
群里都在讨论这条SQL。。
大家好,我是宝器!
清脆的微信声,把我从梦中唤醒。早已习惯起床之后,回复下公众号信息,爬一下微信群里的楼。
只是今天,特别热闹。红色的小圆点,已经提示,微信群有 128+ 的未读消息了。
好奇打开了下,这次讨论的,是一道 SQL 面试题。
我对代码有洁癖,看到扭捏成一坨的 SQL, 忍不住拿到 Visual Studio Code 里,用 poorman's sql formatter 给 PS 下。
就像发朋友圈,任何不经滤镜,美颜的图,从不发。女孩子们都懂的!
以下是整理后的代码,颜值高很多:
select *
from user
where age = 10
limit 100000, 10 ;
time 4.73s
select a.*
from user a
inner join (
select id
from user
where age = 10
limit 100000,10
) b
on b.id = a.id ;
time 0.53s
面试官提问,把第一段 SQL 改为第二段后,为什么性能会有如此之大的提高,优化逻辑是什么。
这一题,让我想到特别恶毒的一个段子:
你愿意躺在宝马车里哭,还是喜欢坐在自行车上笑?
没有限定的条件,回答自然千奇百怪,甚至大相径庭。
如果有条件,为啥我不能躺在宝马里笑;又或者坐在自行车上,难道就不会哭了?
汇总了下,大家对这道题的优化逻辑:
user 表上有 age 的索引 user 表上有 age 的索引,还有 id 覆盖索引 第二段的子查询不用回表 第一段 SQL 执行了全表扫描
更有朋友质疑了第二段的性能提高:
没有 order by,结果乱序,易产 bug 第一段 SQL 重跑下,应该 0 秒就出结果 除非是查询缓存,第二段效率未必高 MySQL优化器真笨,为什么不直接跳到第 100000 条,白白浪费读取那么多数据
回答都很精彩,质疑也都有理有据。可以看得出来,能回答出一二的朋友,数据库功底都很棒。
插一句:没有基础的小白,你肯定很烦讨论这样的问题。这就是为什么,我的群里,读者都需要有基础。当然,你若真感兴趣,态度友好,有颗求知红心,那非常欢迎你。
回到题目上来,要回答好这道 SQL,特别考验数据库的底层认知。仅仅从语法角度,这一题不难,无非是子查询 + inner join 的考察。
从数据库体系结构上回答,这一题就比较复杂。还要考虑到 MySQL 的产品特性,比如 MySQL 8 , 有些关系型数据库的理论,在这里就行不通,比如查询缓存。
据我有限的认识,这道题考察了这些方面:
数据库的数据页结构 数据库的索引页结构 查询优化器的原理 数据页,索引页访问算法 数据库缓存设计 数据库并发控制 数据库引导优化器的方法 数据库执行计划
在继续阅读之前,请各位看官,自备清茶或咖啡,以免读到干渴而放弃。准备好了,咱们就开始。
数据库的数据页结构
数据页是数据库的底层存储单元。我知道,很多初学者听到底层,就头大。认为和 c/c++ 一样无聊,甚至像是看到了汇编,天然想着要逃避。
我曾经也这样。甚至幻想,像虚竹一样,头顶头,获取无崖子一甲子功力。但靠YY,解决不了任何实际问题。纯靠与数据库大V,握个手,喝个咖啡,是不会获得任何技巧的。
接受了这个事实,我就开始死磕市面上能买到的数据库相关书籍了。
于是我发现,数据库的数据页结构,并非想象的那么难。用作业本来比喻,就很好理解。
小时候写作业,大家都用的本子,应该都还印象挺深吧。
田字格语文本与数学用作业本

这种本子的每一页,都记载着我们难忘的童年。
有被罚抄留下的课文段落;也有正儿八经写下的作文;还有写的小纸条,通常那一页写上一两句就撕了,现在想想够浪费吧。
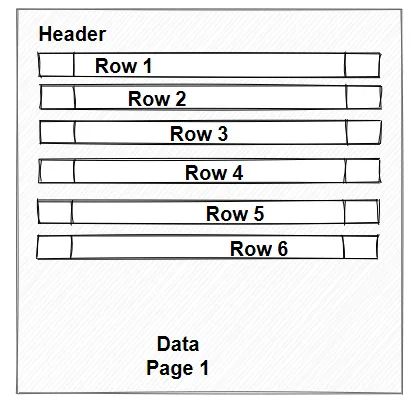
在这样的本子里写字,你写得字大,还是小;或者写一行空一行,都会 影响这一页的信息密度。明明可以用一页纸写完,写的字儿大了,写的稀疏了,行与行之间还有空一两行,就会加大信息密度的间隙。
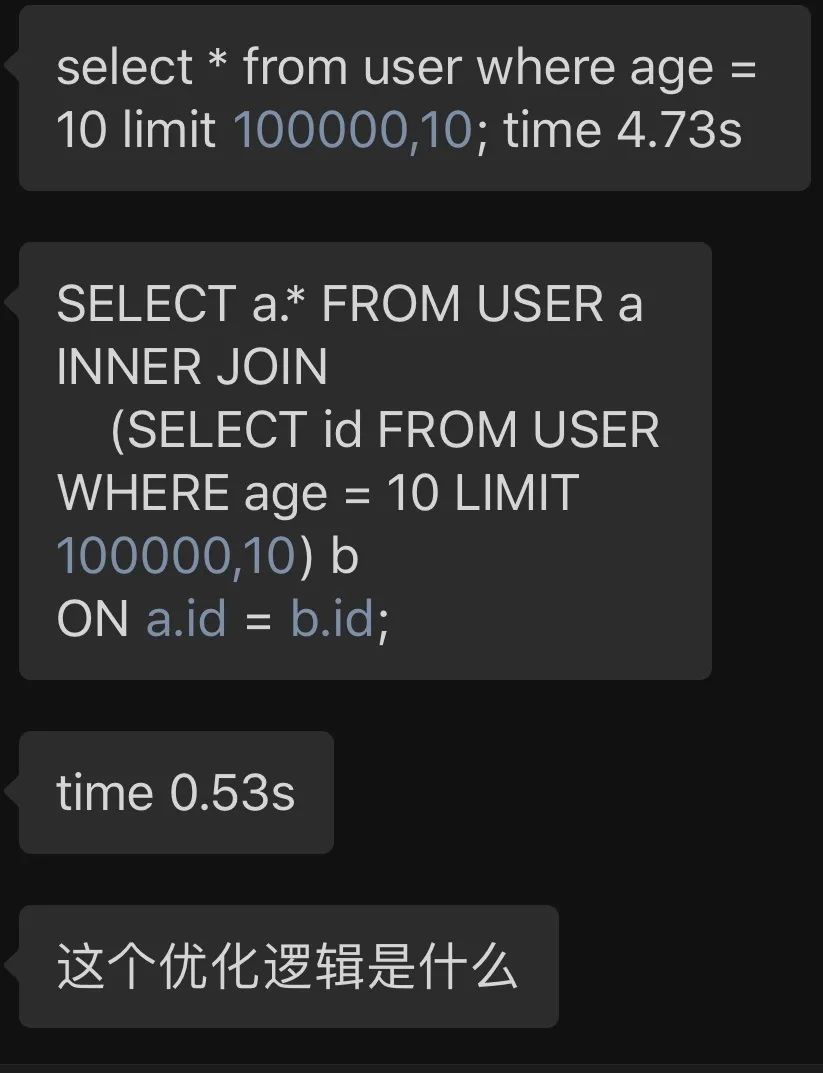
数据库的数据页也一样。它从上到下,写满了byte(字节),或者为了 insert 速度和减少行溢出,中间空几行。
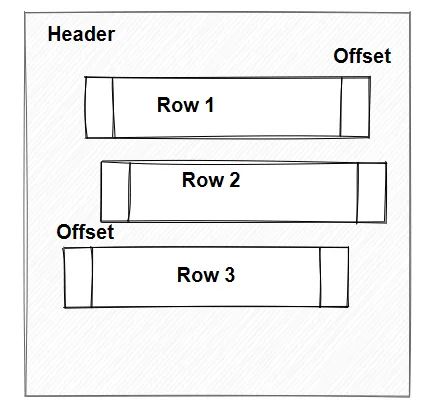
这样的数据页,组合起来,就成了存储一张表的结构。数据量越大,数据页也越多。
如果没有很好的设计字段长度,存储的时候,也没有安排的紧密些,那么原本存储1万行的数据,就有可能需要10万行的空间。
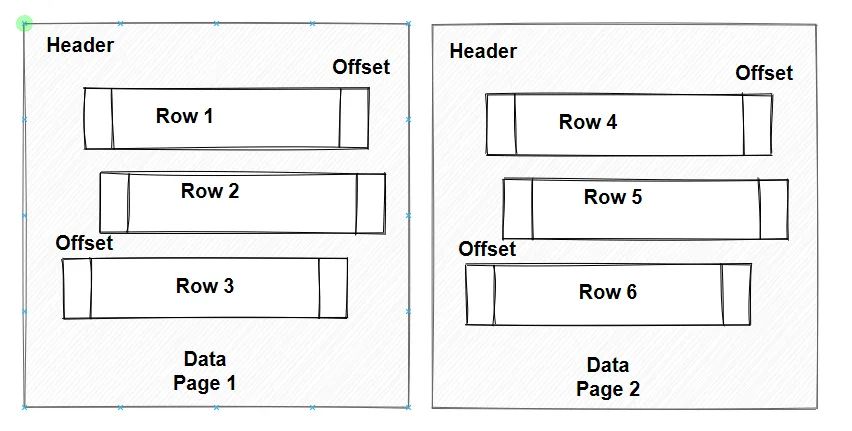
上两图就很好的解释了,空间安排的重要性。
这和在作业本上写作业一个道理。
写作业讲完了,我们来讲讲读。
如果你打算从头到尾去读你的作业本,想必会花很多时间,才能找到你想要的曾经写过的特别佩服自己的那段话,或者公式推理。
此时,有两种方法,可以帮你:
一种,一开始写作业,就把字儿写得小一些,把空行都写上字儿,这样把 14 页的作业本,浓缩成 2 页,自然翻的页数少了;
二是,另外拿一个本子,把每页的关键字记下来,比如螃蟹在第1,3,5页;冰激淋在第2,4,6页;游戏机在7,8,9页。这样,找起来就少翻几页。
聪明如你,读到这里,一定想到些什么。没错,第一段 SQL 和第二段 SQL,在没有索引的情况下(假设你没有索引的概念),那么第二种写法,反而更慢一些。
大家都是在寻找 age=10 的数据,而第二段SQL,找完之后,还要再找这 10 条数据所在数据页上的其他数据。
相当于,你翻遍作业本,好不容易找到你想到的那段话,和数学公式,发现老师还要求你把那一页上的其他段落或者应用例子,都找出来。这样你需要重复去读,耗时会更多
事实上,经过实验,也的确如此。
在 MySQL 5.5 中,emp_info 有588万数据,没有任何索引和主键。
这儿,我用 employees 库代替。我并没有原问题一模一样的数据。
select SQL_NO_CACHE emp.*
from emp_info emp
where age = 20
limit 100000,10 ;
10 row(s) returned 0.109 sec / 0.000 sec
花费 109ms
select SQL_NO_CACHE emp.*
from emp_info emp
inner join (
select emp_no
from emp_info
where age=20
limit 100000,10) tmp
on tmp.emp_no = emp.emp_no
10 row(s) returned 0.172 sec / 0.000 sec
花费 172ms
细心的朋友会发现,两段 SQL 中都加了 SQL_NO_CAHE. 这是为了防止 Query Cache 的发生,增加说服力。MySQL 5.6 及以下版本都支持 Query Cache, 也就是查询缓存。
解释下为什么要设计 Query Cache.
当二段 SQL 一模一样,连续执行两次时,第二次查询耗时为0. 这是因为,优化器充分利用第一次的缓存数据,秒出结果。
这是怎么做到的?《高性能MuSQL》这本书能告诉你为什么:
简单来说,第一次执行的某条 SQL 会被优化器编译为一段 hash 文本,且它的执行结果,会被存储在内存中。
当一模一样的 SQL 再次发送到优化器时,会和存储的 hash 值做个对比,如果一样,就直接返回内存中的结果,而不需要再次执行。
这功能,想想都兴奋。但,也有弊端。能重复利用缓存,必须是底层数据没有变化,一旦变化了,那么结果就会不对,对于第二次发送 SQL 命令的用户来说,就产生了数据不一致。
在一个非常繁忙的 OLTP 应用中,数据更新出乎你想象的快,查询缓存往往顷刻间就会失效。与其维护这么段失效的内存,不如不维护,空出来干点别的事,多好。
于是 MySQL 8 就废弃了它。
在本例中,加上 SQL_NO_CACHE 这样的 hint 后,就是要排除利用查询缓存带来优化的可能。这样,每次执行都重新走一遍解析,优化到取数。保证实验的公平性。
我把这 588万数据,导入 MySQL 8 版本中,同样执行上面的 SQL,奇迹就来了:
select emp.*
from employee_info emp
where age = 20
limit 100000,10 ;
10 row(s) returned 0.094 sec / 0.000 sec
花费 94ms
select emp.*
from employee_info emp
inner join (
select emp_no
from employee_info
where age=20
limit 100000,10) tmp
on tmp.emp_no = emp.emp_no
10 row(s) returned 4.485 sec / 0.000 sec
花费 4.485s
没想到 MySQL 8 在默认配置下,比 MySQL 5.5 还 “健忘”。翻过的作业,居然一点都不记得。
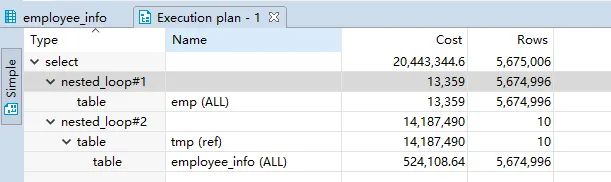
看执行计划知晓,子查询和外层查询,虽然访问同一个表,但却当成两个表来处理。
至此,大家可以清楚的看到,第二种 SQL 不经优化,性能还不如第一种写法。
数据库的索引页结构
刚刚,在讲述提高查询效率的时候,用到了 2 个方法。这两个方法,在数据库中,用索引来实现了。
假设,在作业本上,每一页都写了一篇小散文。我用另外一个本儿,按照关键字,记录这些关键字在作业本中对应出现的页码和行号:
螃蟹:
第 1 页,第 4 行; 第 3 页,第 6 行; 第 5 页,第 8 行
冰激淋:
第 2 页,第 1 行; 第 4 页,第 9 行; 第 6 页,第 5 行
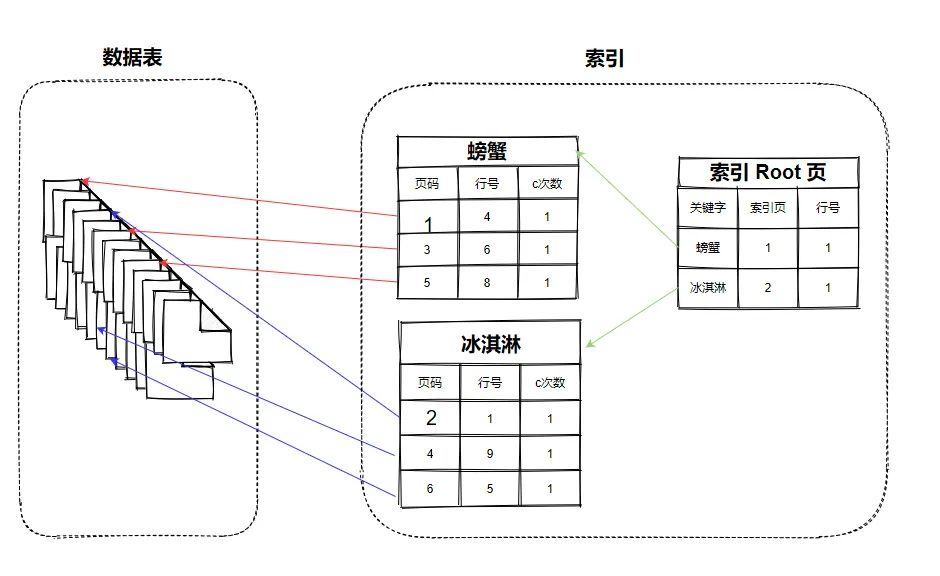
于是,原本按照从作业本,一页页寻找螃蟹,需要翻完所有页,才能找全,现在有了索引本,一页3行,就搞定。
回到面试题来,看第二段 SQL,要找100010 行数据,在索引中找,和在全表中找,消耗的时间,就不在同一个数量级了。
具体来细说。
在作业本上,写的小作文,除了螃蟹,冰激淋等关键字,肯定还有很多很多其他词汇,比如"小妹生日那天,我送给她 2 盒冰激凌,6 只螃蟹,还有 10 多玫瑰"。
这样一来,一页上只出现一个螃蟹,翻完整个本儿,才知道有 5 页是包含螃蟹两字的。
那 user 这张表,也一样,可能有 10 个字段,每个数据页能存上 100 条数据,而每过 10 页,才有一个 age=20 的用户,那么 100000 条数据,可能就被稀释在 1000000 个数据页中。
但索引页就不一样了,100000 个 age=10, 就在 100000行上,每个索引页能存 1000 条,那么 1000 页索引页也就存完了。
通过对比,至少有 1000000/1000 即 1000 倍的时间节省了。
以上只是假设,真实情况,要复杂的多。
有索引的地方,并不简单。因为索引最大的风险,在于回表。
什么是回表?
根据关键字"螃蟹",去找哪一页出现过它,这是索引干的活。但依据"螃蟹"这个关键字,进一步找到作文中的主角,比如"小妹",那索引就做不到了。只能翻开作业本,去每一页包含"螃蟹"的作文中,去找。这种情况,就是回表。
可见,回表又增加了一次操作,会增加耗时。
而第一段 sql, 比起第二段,增加了回表的次数。因为并没指定按照什么去排序,这就是优化器矛盾的地方了。假如加上按照 id 排序,就和第二段一样了。
举个例子:
假设表 employees_info,数据还是588万条,但是加了两样索引:
-- emp_no 为主键
-- 以 age 为索引
select SQL_NO_CACHE emp.*
from employees_info emp
where age = 20
limit 100000,10 ;
10 row(s) fetched - 63ms
看来 MySQL 5.5 优化器在这里做了判断,以 age 为排序,这样最大的消耗在索引访问上。
假设要以 employees_info 其中另外的 from_date 来排序,看下结果:
select SQL_NO_CACHE emp.*
from employees_info emp
where age = 20
order by emp.from_date
limit 100000,10 ;
10 row(s) fetched - 12.63s
这样一来,不仅仅要把索引 age=20 的数据全部找遍,还需回表抓下 from_date 的值。这就是回表的代价。
在 MySQL 8 上,这段 SQL 已经无法跑了,52s 才出结果。
回到写法的对比上来:
select SQL_NO_CACHE emp.*
from employees_info emp
inner join (
select emp_no
from employees_info
where age=20
limit 100000,10) tmp
on tmp.emp_no = emp.emp_no
10 row(s) fetched - 33ms
比起 63ms, 快1倍。
于是,第二种写法,在有索引的情况下,优势就来了。
无论在 MySQL 5.5 还是 MySQL 8, 第二种写法,都具有性能优势。
但是,这道题,是具有歧义的。没有 Order By, Limit 的意义在这两种写法中,就不同。
改成这样,就有对比性了:
select emp.*
from emp_info emp
where age = 20
order by emp.emp_no
limit 100000,10 ;
10 row(s) fetched - 102ms
select emp.*
from emp_info emp
inner join (
select emp_no
from emp_info
where age=20
order by emp_no
limit 100000,10) tmp
on tmp.emp_no = emp.emp_no
10 row(s) fetched - 26ms
这样,第二段 SQL 的优势才能说得清楚。相信看完上面的解释,原理就很清晰了。

推荐阅读
欢迎长按扫码关注「数据管道」