
如何利用Scrapy爬虫框架抓取网页全部文章信息(下篇)
回复“书籍”即可获赠Python从入门到进阶共10本电子书
/前言/
在上篇文章中,如何利用Scrapy爬虫框架抓取网页全部文章信息(中篇)、如何利用Scrapy爬虫框架抓取网页全部文章信息(上篇),我们已经解析了列表页中所有文章的URL并交给Scrapy进行下载,这篇文章我们将提取下一页的URL并交给Scrapy进行下载,具体教程如下。
/具体实现/
1、首先在网页中先找到“下一页”的相关链接,如下图所示。与网页进行交互,找到“下一页”的URL。
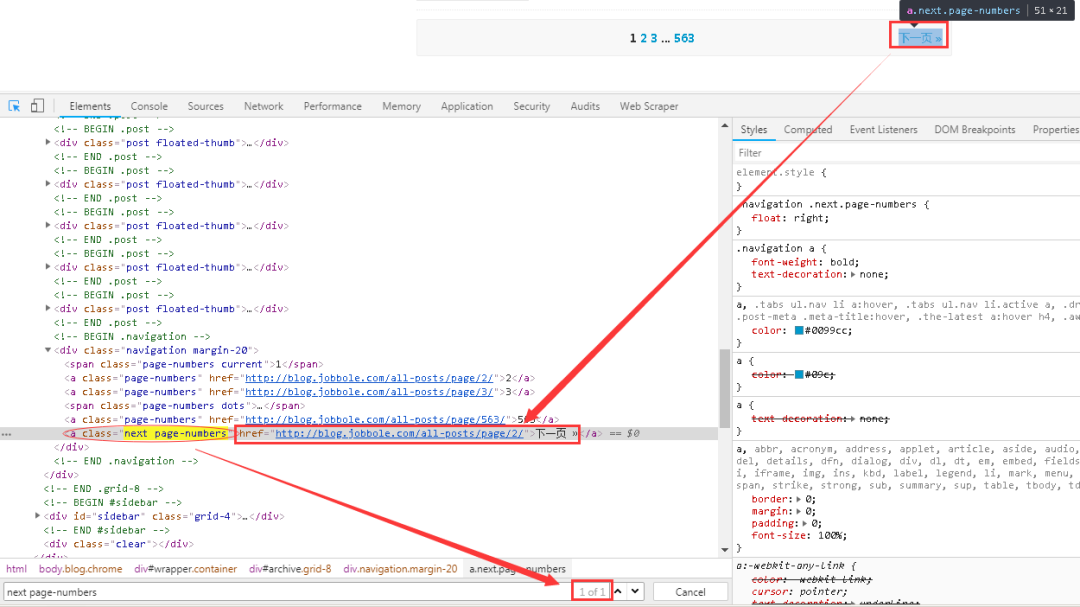
可以看到下一页的链接存在与a标签下的nextpage-numbers属性下面的href标签中,而且该属性是唯一的,可以很轻易的定位到该链接。
2、可以在scrapyshell中进行调试,尔后再将满足条件的表达式写入到代码中去,如下图所示。
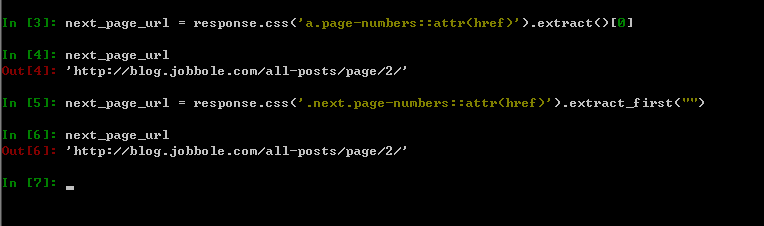
上图中两种方式都可以提取到目标信息。比较推荐的是第二种方式,其中.next.page-numbers代表的是同一个class下有两个属性,可以更快更准确的定位到标签,需要注意的是两个属性直接直接用点号进行连接,无任何的空格,初学者容易犯错。另外,extract_first("")这个函数在之前的文章中提及过,其默认值为空,如果没有匹配到目标信息的话,则返回None。
3、取到了下一页的链接之后,需要对其做个判断,以防万一,具体的代码如下图所示。
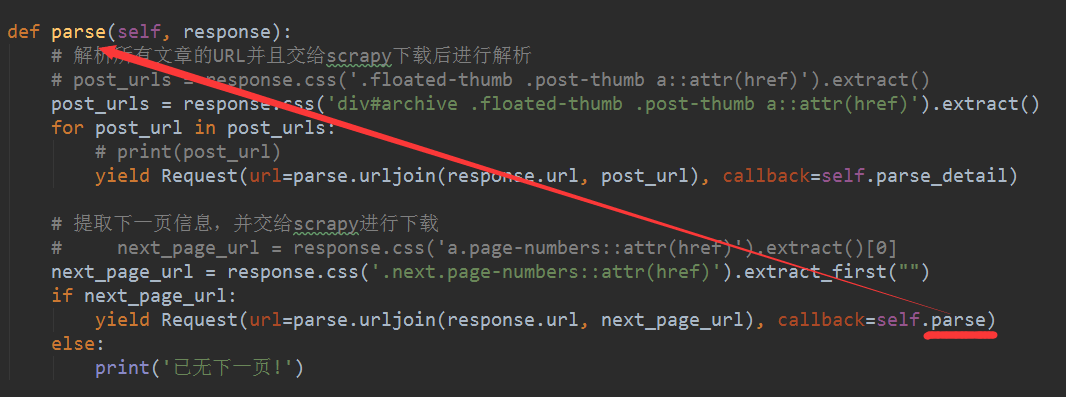
至此,我们已经提取了下一页的URL,并交给Scrapy进行下载。需要注意的是除了URL拼接部分之后,callback回调函数在这里是parse()函数,表示回调下一页的文章列表页,而不是文章详情页面,这点需要特别注意。
4、接下来,我们就可以对整个爬虫进行调试了,在爬虫主体文件中设置好断点,如下图所示,之后在main.py文件中点击运行Debug,
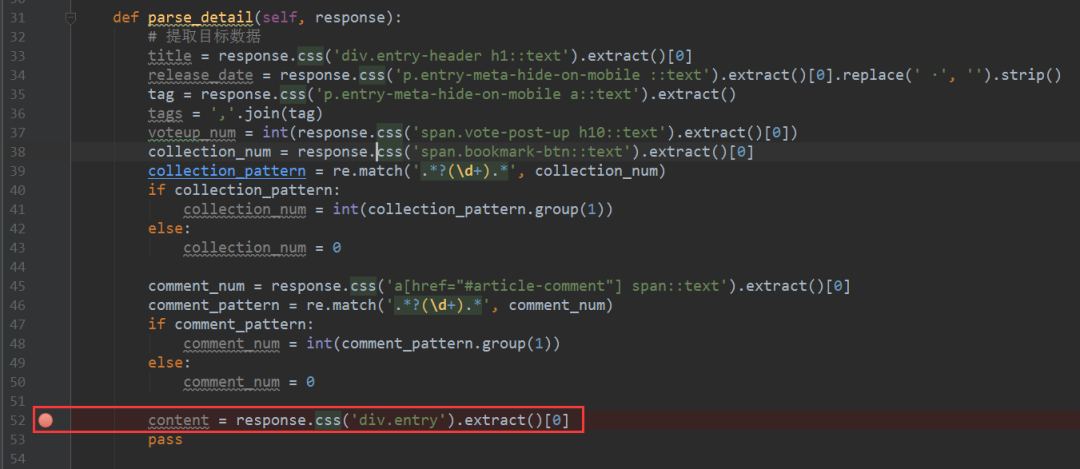
5、稍等片刻,等待调试的结果出来,如下图所示,结果鲜明。
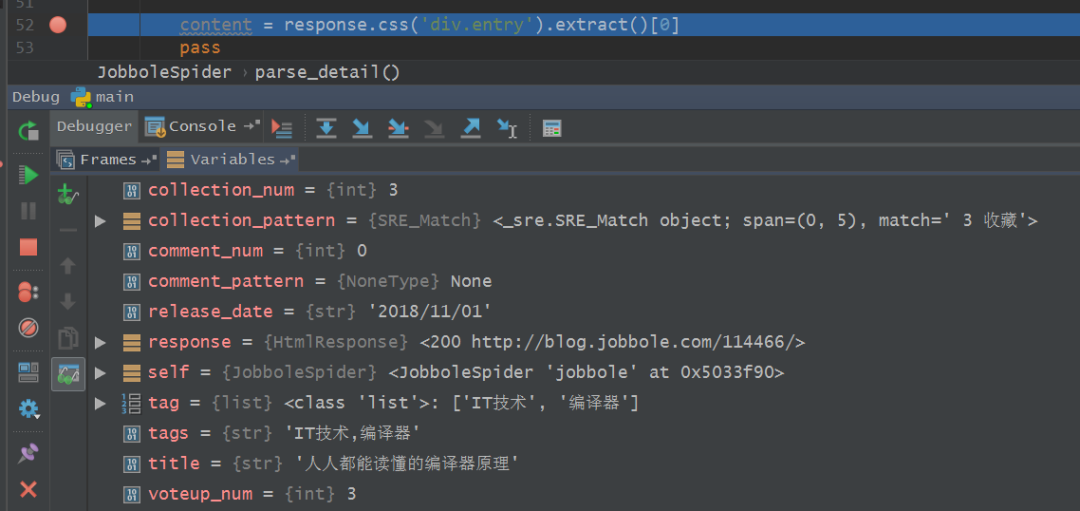
6、到这里,我们基本上已经完成所有文章的提取,简单的回顾一下整个爬取过程。首先我们在parse()函数中获取到文章的URL,尔后将其交给Scrapy去进行下载,下载完成之后,Scrapy再去调用parse_detail()函数去提取网页中的目标信息,这个页面提取完成之后,再进行下一个页面的信息提取,并将下一页的URL交给Scrapy去进行下载,再回调parse()函数以提取出下一页中文章列表的URL,如此往复的进行迭代,一直到最后一页为止,整个爬虫才会停止。
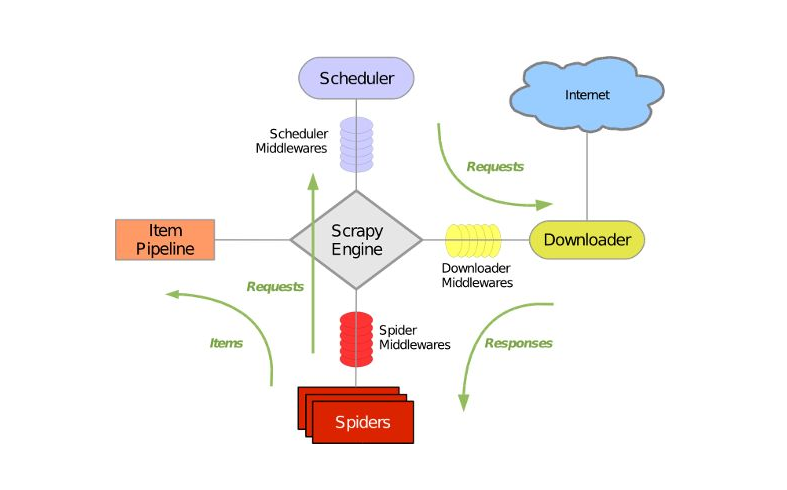
7、利用Scrapy爬虫框架,我们便可以获取到整个网站的全部文章内容,中间的具体下载实现完全不用经过我们手动去进行,有木有感受到Scrapy爬虫的强大咧?
目前我们只是遍历了整个网站,知道了目标信息的提取方法,暂时还没有将目标数据保存到本地或者数据库当中去,后边的文章我们继续再约~~~
/小结/
本文基于Scrapy爬虫框架,利用CSS选择器和Xpath选择器解析列表页中所有文章的URL,遍历整个网站进行数据采集,至此,我们已经可以实现全网文章的数据采集了。
想学习更多关于Python的知识,可以参考学习网址:http://pdcfighting.com/,点击阅读原文,可以直达噢~
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~