
对"样本不均衡"一顿操作
重采样
这个是目前使用频率最高的方式,可以对“多数”样本降采样,也可以对“少数”样本过采样,如下图所示:
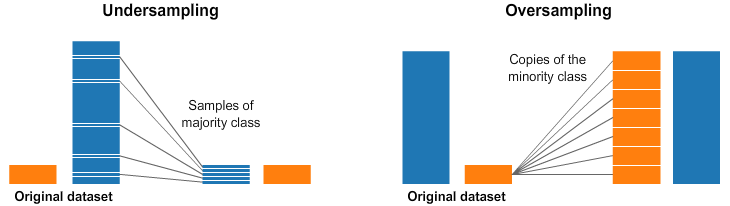
重采样的缺点也比较明显,过采样对少数样本"过度捕捞",降采样会丢失大量信息。
重采样的方案也有很多,最简单的就是随机过采样/降采样,使得各个类别的数量大致相同。还有一些复杂的采样方式,比如先对样本聚类,在需要降采样的样本上,按类别进行降采样,这样能丢失较少的信息。过采样的话,可以不用简单的copy,可以加一点点"噪声",生成更多的样本。
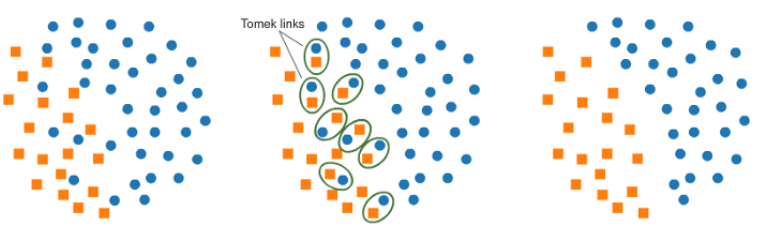
Tomek links
Tomek连接指的是在空间上"最近"的样本,但是是不同类别的样本。删除这些pair中,占大多数类别的样本。通过这种降采样方式,有利于分类模型的学习,如下图所示:
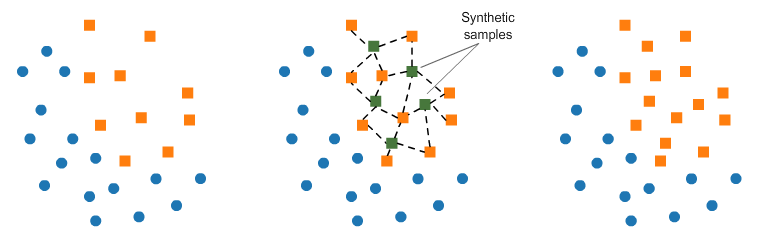
SMOTE
这个方法可以给少数样本做扩充,SMOTE在样本空间中少数样本随机挑选一个样本,计算k个邻近的样本,在这些样本之间插入一些样本做扩充,反复这个过程,知道样本均衡,如下图所示:
NearMiss
这是个降采样的方法,通过距离计算,删除掉一些无用的点。
NearMiss-1:在多数类样本中选择与最近的3个少数类样本的平均距离最小的样本。
NearMiss-2:在多数类样本中选择与最远的3个少数类样本的平均距离最小的样本。
NearMiss-3:对于每个少数类样本,选择离它最近的给定数量的多数类样本。
NearMiss-1考虑的是与最近的3个少数类样本的平均距离,是局部的;NearMiss-2考虑的是与最远的3个少数类样本的平均距离,是全局的。NearMiss-1方法得到的多数类样本分布也是“不均衡”的,它倾向于在比较集中的少数类附近找到更多的多数类样本,而在孤立的(或者说是离群的)少数类附近找到更少的多数类样本,原因是NearMiss-1方法考虑的局部性质和平均距离。NearMiss-3方法则会使得每一个少数类样本附近都有足够多的多数类样本,显然这会使得模型的精确度高、召回率低。
评估指标
为了避免对模型的误判,避免使用Accuracy,可以用confusion matrix,precision,recall,f1-score,AUC,ROC等指标。
惩罚项
对少数样本预测错误增大惩罚,是一个比较直接的方式。
使用多种算法
模型融合不止能提升效果,也能解决样本不均的问题,经验上,树模型对样本不均的解决帮助很大,特别是随机森林,Random Forest,XGB,LGB等。因为树模型作用方式类似于if/else,所以迫使模型对少数样本也非常重视。
正确的使用K-fold
当我们对样本过采样时,对过采样的样本使用k-fold,那么模型会过拟合我们过采样的样本,所以交叉验证要在过采样前做。在过采样过程中,应当增加些随机性,避免过拟合。
使用多种重采样的训练集
这种方法可以使用更多的数据获得一个泛化性较强的模型。用所有的少数样本,和多种采样的多数样本,构建多个模型得到多个模型做融合,可以取得不错的效果。
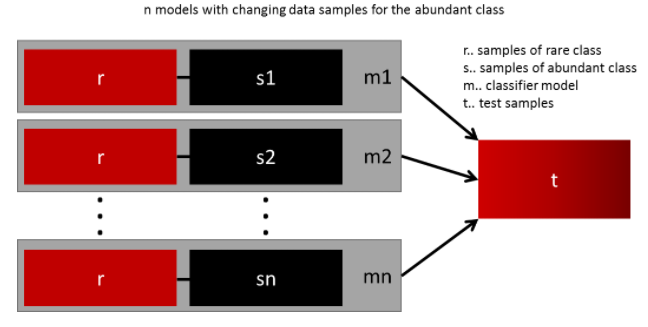
重采样使用不同rate
这个方法和上面的方法很类似,尝试使用各种不同的采样率,训练不同的模型。
没有什么解决样本不均最好的方法,以上内容也没有枚举出所有的解决方案,最好的方案就是尝试使用各种方案。
✄------------------------------------------------
双一流高校研究生团队创建 ☞
专注于计算机视觉原创并分享相关知识
闻道有先后,术业有专攻,如是而已 ╮(╯_╰)╭