
【NLP】Transformer自注意机制代码实现
编译 | VK
来源 | Towards Data Science

Transformers — Yo_just need Attention(https://machinelearningmarvel.in/transformers-you-just-need-attention/) Intuitive Maths and Code behind Self-Attention Mechanism of Transformers(https://machinelearningmarvel.in/intuitive-maths-and-code-behind-self-attention-mechanism-of-transformers-for-dummies/) Concepts about Positional Encoding Yo_Might Not Know About(https://machinelearningmarvel.in/concepts-about-positional-encoding-you-might-not-know-about/)
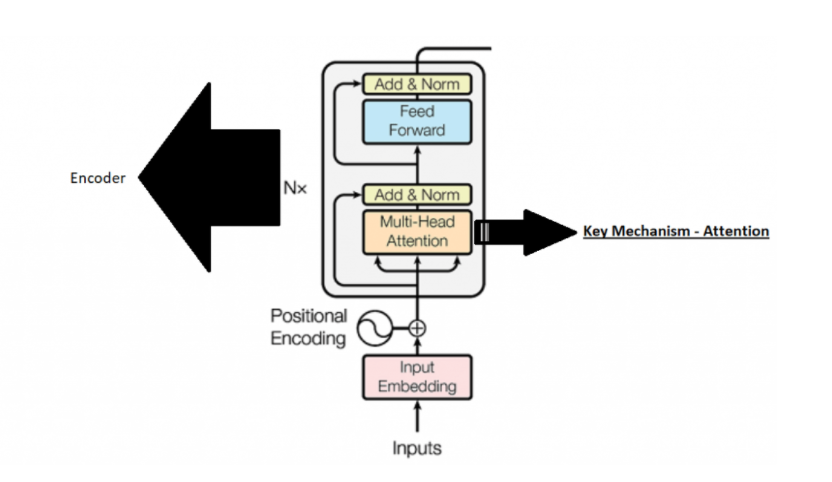
注意机制概念 自注意机制的步骤(直觉数学理论和代码)
输入预处理 查询、键和值矩阵 注意分数的概念
多头自注意机制
注意机制概念
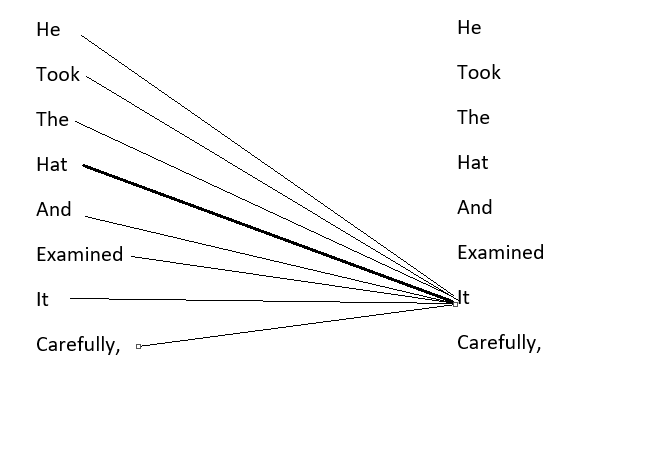
自注意机制的步骤
1.输入正确的格式
print(f”Shape is :- {np.random.randn(3,5).shape}”)
X=np.random.randn(3,5)
X

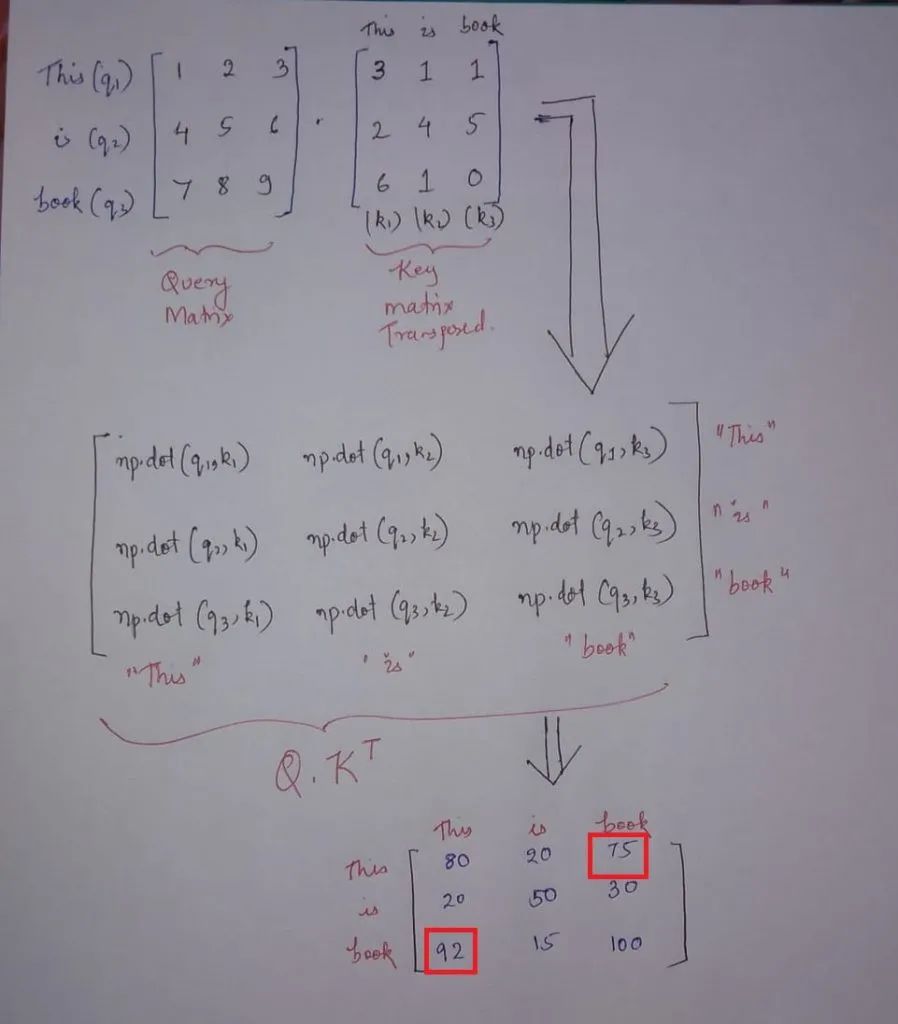
2.获取查询、键值矩阵

weight_of_query=np.random.randn(5,3)
weight_of_query

weight_of_key=np.random.randn(5,3)
weight_of_key

weight_of_values=np.random.randn(5,3)
weight_of_values

Key=np.matmul(X,weight_of_key)
Key

Query=np.matmul(X,weight_of_query)
Query

Values=np.matmul(X,weight_of_values)
Values

3.注意得分
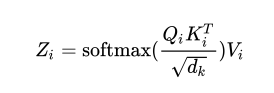
dimension=5
Scores=np.matmul(Query,Key.T)/np.sqrt(dimension)
Scores

from scipy.special import softmax
Softmax_attention_scores=np.array([softmax(x) for x in Scores])
Softmax_attention_scores
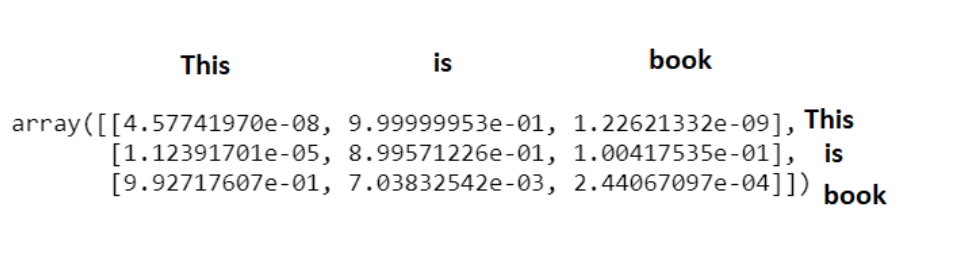
Softmax_attention_scores[0][0]*Values[0]+\
Softmax_attention_scores[0][1]*Values[1]+\
Softmax_attention_scores[0][2]*Values[2]

多头自注意机制
Transformers — Yo_just need Attention(https://machinelearningmarvel.in/transformers-you-just-need-attention/) Intuitive Maths and Code behind Self-Attention Mechanism of Transformers(https://machinelearningmarvel.in/intuitive-maths-and-code-behind-self-attention-mechanism-of-transformers-for-dummies/) Concepts about Positional Encoding Yo_Might Not Know About(https://machinelearningmarvel.in/concepts-about-positional-encoding-you-might-not-know-about/)
往期精彩回顾 本站qq群851320808,加入微信群请扫码:
评论