
CVPR2022 Oral | CosFace、ArcFace的大统一升级,AdaFace解决低质量图像人脸识


一直以来,低质量图像的人脸识别都具有挑战性,因为人脸属性是模糊和退化的。
margin-based loss functions的进步提高了嵌入空间中人脸的可辨别性。此外,以往的研究研究了适应性损失的影响,使错误分类(Head)的样本更加重要。在这项工作中,在损失函数中引入了另一个因素,即
图像质量。作者认为,强调错误分类样本的策略应根据其图像质量进行调整。具体来说,简单或困难样本的相对重要性应该基于样本的图像质量来给定。据此作者提出了一种新的损失函数来通过图像质量强调不同的困难样本的重要性。本文的方法通过用
feature norms来近似图像质量,这里是以自适应边缘函数的形式来实现这一点。大量的实验表明,
AdaFace在4个数据集(IJB-B、IJB-C、IJB-S和IJBTinyFace)上提高了现有的(SoTA)的人脸识别性能。
说在前面
对于人脸识别,大家可能觉得已经内卷的差不多了,没什么可以挖掘的了,但是实际上我们还是在有意无意的在回避一些实际落地的问题,
AdaFace则是一个直面落地问题的经典工作,作为CVPR2022的Oral工作当之无愧。其直面低质量人脸图像的识别问题,同时作者通过使用
特征范数来近似图像质量提出一个概括性的损失函数,可以随意在ArcFace和CosFace之间随意游走,在提升低质量图像的识别精度的同时,也没有损失高质量图像的精度,可以说是一个很不错和经典的工作。希望这里的解读可以帮助到大家!!!
这里文中给出最富有总结性的一个表格:

1简介
图像质量是一个属性的组合,表明一个图像如何如实地捕获原始场景。影响图像质量的因素包括亮度、对比度、锐度、噪声、色彩一致性、分辨率、色调再现等。
这里人脸图像是本文的重点,可以在各种灯光、姿势和面部表情的设置下捕捉到的图像,有时也可以在极端的视觉变化下捕捉,如对象的年龄或妆容。这些参数的设置使得学习过的人脸识别模型很难完成识别任务。尽管如此,这项任务还是可以完成的,因为人类或模型通常可以在这些困难的环境下识别人脸。

然而,当人脸图像质量较低时,根据质量程度的不同,识别任务变得不可行。图1显示了高质量和低质量的人脸图像的例子。不可能识别出图1最后1列中的对象。
像图1最下面一行这样的低质量图像正越来越成为人脸识别数据集的重要组成部分,因为它们会在监控视频和无人机镜头中遇到。鉴于SoTA FR方法能够在相对较高质量的数据集,如LFW或CFP-FP中获得超过98%的验证精度,最近的FR挑战已经转向了较低质量的数据集,如IJB-B、IJB-C和IJB-S。虽然挑战是在低质量的数据集上获得较高的准确性,但大多数流行的训练数据集仍然由高质量的图像组成。由于只有一小部分训练数据质量较低,因此在训练期间适当地利用它是很重要的。
低质量的人脸图像的一个问题是,它们往往无法辨认。当图像退化过大时,相关的身份信息从图像中消失,导致图像无法识别。
这些无法识别的图像对训练过程有害的,因为模型将试图利用图像中的其他视觉特征,如服装颜色或图像分辨率,进而会影响训练损失。如果这些图像在低质量图像的分布中占主导地位,那么该模型在测试期间很可能在低质量的数据集上表现不佳。
由于无法识别的面部图像的存在,于是作者便想设计一个损失函数,根据图像质量对不同困难的样本赋予不同的重要性。作者的目标是强调高质量图像的困难样本和低质量图像的简单样本。通常,对样本的不同困难是通过观察训练进展(课程学习)来分配不同的重要性的。然而,作者实验表明,样本的重要性应该通过观察难度和图像质量来调整。
应该根据图像质量不同地设置重要性的原因是,直接强调困难样本总是强烈强调不可识别的图像。这是因为人们只能对无法识别的图像进行随机猜测,因此,它们总是在困难样本中。在将图像质量引入到目标中方面存在着一些挑战。这是因为图像质量是难以量化的,因为它的广泛定义和基于困难的缩放样本经常引入本质上是启发式。
在本工作中,作者提出了一个损失函数,以无缝的方式实现上述目标。作者还发现,
特征范数可以很好地代表图像质量; 不同的裕度函数对不同的样本困难具有不同的重要性。
这2个发现结合在一个统一的损失函数AdaFace中,该函数根据图像质量自适应地改变边缘函数,对不同的样本困难赋予不同的重要性。
主要贡献
提出了一个损失函数, AdaFace,它根据样本的图像质量对不同的困难样本赋予不同的权重。通过结合图像质量,避免强调难以识别的图像,专注于困难但可识别的样本;通过实验表明,角边缘尺度的学习梯度与训练样本的难度相关。这一观察结果促使作者通过自适应地改变边缘函数来强调困难样本,如果图像质量较低,则忽略非常困难的样本(无法识别的图像)。 证明了 feature norms可以作为图像质量的代理。它绕过了需要一个额外的模块来估计图像质量。因此,自适应边际函数不需要额外的复杂度。通过对9个不同质量的数据集(LFW、CFP-FP、CPLFW、AgeDB、CALFW、IJB-B、IJB-C、IJB-S和TinyFace)的广泛评估,验证了该方法的有效性。实验表明, AdaFace在低质量数据集上的识别性能可以大大提高,同时保持在高质量数据集上的性能。
2相关工作
2.1 Margin Based Loss Function
基于Margin的softmax损失函数被广泛应用于人脸识别训练中(FR)。在Softmax损失中加入了Margin,是因为加入Margin后模型可以学习到更好的类间表征和类内表征,特征也就更具有可判别性。典型的形式有:SphereFace、CosFace和ArcFace引入了不同形式的Margin函数。具体来说,它可以t同意写成:

式中,为特征向量与第个分类器权值向量之间的夹角,为Ground Truth(GT)的索引,m为Margin是一个标量超参数。是一个边际函数,其中,SphereFace、CosFace和ArcFace可以用一下3中不同的Margin函数表达:
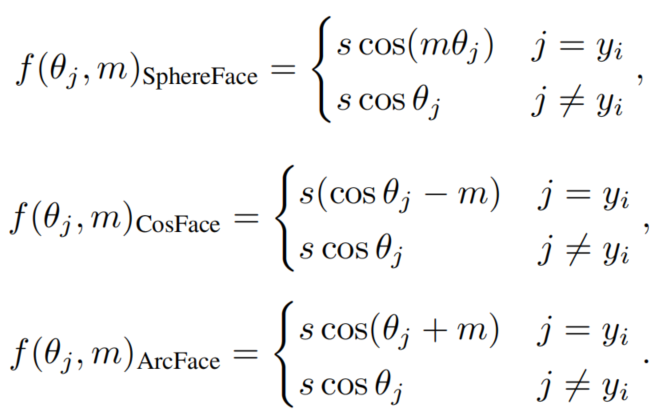
有时,ArcFace被称为angular margin,而CosFace被称为additive margin。这里,是一个用于缩放的超参数。P2SGrad中注意到m和s是敏感的超参数,并建议直接修改梯度,使其没有m和s超参数。
AdaFace旨在将Margin建模为图像质量的函数,因为影响在训练过程中哪些样本贡献了更多的梯度(即学习信号)。
2.2 Adaptive Loss Functions
许多研究在训练目标中引入了适应性元素,用于hard sample mining、训练期间的调度困难或寻找最优超参数。例如,CurricularFace将课程学习的思想引入到损失函数中。在训练的最初阶段,(负余弦相似度)的Margin被设置为很小,以便容易样本的学习,在后期阶段,Margin被增加,以便Hard样本可以学习。具体来说,它被写成:
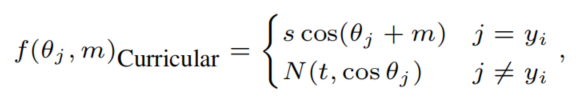
其中,

而是一个随着训练的进展而增加的参数。因此,在CurricularFace中,Margin的适应性是基于训练的进展(Curricular)。
相反,作者认为Margin的适应性应该基于图像质量。在高质量的图像,如果样本是很困难的(对模型),网络应该学会利用图像中的信息;但在低质量的图像,如果样本是很困难的,它更有可能是缺乏适当的身份的线索,那么网络不应该去学习相关的特征。
MagFace探索了基于可识别性应用不同Margin的想法。它在high norm features易于识别的前提下,对high norm features应用大角度Margin。大Margin推动high norm features更接近class中心。然而,它并没有强调困难的训练样本,但是这些困难样本对学习鉴别特征也很重要。
同样值得一提的是,DDL使用蒸馏损失来最小化简单和困难样本特征之间的差距。
2.3 低质量图像的人脸识别
最近的FR模型在人脸属性可识别的数据集上取得了较高性能,例如LFW、CFP-FP、CPLFW、AgeDB和CALFW。当FR模型学习不受光照、年龄或姿态变化影响的鉴别特征时,可以在这些数据集上获得良好的性能。
然而,在不受约束的情况下,如监控或低质量的视频,FR便会带来很多的问题。这种配置下的数据集包括IJB-B、IJB-C和IJB-S,其中大多数图像质量很低,有些甚至不包含足够的身份信息,即使是对人工检查人员来说。良好表现的关键包括:
学习低质量图像的可鉴别特征; 学习丢弃包含少量识别线索的图像(质量感知融合)。
为了进行质量感知融合,人们提出了概率方法来预测FR表示中的不确定性。假设特征是分布,其中方差可以用来计算预测的确定性。然而,由于训练目标的不稳定性,概率方法会分别采用学习均值和方差,这在训练过程中并不简单,因为方差是用一个固定的均值来优化的。然而,AdaFace是对传统的softmax损失的一个修改,使框架易于使用。此外,AdaFace使用feature norms作为质量感知融合过程中预测质量的代理。
合成数据或数据扩充可以用来模拟低质量的数据。有方法通过训练人脸属性标记器生成训练数据的伪标签。这些辅助步骤只会使训练过程复杂化,并使其难以推广到其他数据集或领域。AdaFace方法只涉及简单的裁剪、模糊和光照增强,这也适用于其他数据集和域。
3本文方法
样本的Cross entropy softmax loss可以表述为:
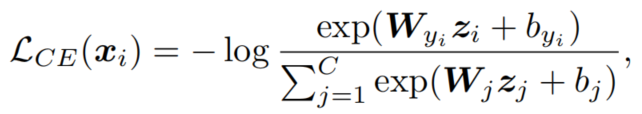
其中是的特征嵌入,属于第类。为最后一个FC层权值矩阵的第列,,为对应的偏置项。C表示类的数量。
在测试时间内,对于任意一对图像,和,使用余弦相似度度量来寻找最接近的匹配恒等式。为了使训练目标直接优化余弦距离,使用normalized softmax,其中偏差项设置为零,然后特征通过归一化和缩放参数进行了转换:
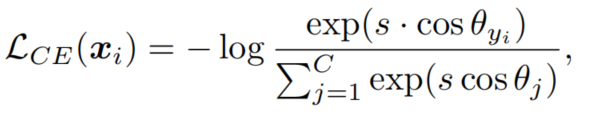
其中,对应于和之间的夹角。并引入了Margin来减少类内的变化。通常,它可以被写成ArcFace等的统一表达式,其中Margin函数在方程式中定义。
3.1 Margin Form and the Gradient
先前关于基于Margin的Softmax的工作主要集中在Margin如何改变决策边界以及它们的几何解释。在本节中,作者展示了在反向传播过程中,由于Margin而引起的梯度变化会影响到一个样本相对于其他样本的重要性的影响。换句话说,angular margin可以在梯度方程中引入一个附加项,根据样本的难度对信号进行缩放。为了证明这一点,作者将研究梯度方程如何随Margin函数而变化。
设为对输入进行softmax后在第类上的概率。通过推导的梯度方程和,可以得到如下:
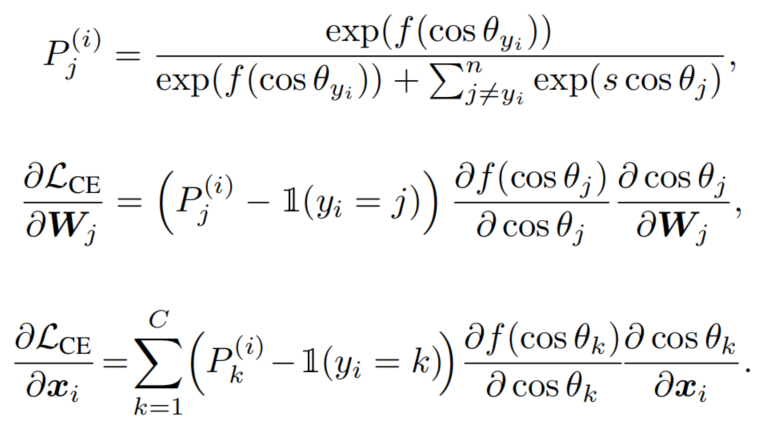
在等式中,和是标量。此外,这两个项是唯一受参数到影响的项。没有m,这里可以把前2个标量项看作是一个梯度尺度项(GST),并表示为:

为了GST分析的目的,将考虑类指数,因为所有负类指数在方程中没有Margin。于是normalized softmax loss的GST为:

因为和=s。所以CosFace的GST同样也是:
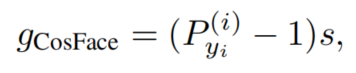
通过定义和=s。所以ArcFace的GST如下:
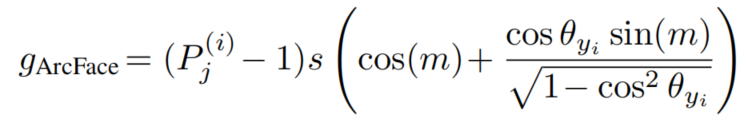
因为GST是和m的函数,就像在等式中一样、可以用它根据样本的困难成都来控制对样本的强调,即训练期间的。
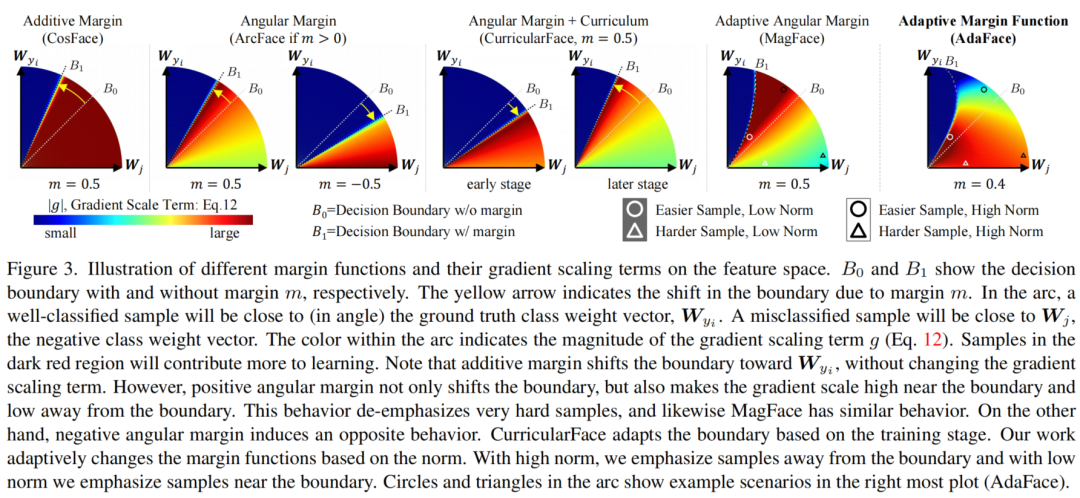
为了了解GST的效果,图3为GST在特征空间中的颜色。需要注意的是,对于angular margin,GST在决策边界达到峰值,但随着它向移动而逐渐减小,而较困难的样本得到的强调较少。如果改变angular margin的符号,会看到相反的效果。
请注意,在第6列中,MagFace是ArcFace的扩展,具有更大的Margin分配给高范数特征。ArcFace和MagFace都没有高度重视困难样本(附近的绿色区域)。结合所有的Margin函数,以在必要时强调困难样本。
请注意,这种适应性也不同于使用训练阶段来改变样本中不同困难的相对重要性的方法。图3显示了
CurricularFace,其中决策边界和GST g随训练阶段的不同而变化。
3.2 Norm and Image quality
图像质量是一个综合性的术语,它涵盖了诸如亮度、对比度和锐度等特征。图像质量评估(IQA)在计算机视觉中得到了广泛的研究。SER-FIQ是一种用于人脸IQA的无监督DL方法。Brisque是一种流行的blind/no-reference IQA算法。
然而,这些方法在训练过程中使用的计算成本很高。在这项工作中避免引入一个额外的模块来计算图像质量。相反,使用特征规范作为图像质量的代理。作者观察到,在使用基于Margin的Softmax Loss训练的模型中,特征范数表现出与图像质量相关的趋势。
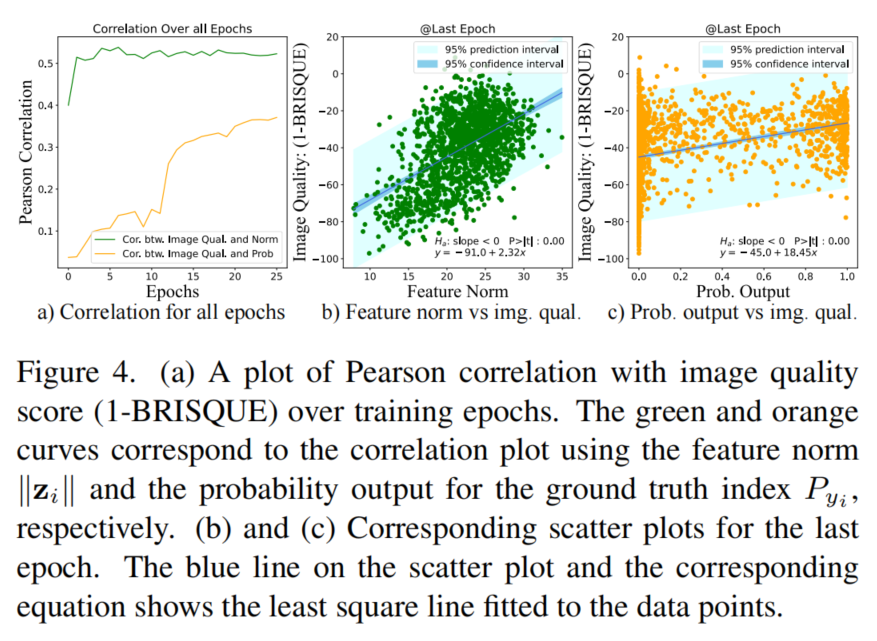
在图4(a)中显示了特征范数与图像质量(1-brisque)作为绿色曲线计算的图像质量(IQ)得分之间的相关图。从训练数据集随机抽取1534张图像(MS1MV2)并使用预先训练好的模型计算特征范数。在最后一个阶段,特征规范与IQ score之间的相关性得分达到0.5235(超过−1和1)。对应的散点图如图4(b)所示,特征范数和IQ score之间的高相关性支持了使用特征范数作为图像质量的代理。
在图4(a)中还展示了概率输出与IQ score之间的相关图,其曲线为橙色曲线。注意,特征范数的相关性总是比高。此外,特征范数与IQ score之间的相关性在训练的早期阶段是可见的。这对于使用特征范数作为图像质量的代理是一个有用的属性,因为可以依赖于训练的早期阶段的代理。
此外,在图4(c)中展示了与IQ score之间的散点图。注意,和图像质量之间存在非线性关系。描述样本难度的一种方法是使用,图中显示了样本难度的分布随图像质量的不同而不同。因此,根据难度调整样本重要性时考虑图像质量是有意义的。
3.3 AdaFace: Adaptive Margin based on Norm
为了解决不可识别图像引起的问题,作者提出基于特征范数来适应Margin函数。在第二节中已经证明,使用不同的Margin函数可以强调样本的不同困难成都。另外,观察到特征规范是寻找低质量图像的好方法。
1、Image Quality Indicator
作为特征范数,是一个模型依赖的量,使用batch统计和对其进行归一化。具体来说:

其中,和为一个batch内所有的平均值和标准差。[]是指在−1和1之间裁剪值,阻止梯度流动。
由于将的Batch分布近似为单位高斯分布,因此将该值剪辑在−1和−1范围内,以便更好地处理。
已知,大约68%的单位高斯分布落在−1和1之间,因此引入项h来控制concentration。设置h,使大多数值落在−1和1之间。实现这一点的将是h=0.33。
如果Batch size较小,则Batch统计信息和可能不稳定。因此,使用和跨多个步骤的指数移动平均数(EMA)来稳定Batch统计数据。具体来说,设和是的第k步批统计。然后:

α的动量设定为0.99。对于也是如此。
2、Adaptive Margin Function
作者设计了一个Margin函数:
如果图像质量高,强调困难样本 如果图像质量低,不强调困难样本
用2个自适应和来实现这一点,分别指angular margin和additive margins。具体来说:
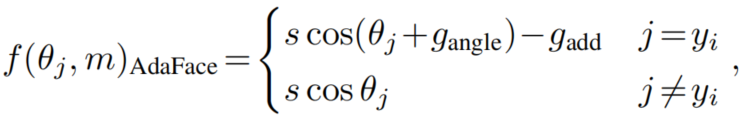
其中和是的函数:
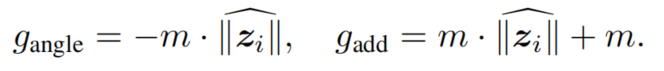
请注意,当=−1时,建议的函数变成了ArcFace。当=0时,它就变成了CosFace。当=1时,它变成了negative angular margin。
图3显示了自适应函数对梯度的影响。高范数特征在远离决策边界的情况下得到较高的梯度尺度,而低范数特征在决策边界附近得到较高的梯度尺度。对于低范数特征,远离边界的较难样本被弱化。
4实验
4.1 消融实验
1、图像质量指标h的影响
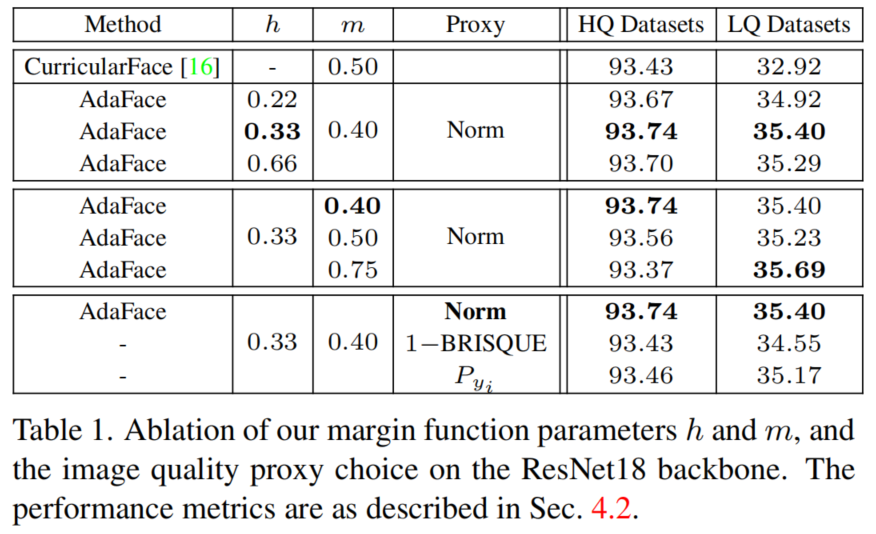
如表1所示。当h=0.33时,模型表现最佳。当h=0.22或h=0.66时,成绩仍然高于curriculum face。只要把h设置成类似的情况,就仅仅只是一些变化,h不是很敏感。这里设h=0.33。
2、超参数m的影响
Margin m既对应于angular margin的最大范围,也对应于additive margins的大小。从表1可以看出:
对于HQ数据集,m=0.4时性能最好, 对于LQ数据集,m=0.75时性能最好。
m越大,基于图像质量的angular margin变化也越大,自适应能力越强。在后续的实验中,选择m=0.4,因为它在LQ数据集上有很好的性能,而在HQ数据集上又不牺牲性能。
3、代理选择的影响
在表1中,为了显示使用特征范数作为图像质量代理的有效性,将特征范数与其他数量进行了切换,例如(1-BRISQUE)或。使用特征规范的性能优于使用其他范数。对于训练数据集,BRISQUE评分是预先计算的,因此当使用增强训练时,它不能有效地捕捉图像质量。作者引入来说明特征范数的适应性不同于难度的适应性。
4、数据增强的影响
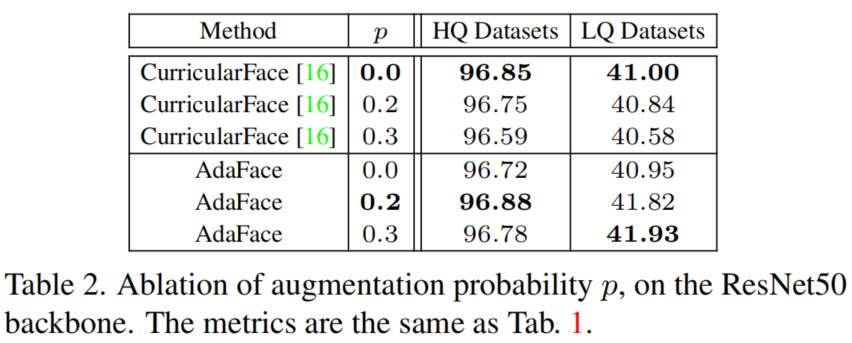
表2显示,数据增强确实为AdaFace带来了性能提升。HQ数据集的性能保持不变,而LQ数据集的性能显著提高。需要注意的是,数据增强会影响CurricularFace的性能,这与假设是一致的,即数据增强是获得更多数据的积极效果和无法识别的图像的消极效果之间的权衡。基于Margin的softmax之前的工作不包括动态增强,因为性能可能会更差。AdaFace避免了对不可识别图像的过拟合,可以更好地利用增强效果。
分析
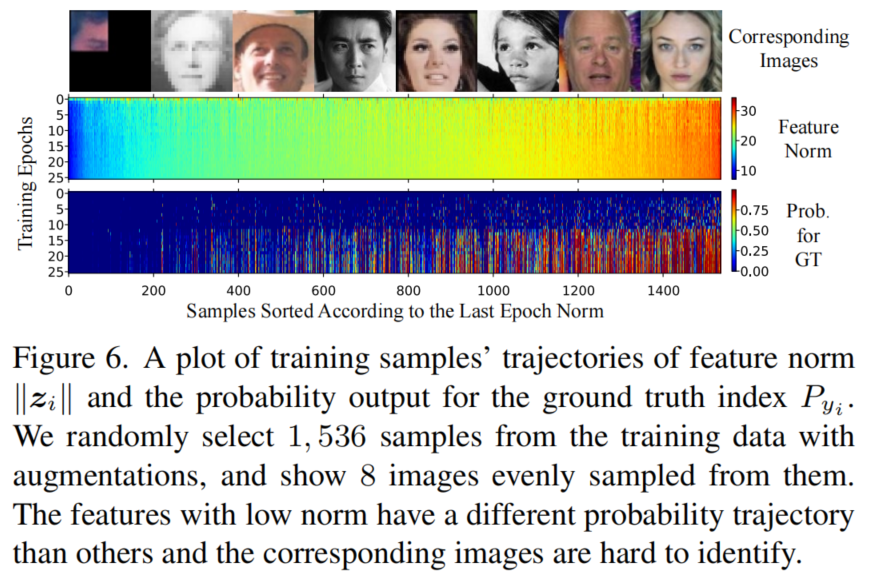
为了显示特征范数以及训练样本的难度在训练过程中的变化情况,在图6中绘制了样本轨迹。从训练数据中随机抽取共计1536个样本。热力图中的每一列代表一个样本,x轴是根据上一个Epoch的范数排序的。
样本#600大约是低范数样本向高范数样本过渡的中间点。底部的图显示,许多低范数样本的概率轨迹直到最后才得到高概率。这与假设是一致的,低规范特征更可能是无法识别的图像。这证明了不太重视这些案例的动机,尽管它们是很难的案例。
低范数特征比高范数特征具有增强的样本百分比更高。对于编号为#0到#600的样本,大约62.0%的样本至少有一种类型的增强。对于#600或更高的样本,该百分比约为38.5%。
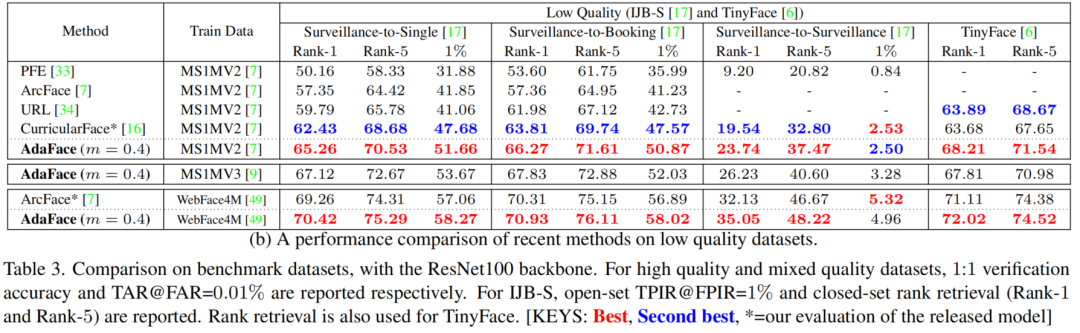
4.2 SOTA方法对比

4.3 局限性与影响
1、局限性
这项工作解决了训练数据中存在的无法识别的图像。然而,噪声标签也是大规模人脸训练数据集的突出特征之一。AdaFace损失函数对贴错标签的样品没有特殊处理。由于自适应损失赋予高质量的困难样本很大的重要性,高质量的错误标记图像可能会被错误地强调。未来可以同时适应不可识别性和标签噪声。
2、潜在的社会影响
作者认为,计算机视觉社区作为一个整体,应该努力尽量减少负面的社会影响。论文的实验使用了训练数据集MS1MV*,这是MS-Celeb的副产品,一个由其创建者撤回的数据集。
使用MS1MV*是必要的,以比较本文的结果与SoTA方法的公平对比。然而,作者认为社区应该转向新的数据集,所以作者还在最新发布的WebFace4M进行了,以促进未来的研究。
在科学界,收集人类数据需要获得伦理委员会的批准,以确保知情同意。虽然IRB状态通常不是由数据集创建者提供的,但由于收集过程的性质,假设大多数FR数据集(除了IJB-S)没有IRB。FR社区的一个方向是在知情同意的情况下收集大型数据集,促进没有社会关注的研发。
检索展示
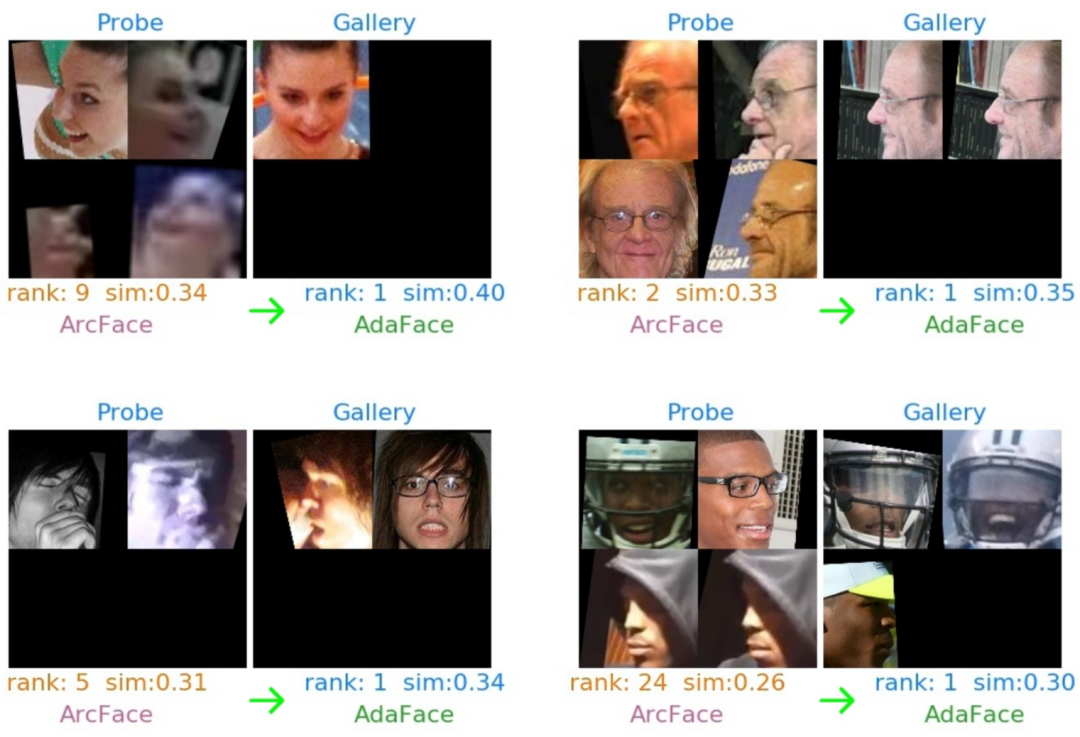
可以看到使用AdaFace得到的gallery结果的置信度都比ArcFace要高。
5参考
[1].AdaFace: Quality Adaptive Margin for Face Recognition
6推荐阅读
YOLOv5永不缺席 | YOLO-Pose带来实时性高且易部署的姿态估计模型!!!
Transformer崛起| TopFormer打造Arm端实时分割与检测模型,完美超越MobileNet!
阿里巴巴提出USI 让AI炼丹自动化了,训练任何Backbone无需超参配置,实现大一统!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
