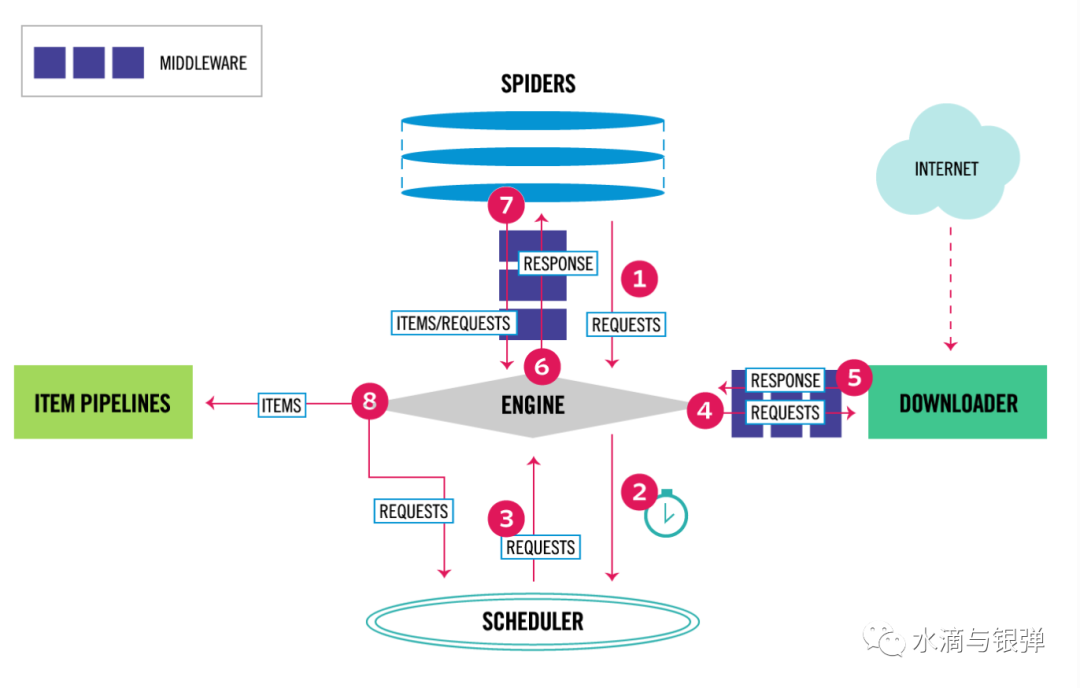
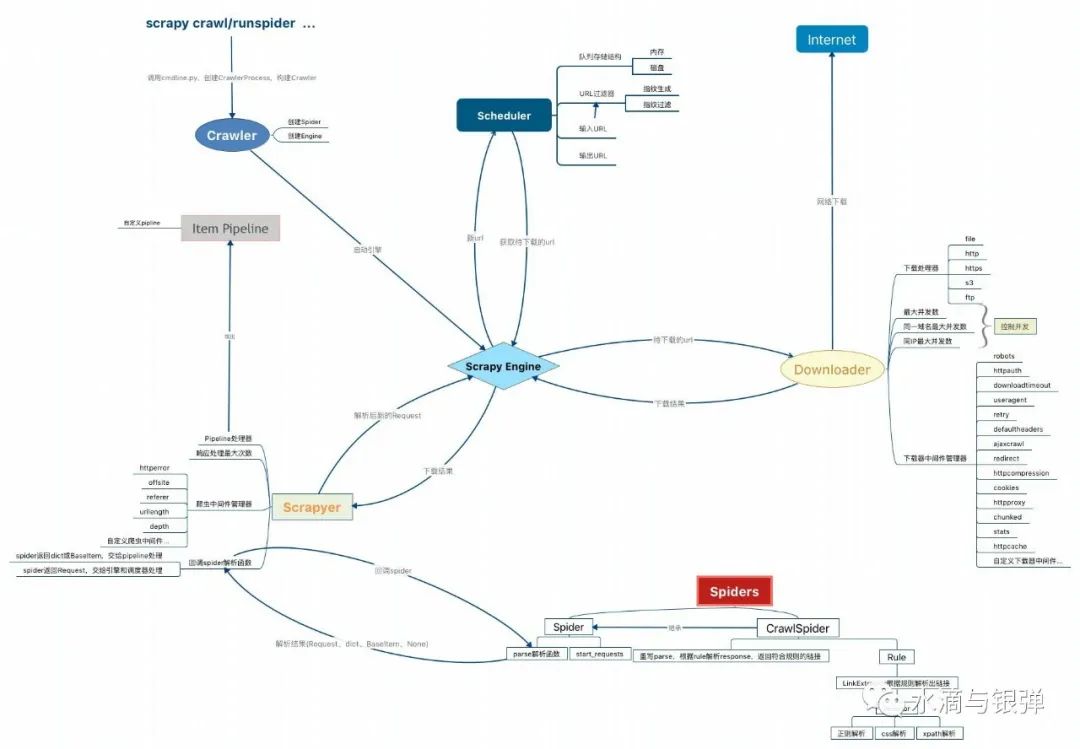
更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论