一天几千万订单,也是MySql做存储吗?

前几天一位前同事联系我,说他们现在的交易系统遇到了性能问题,想聊下解决方案。
他们的存储用的是MySql,现在偶发查询超时的情况,怀疑是MySql不能支持他们的场景了,问是否需要迁移存储引擎,问我们每天几千万订单的交易场景也是用MySql吗?
首先我们日单几千万用的也是MySql,他们现在的量级遇到慢查情况就急于切换存储引擎肯定是不靠谱的。
用MySql遇到慢查情况是很常见的,当然MySql性能优化也不能光靠加索引和Sql优化。
常见的分库分表也可以解决一定问题。
前置加缓存解决数据一致性的方案也很常见。
数据异构到不同存储引擎也是一种方式方式。
优化产品逻辑往往比技术方案还奏效。
和他聊下来之后,我可以明确感觉到他没有很好的定义他们现在的问题,比如现在合理的解决方案是否已经做到极致了?你想提高性能到多少是合适的?场景是否可以允许数据不一致?高可用重要还是高性能重要?
如果没有好的问题定义,就很难得到好的解决方案,因为解决方案太多了,但每一个方案背后都是有取舍的,取什么舍什么完全是由业务逻辑决定的,所以我让他回去再想想。
正好在脉脉上看到有人讨论这个问题就一起聊聊。
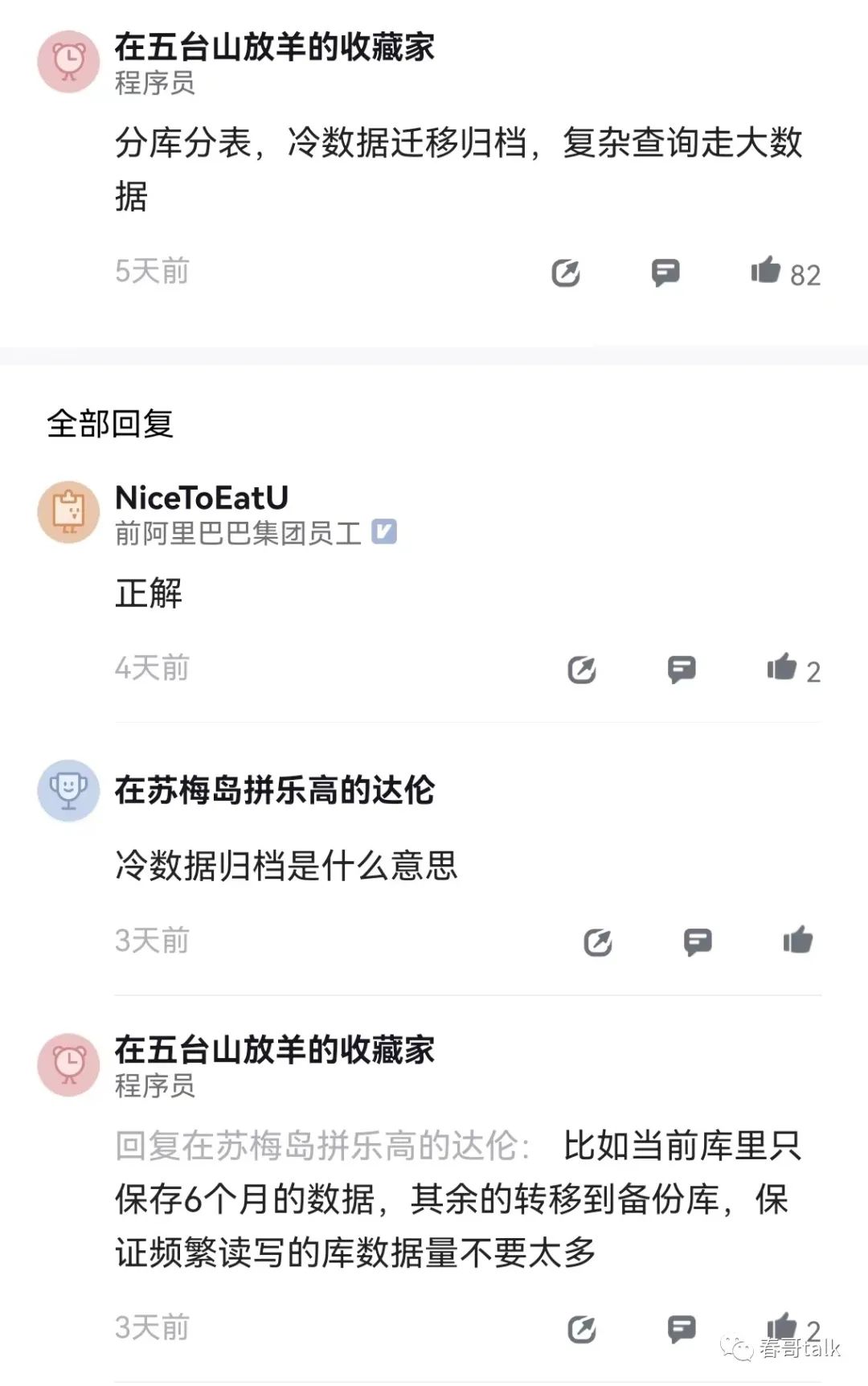
大数据量使用MySql,第一个要解决的问题是区分冷热数据
聊这个问题的解决方案,首先会面对的第一个问题是:你真的需要所有数据都做高性能的查询吗?结论大概率不是,那么就可以针对不同场景提供不同的存储介质了。
比如MySql在千万级数据量下其实可以很好的保障性能,同时业务上大概率可以商量到只对一小部分热数据做高性能查询就可以了。
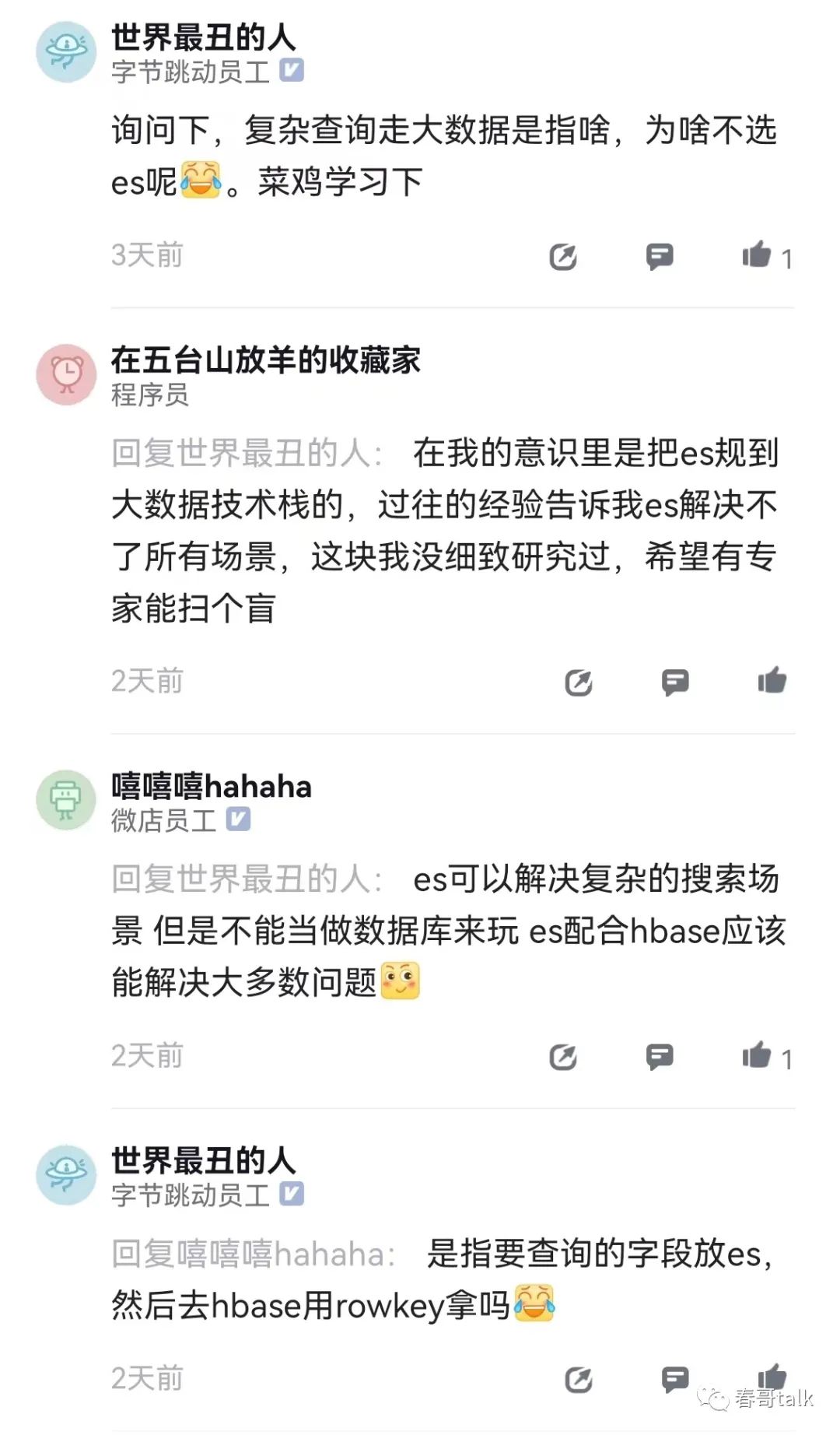
ES和HBase是常用的冷数据存储解决方案。
两者结合主要利用的是ES的全文检索,和HBase结合可以做其二级索引,提升查询性能。
你看冷热数据分离这个大前提如果不做的话,在纯技术角度聊问题其实没啥价值,要回归业务。
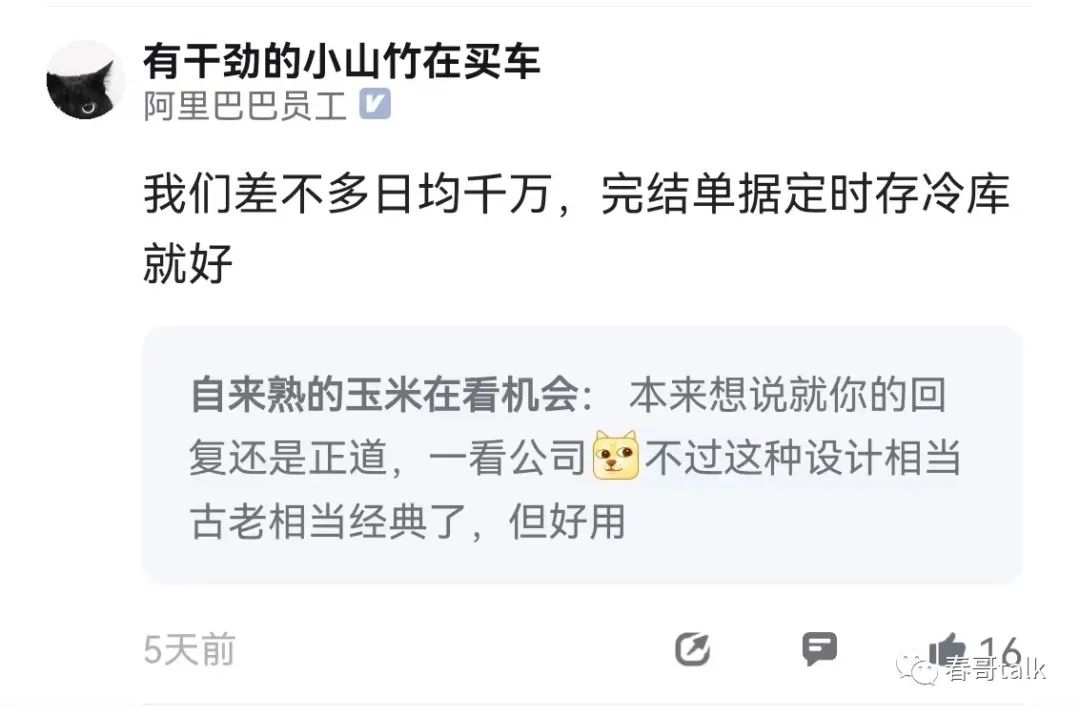
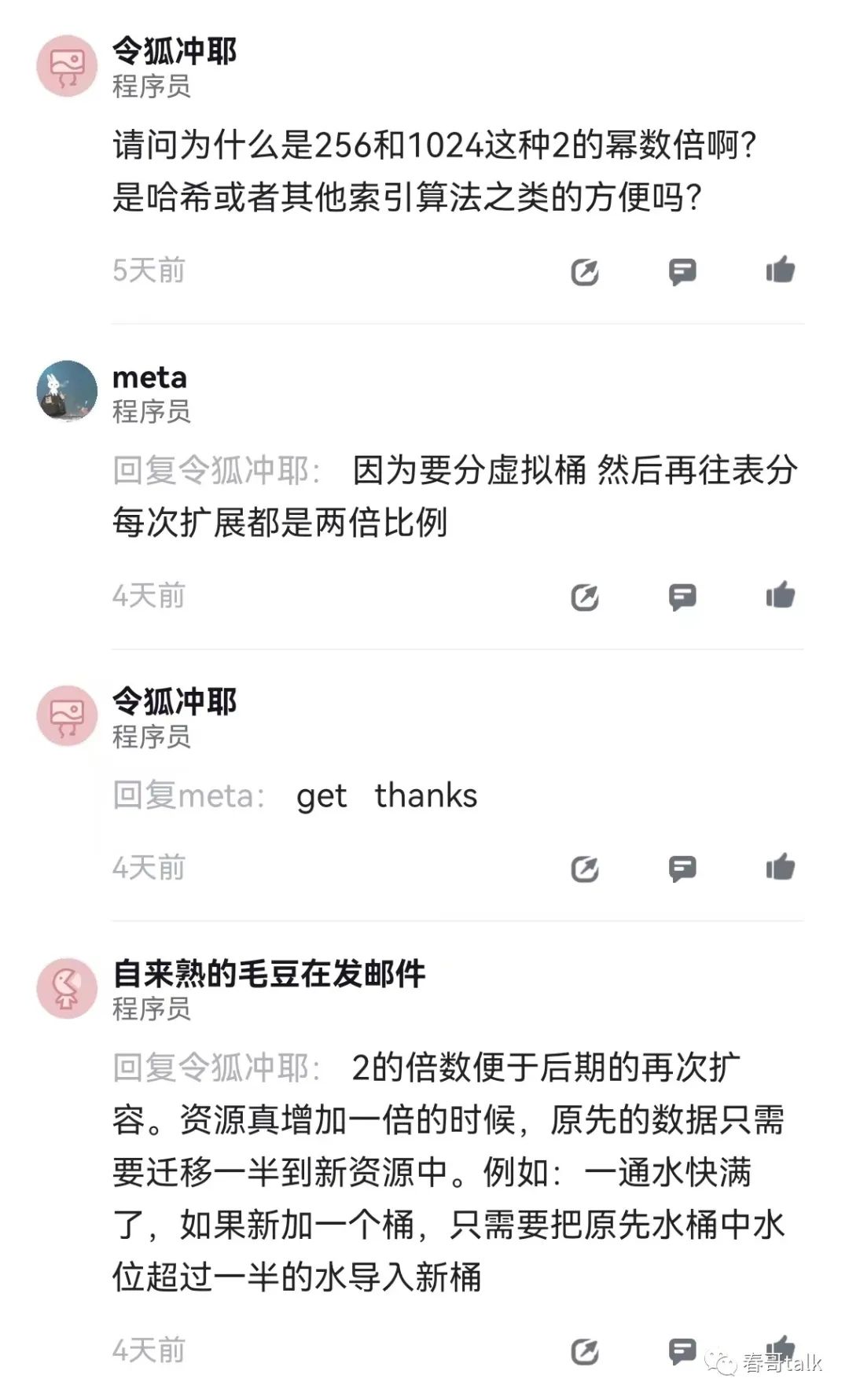
分库分表是常用的解决方案。
分库分表的关键在于结合数据发展确定分配数量,以及选择合适的分片Key。
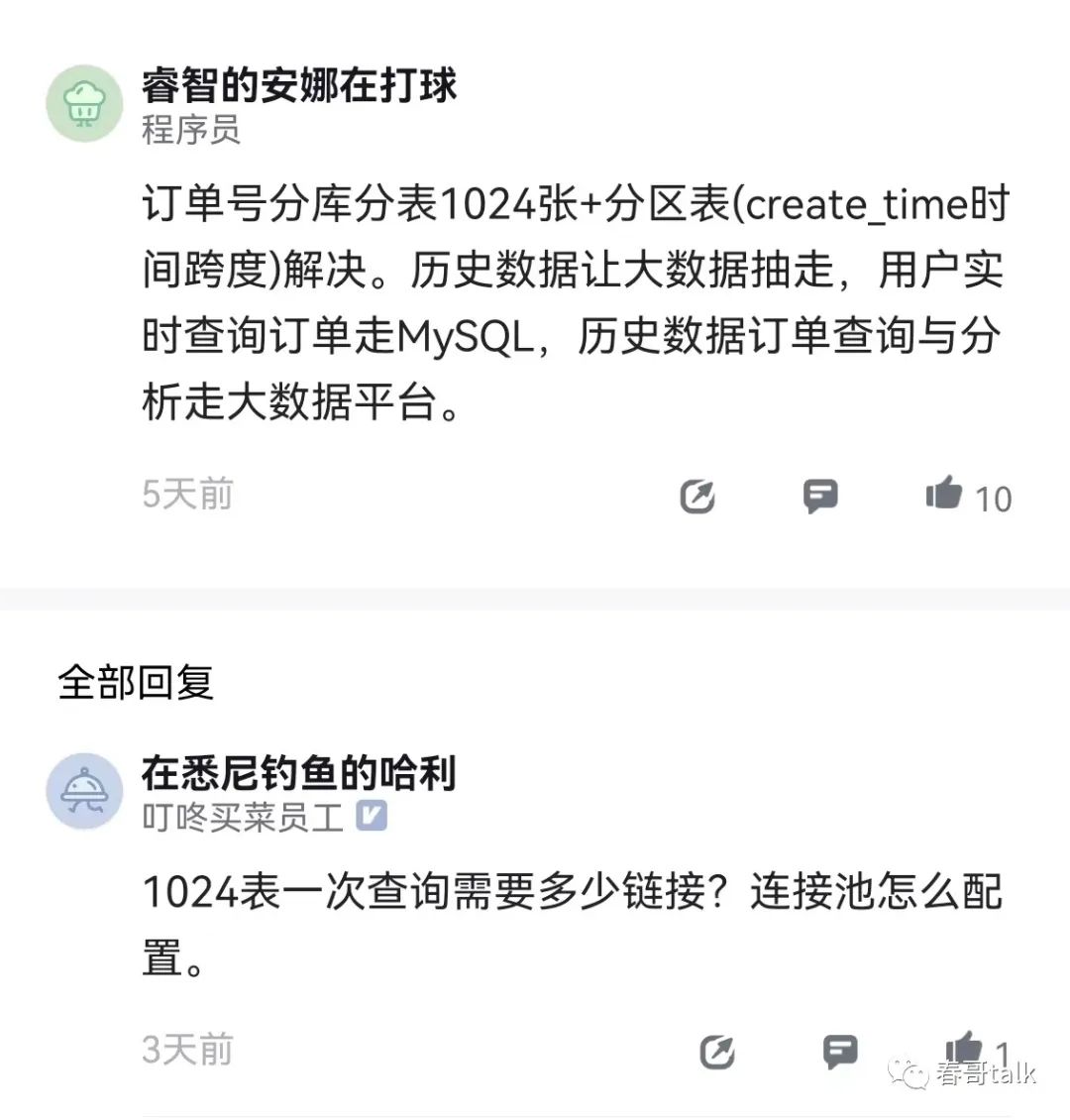
还有一些场景,单纯的数据量大,用于统计分析,查询频次不高,大概率可以用大数据组件承接。
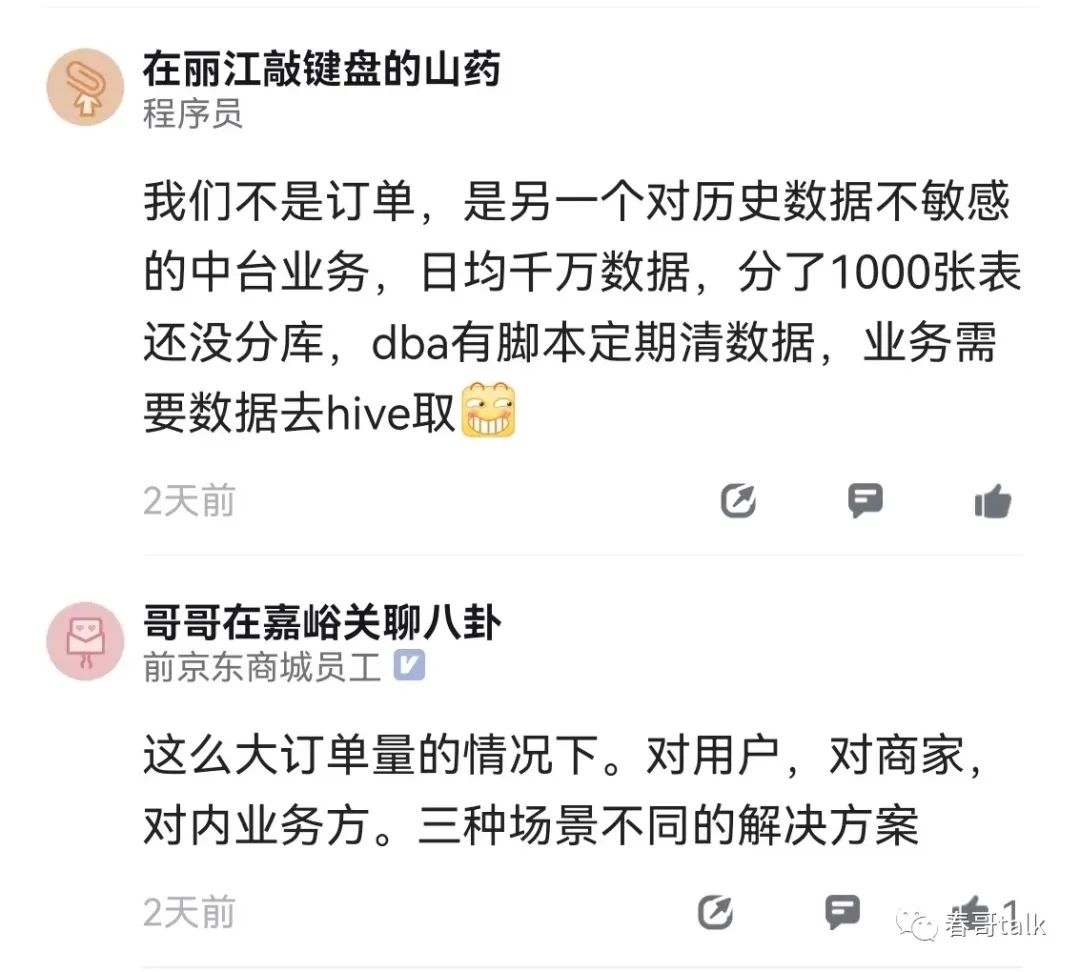
如果对数据获取性能有机制要求,缓存依然是可靠选择。
常用的方式是内存缓存+分布式缓存,数据一致性确实是个问题,但微服务时代最终一致性是常态,看这个不一致窗口业务是否可以容忍。
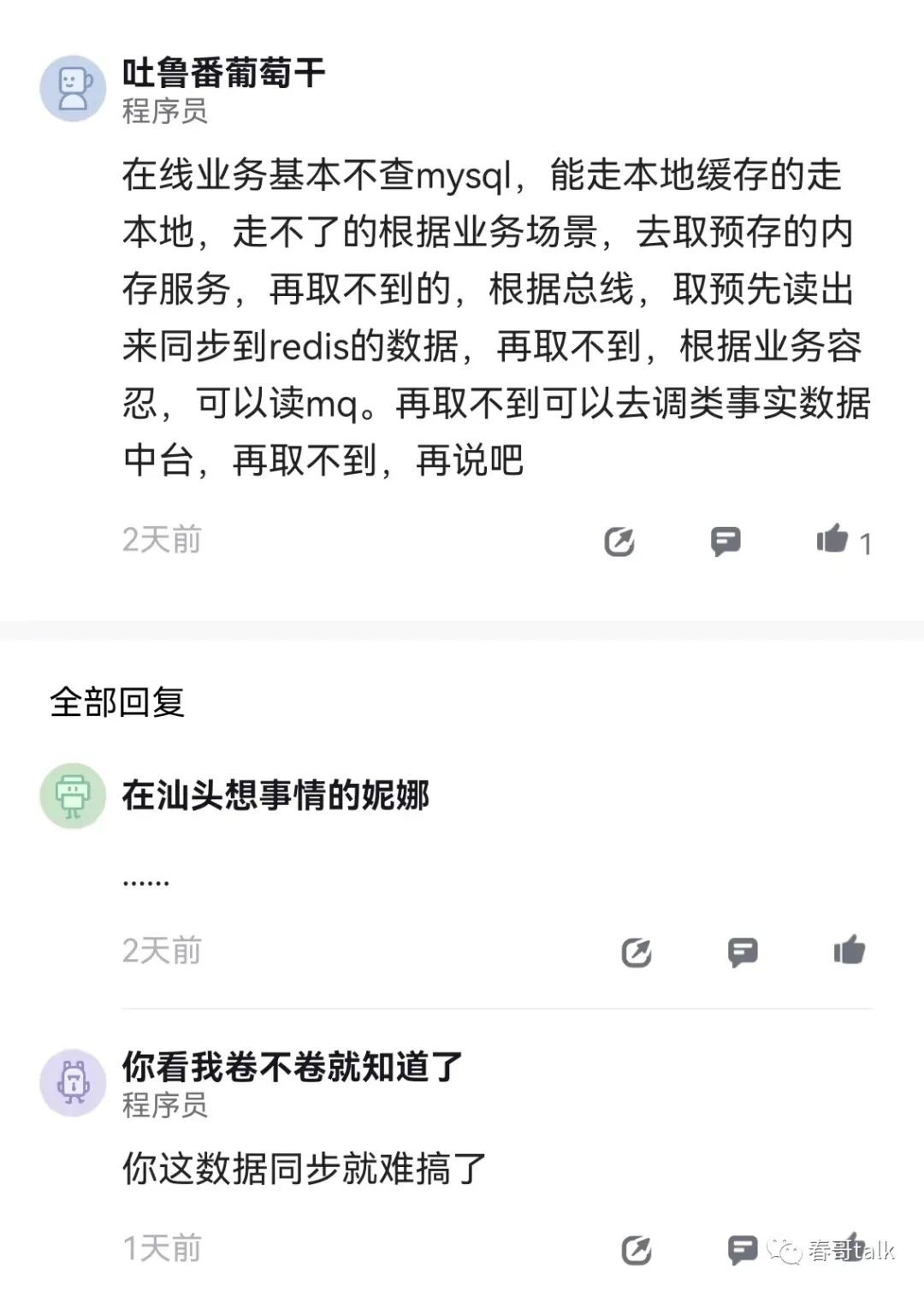
还是要依据场景选择合适的存储引擎。
比如是OLAP还是OLTP的,还是单纯的存储统计。
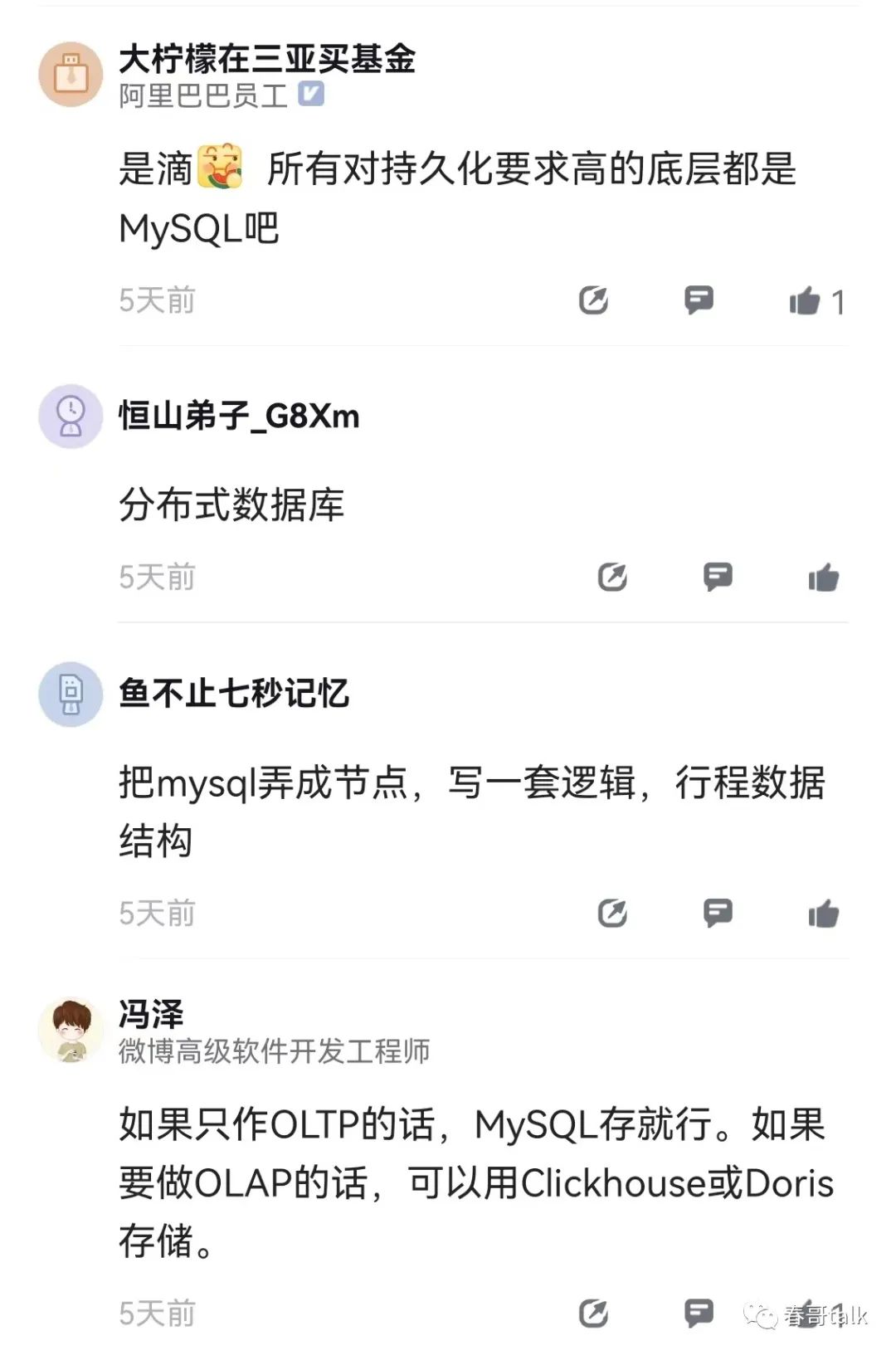
嗯,分库分表、冷热分离、内存缓存+分布式缓存、单元化、数据异构我们都用了,当然分了不同场景在用。
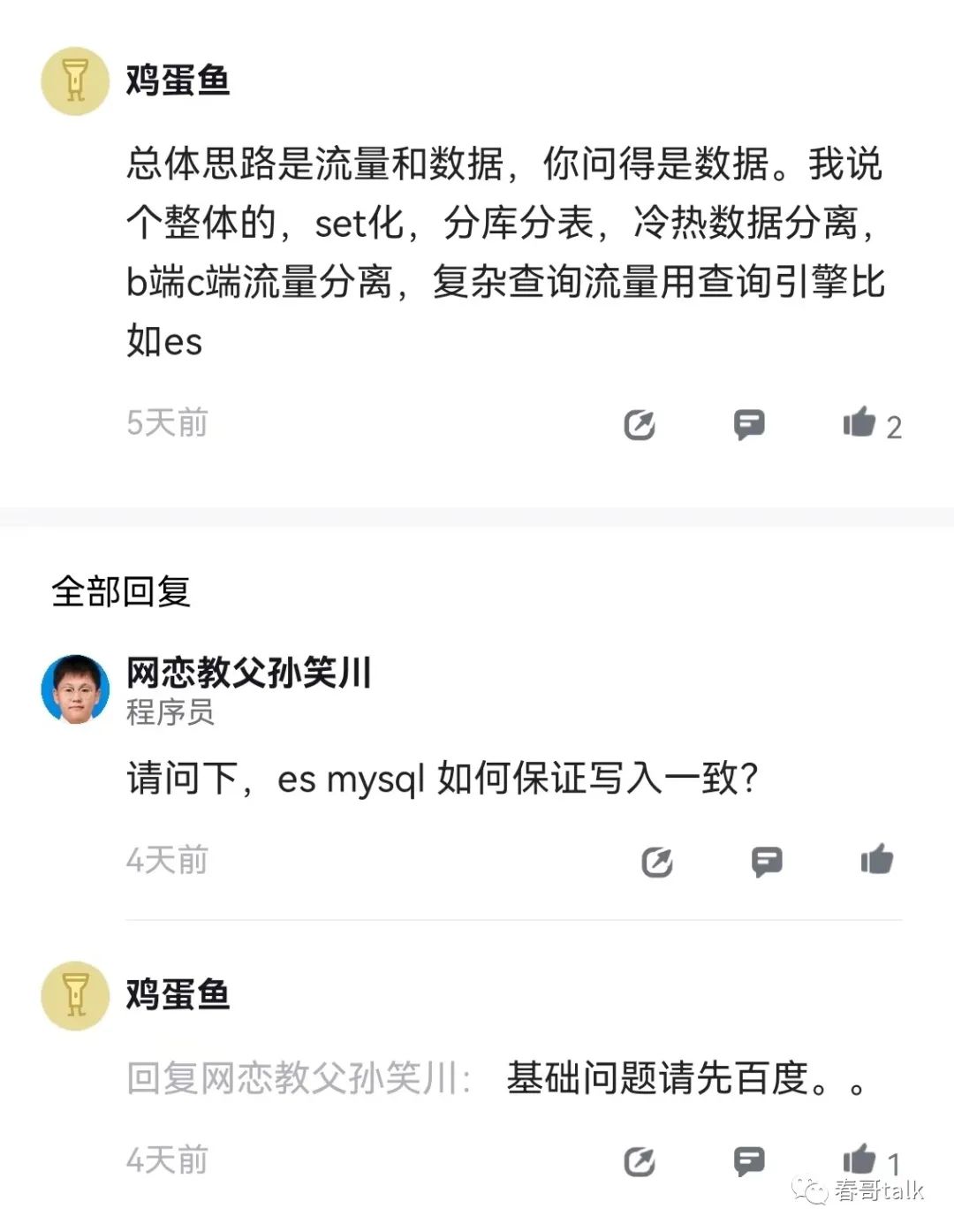
如何选择分配键是一个值得讨论的话题。
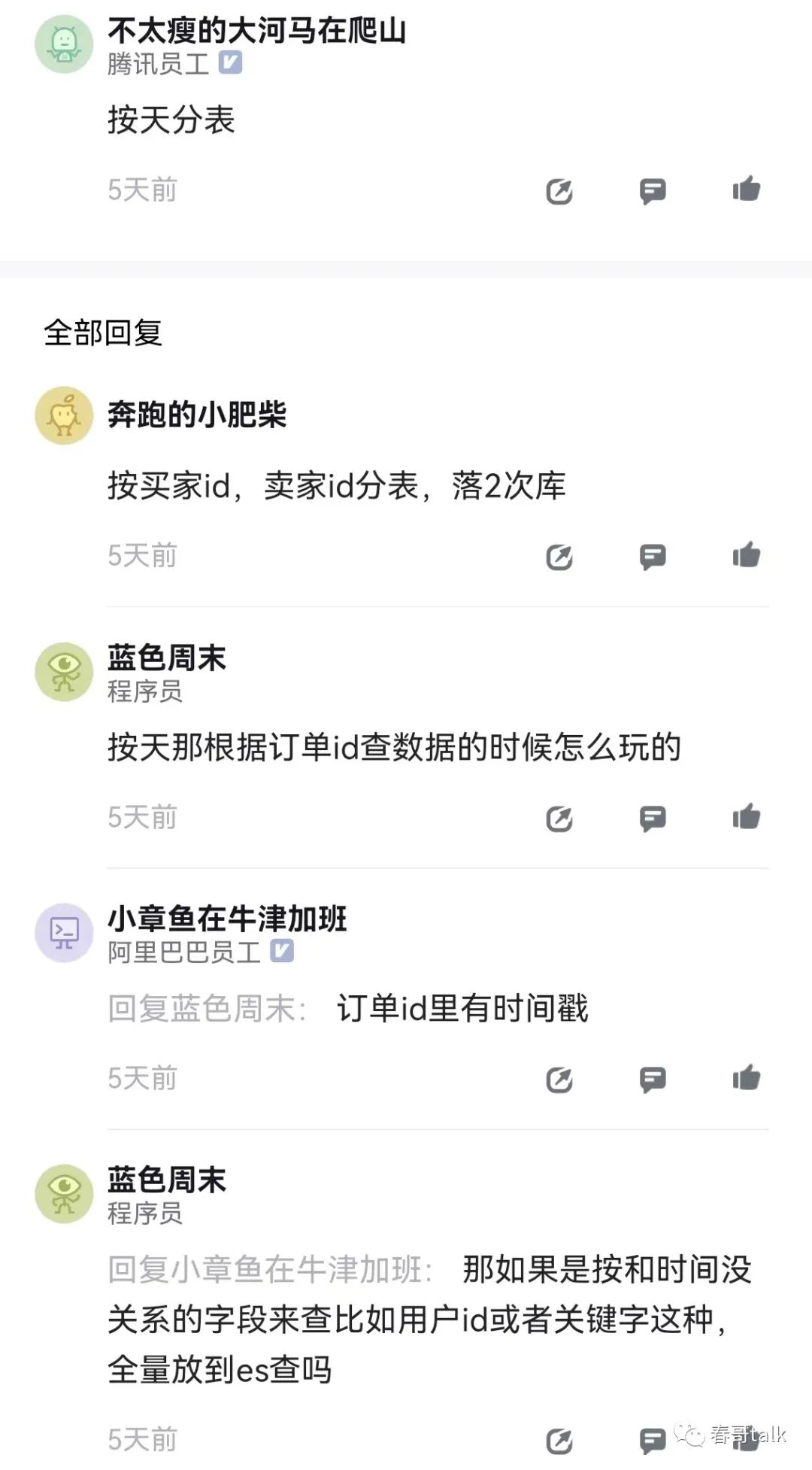
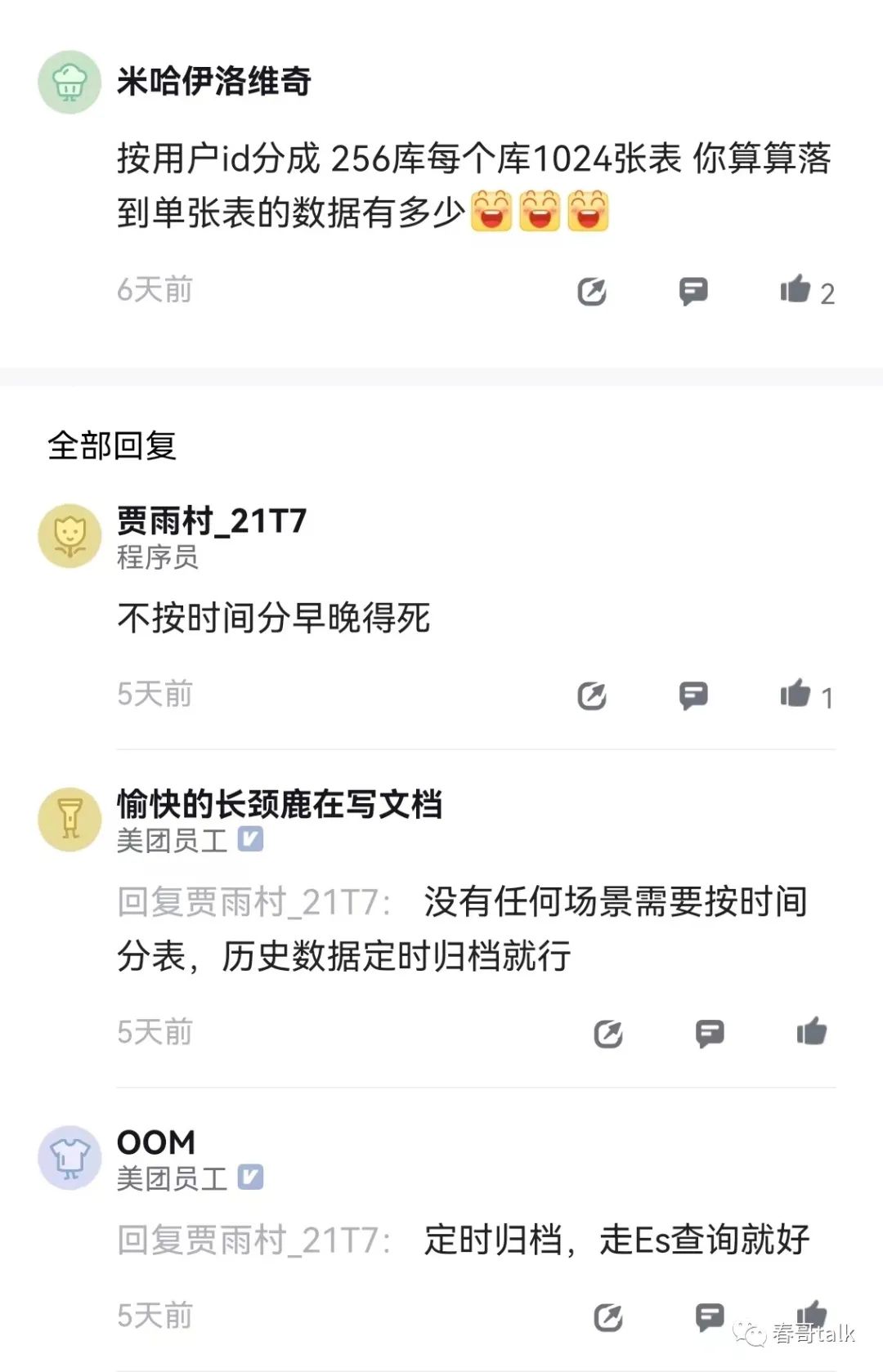
不按时间分是常态啊?反正历史数据会归档的,热数据大概率没必要按时间分片。