
实战 | 手把手教你使用scrapy框架批量抓取招聘信息
回复“书籍”即可获赠Python从入门到进阶共10本电子书
爬前分析
爬取前我们来简单分析一下腾讯的技术岗招聘网页,进入网站并打开开发者工具,如下图所示:
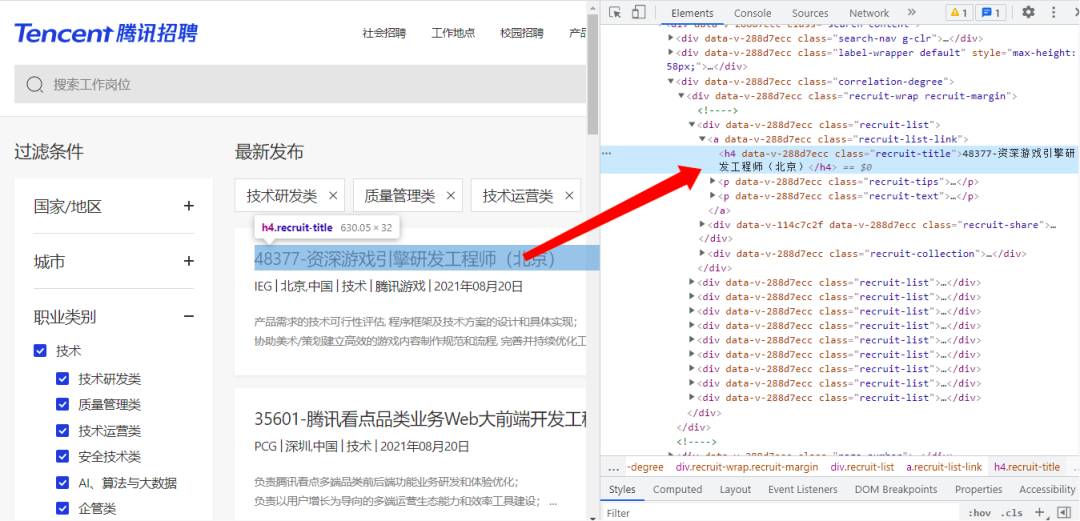
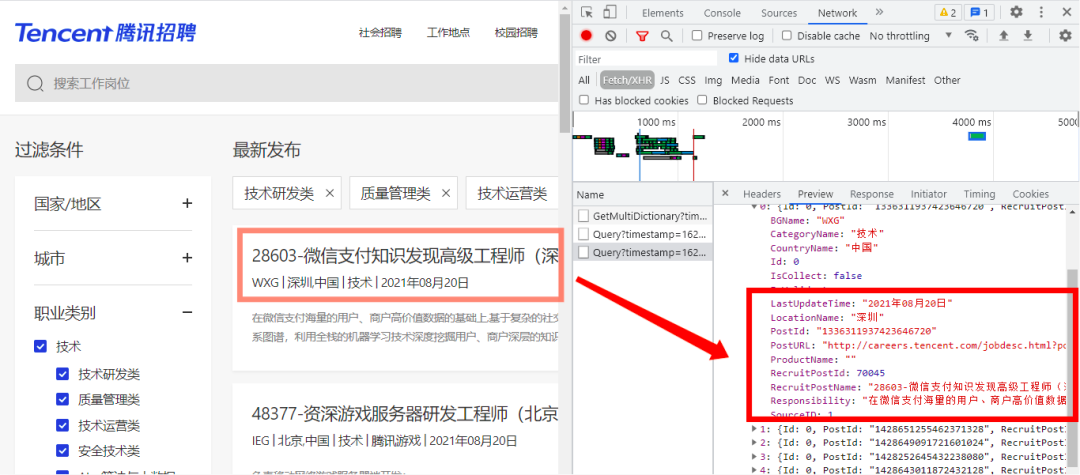
https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1629464904109&countryId=&cityId=&bgIds=&productId=&categoryId=40001001,40001002,40001003,40001004,40001005,40001006&parentCategoryId=&attrId=&keyword=&pageIndex=2&pageSize=10&language=zh-cn&area=cn
#第一页
https://careers.tencent.com/tencentcareer/api/post/Query?categoryId=40001001,40001002,40001003,40001004,40001005,40001006&pageIndex=1&pageSize=10&language=zh-cn&area=cn
#第二页
https://careers.tencent.com/tencentcareer/api/post/Query?categoryId=40001001,40001002,40001003,40001004,40001005,40001006&pageIndex=2&pageSize=10&language=zh-cn&area=cn
#第三页
https://careers.tencent.com/tencentcareer/api/post/Query?categoryId=40001001,40001002,40001003,40001004,40001005,40001006&pageIndex=3&pageSize=10&language=zh-cn&area=cn
通过简单删减可以得出该URL可以为上面的URL,而且pageIndex的翻页的重要参数。
好了,数据的存储位置和URL已经知道了,接下来我们开始爬取数据。
实战演练
1、创建scrapy项目
首先要创建一个scrapy项目,创建方式很简单,只要在执行以下命令即可:
scrapy startproject Tencent
2、创建spider爬虫
创建spider爬虫的方式也很简单,只要执行如下命令即可:
scrapy genspider 爬取名 网站域名
scrapy genspider tencent careers.tencent.com
import scrapy
class Tencent1Spider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['careers.tencent.com']
start_urls = ['http://careers.tencent.com/']
def parse(self, response):
pass
其中
name是我们的爬虫名;
allowed_domains是域名,也就是爬虫爬取的范围;
start_urls是爬虫最开始爬取的URL链接;
parse()是用来解析响应、提取数据。
注意:parse()不能修改名字。
3、定义字段
在编写代码提取数据前,我们先来在items.py定义爬取的字段,字段类型为scrapy.Field,代码如下所示:
import scrapy
class TencentItem(scrapy.Item):
# define the fields for your item here like:
RecruitPostName = scrapy.Field() #职位名
LocationName = scrapy.Field() #地址
Responsibility = scrapy.Field() #工作要求
4、提取数据
定义好字段后,接下来开始在tencent.py中编写代码来提取数据,具体代码如下所示:
import scrapy
from Tencent.items import TencentItem
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['careers.tencent.com']
start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?categoryId=40001001,40001002,40001003,40001004,40001005,40001006&pageIndex=1&pageSize=10&language=zh-cn&area=cn']
def parse(self, response):
json=response.json()
datas = json.get('Data').get('Posts')
for data in datas:
item=TencentItem()
item['RecruitPostName']=data.get('RecruitPostName'),
item['LocationName']=data.get('LocationName'),
item['Responsibility']=data.get('Responsibility').replace('\n','')
yield item
首先我们导入items.py文件中的TencentItem,再修改start_urls的URL链接,定义一个json变量来接收网页响应的json()数据,通过for循环把每条职位信息循环遍历并提取我们想要的数据并放在item字典里面,其中item=TencentItem()相当于创建一个空字典item={},
翻页操作
首页我们已经成功获取到了,接下来要进行翻页操作,具体代码如下所示:
for i in range(2,4):
next_url=f'https://careers.tencent.com/tencentcareer/api/post/Query?categoryId=40001001,40001002,40001003,40001004,40001005,40001006&pageIndex={i}&pageSize=10&language=zh-cn&area=cn'
yield scrapy.Request(
next_url,
callback=self.parse
)
首先我们创建一个for循环来进行翻页,调用yield生成器来返回数据给引擎,并调用scrapy.Request()方法,该方法能构建一个requests,同时指定提取数据的callback函数。
5、settings.py配置
在启动爬取前,我们先要在settings.py文件中编写一些代码,具体代码如下所示:
LOG_LEVEL="WARNING"
ITEM_PIPELINES = {
'Tencent.pipelines.TencentPipeline': 300,
}
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
其中:
LOG_LEVEL的作用的屏蔽log日志的输出;
ITEM_PIPELINES的作用是开启引擎;
6、保存数据
当我们要把数据保存成文件的时候,不需要任何额外的代码,只要执行如下代码即可
scrapy crawl 爬虫名 -o xxx.json #保存为JSON文件
scrapy crawl 爬虫名 -o xxx.csv #保存为csv文件
scrapy crawl 爬虫名 -o xxx.xml #保存为xml文件 当要把数据保存在数据库里面或者txt文件时,则需要在pipelines.py文件中编写代码。
好了,全部代码已经编写好了,现在执行以下命令来启动爬虫
scrapy crawl tencent -o tencent.csv
结果展示

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~