
CVPR2022 Oral:StreamYOLO-流感知实时检测器
【GiantPandaCV导语】 自动驾驶技术对延迟要求极高。过去的工作提出了信息流(后文均称Streaming)感知联合评价指标,用于评估算法速度和准确性。本论文提出检测模型对于未来的预测是处理速度和精度均衡的关键。作者建立了一个简单有效的Streaming感知框架。它配备了 一种新的**双流感知模块(Dual Flow Perception,DFP),其中包括捕捉动态Streaming和静态Streaming移动趋势的基本检测特征。此外,作者引 入了一个趋势感知损失(Trend-Aware Loss,TAL)**,并结合趋势因子,为不同移动速度的物体生成自适应权重。本文提出的方法在Argogrse-HD数据集上实展现了竞争性能,与原Baseline相比提高了4.9% mAP。
Paper:https://arxiv.org/abs/2203.12338
Code:https://github.com/yancie-yjr/StreamYOLO.
1、介绍
自动驾驶对模型延迟有着极高的要求,当处理完当前帧,环境早已发生变化。结果感知和变化状态的不一致可能造成危险情况的发生。为了解决该问题,《Towards streaming perception》论文提出新的信息流度量指标,它将速度和精度集成到一个实时感知度量中。此外,该论文还提出了一种名为Streamer的元检测器,它可以将任何检测器与决策调度、异步跟踪和未来预测相结合,以提升检测器的性能。后来,Adaptive Streamer采用了大量基于深度强化学习的近似计算,以获得更好的检测均衡。
由于streaming感知的是当前帧结果,校准总是由下一帧进行匹配和评估。作者发现现在的性能差距都来自于当前处理帧和下一匹配帧之间的固定不一致,如下图。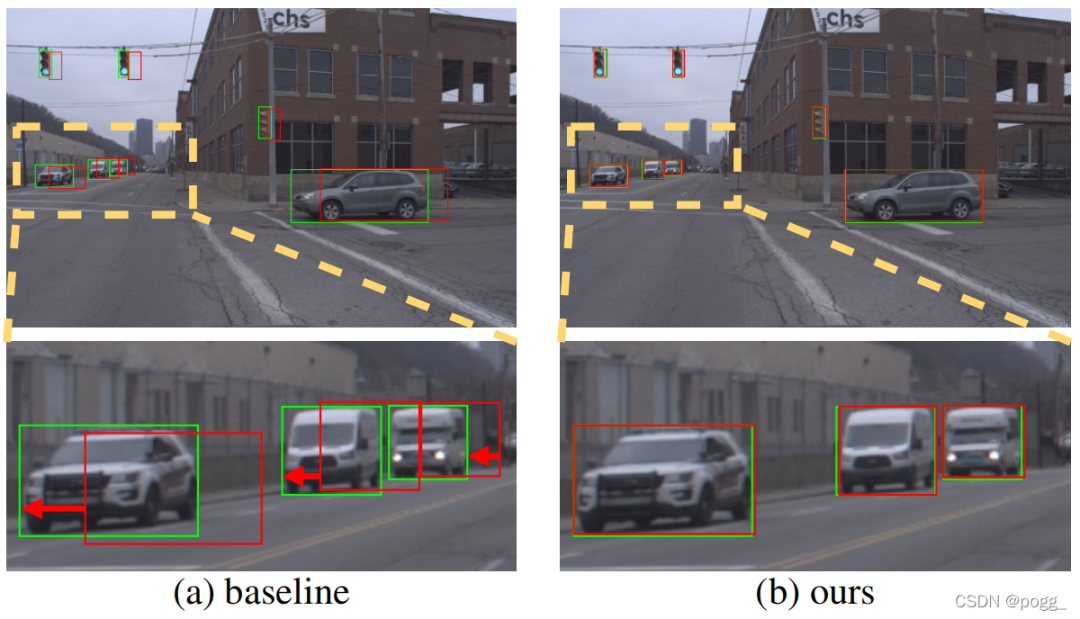 上图为基础探测器的可视化和本文方法的可视化。绿色的盒子是实际对象,而红色的盒子是预测对象。红色箭头表示由处理时间延迟导致预测盒的漂移,而本文的方法缓解了这个问题。
上图为基础探测器的可视化和本文方法的可视化。绿色的盒子是实际对象,而红色的盒子是预测对象。红色箭头表示由处理时间延迟导致预测盒的漂移,而本文的方法缓解了这个问题。
具体地说,需要构造前一帧、当前帧和下一帧信息的三元组进行训练,其中模型得到前一帧和当前帧作为输入,并学习预测下一帧的结果。作者提出了两个关键的设计来提高训练效率:
对于模型架构,设计一个双流感知(DFP)模块来融合最后一帧和当前帧的特征图。它由动态流和一个静态流组成。动态流关注预测对象的运动趋势,而静态流通过残差连接提供检测对象的基本特征。 对于训练策略, 作者发现一帧内的物体可能有不同的速度,因此引入了一个趋势感知损失(TAL)来动态分配不同的权值以预测每个对象。
相对于Baseline, StreamYOLO的mAP提高了4.9%,并在不同行驶速度下实现了鲁棒预测。
2、流媒体感知
流媒体感知任务连贯地考虑了延迟和准确性。《Towards streaming perception》首先提出了一种考虑时延的sAP来评估精度。并提出了一种元检测器,通过采用卡尔曼滤波器、决策调度和异步跟踪来缓解这一问题。
下图为实时检测器和非实时检测器的比较。每个块代表一帧检测器的过程,F0-F5一共包含五帧,其长度表示运行时间。虚线块表示接收到下一帧数据的时间。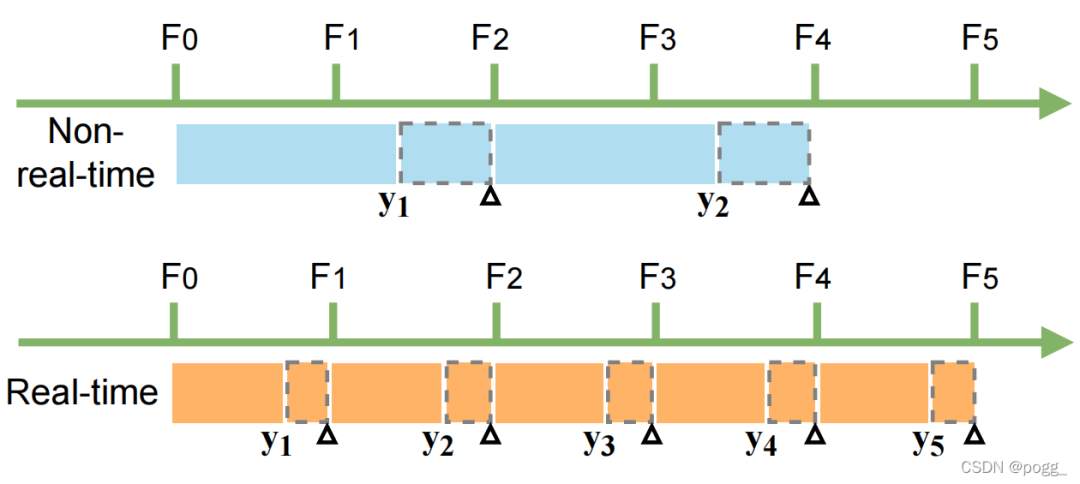 对于非实时检测器而言:
对于非实时检测器而言:
帧 F1 的输出结果 y1 与 F3 的Ground Truth Box进行匹配和评估,而 F2 的结果被遗漏。 对于流感知的任务,非实时检测器可能会丢失图像帧并产生框偏移的结果。
对于实时检测器而言;
如何定义实时这个概念,作者认为在一个实时检测器中,一帧图像的总处理时间应当小于图像流传输的时间间隔 实时检测器通过将下一帧对象与当前预测的结果准确匹配,避免了移位问题
作者比较了两种探测器,Mask R-CNN(非实时)和YOLOX(实时),研究了流媒体感知和离线检测之间的性能差距。在低分辨率输入的情况下 ,两者性能差距很小,均能实时运行。随着分辨率的提高,Mask R-CNN的运行速度下降,而YOLOX仍保持实时性,下图所示。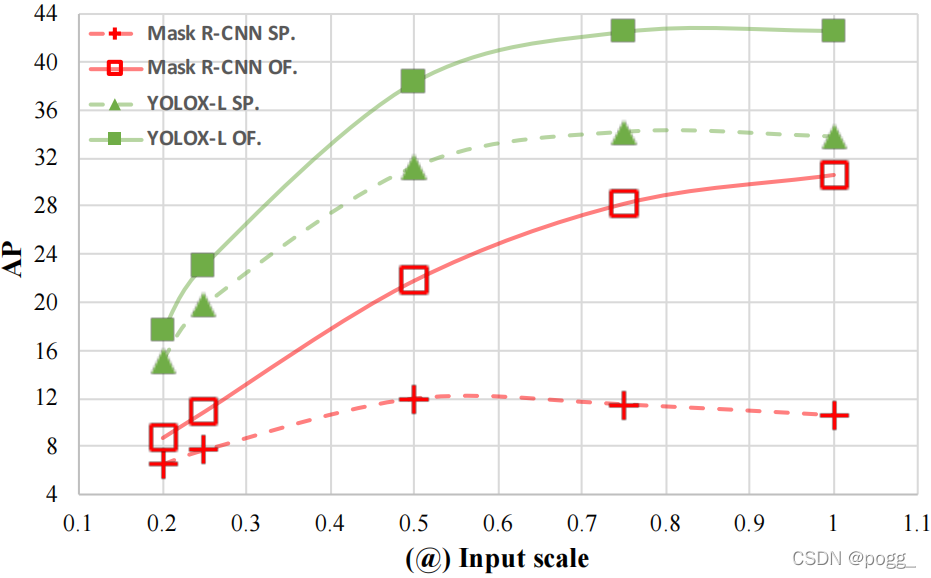 “OF”和“SP”分别表示离线和流媒体感知测试,@后的数字是输入分辨率的缩放值(基准为1200×1920)。
“OF”和“SP”分别表示离线和流媒体感知测试,@后的数字是输入分辨率的缩放值(基准为1200×1920)。
3、 方法
Baseline: 根据上述分析,作者使用YOLOX作为Baseline
训练: 作者使用上一帧、当前帧和下一帧的GT框(Ft-1, Ft, Gt+1)构造成一个三元组进行训练,取两个相邻的帧(Ft-1, Ft)作为输入,训练模型预测下一帧的GT(predict),由Ft帧的真实GT(True)监督Gt+1的GT,基于输入和监督的三元组,作者将训练数据集重建为 的形式。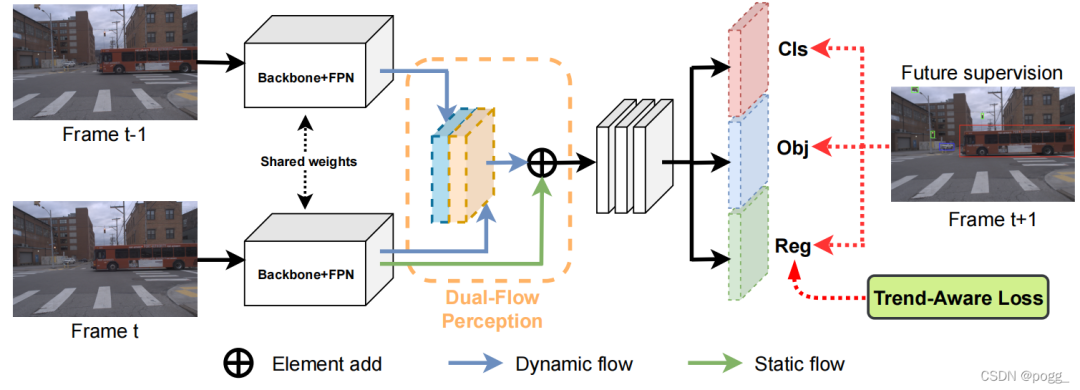 作者采用共享权重CSPDarknet-53来提取前一帧和当前帧的FPN特征,使用本文所提出的双流感知模块(DFP)来聚合特征图,并将它们传输到检测头。接着直接利用下一帧的GT进行监督。在此期间,作者设计了一个趋势感知损失(TAL)应用于Reg分支检测头进行有效的训练。
作者采用共享权重CSPDarknet-53来提取前一帧和当前帧的FPN特征,使用本文所提出的双流感知模块(DFP)来聚合特征图,并将它们传输到检测头。接着直接利用下一帧的GT进行监督。在此期间,作者设计了一个趋势感知损失(TAL)应用于Reg分支检测头进行有效的训练。
双流感知模块(DFP): 作者设计了一个双流感知(DFP)模块,用动态流和静态流来编码预期的特征,如上图。动态流融合了两个相邻帧的FPN特征来学习运动信息。它首先使用一个共享的权值1×1 卷积层,BN和 SiLU,并将两个FPN特性的channel减少到一半。DFP只是简单地将这特征cat起来,作者研究了其他几种融合操作,如add、 non-local block、STN或SE block,其中cat实现了最好的性能,见下表。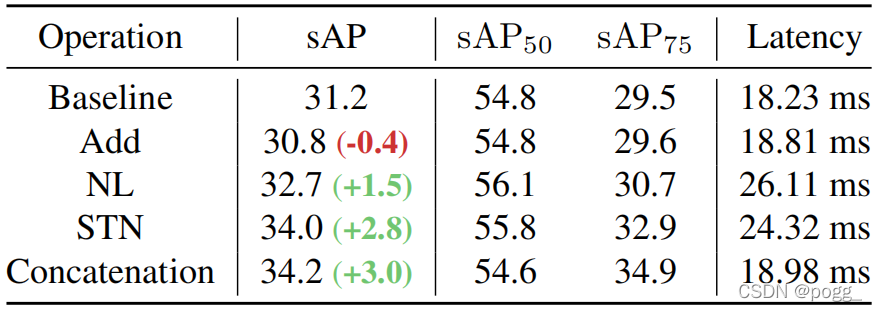 对于静态流 ,作者通过一个残差连接,合理地添加了当前帧的原始特征。在随后的实验中,作者发现静态流不仅为检测提供了基本的特征信息,还提高了驾驶车辆在不同移动速度下的预测鲁棒性。
对于静态流 ,作者通过一个残差连接,合理地添加了当前帧的原始特征。在随后的实验中,作者发现静态流不仅为检测提供了基本的特征信息,还提高了驾驶车辆在不同移动速度下的预测鲁棒性。
趋势感知损失(TAL): 作者注意到流媒体感知中每个物体在同一帧内的移动速度是完全不同的。不同的趋势来自于多方面:不同的大小和它们自身的移动状态,遮挡 ,或不同的拓扑距离。基于观察结果,作者引入了一个趋势感知损失(TAL), 它根据每个物体的移动趋势对其采用自适应权值。为了定量地测量移动速度,作者为每个物体引入了一个趋势因子。计算了和两帧GT之间的IoU矩阵,然后对帧的维度进行求最大值运算,得到两帧之间检测对象的匹配IoU。这个匹配的IoU值小意味着物体移动速度快,反之亦然。如果新对象出现在帧中,则没有与之匹配的框。我们设置了一个阈值T来处理这种情况,并将中每个对象的最终趋势因子 ωi 表示为:
其中表示中方框间的最大操作值t,ν是新对象的恒定权重。我们将ν设置为1.4(大于1)(根据超参数网格搜索)。
我们重新加权每个对象的回归损失,总损失表示为:
4、实验
数据集: 我们在视频自动驾驶数据集 Argoverse-HD( 高帧率检测)上进行了实验,其中验证集包含24个视频,总共15k帧。
评估指标: 使用sAP作为主要评价指标
实验细节: 使用YOLOX-L作为默认检测器,所有的实验都是对COCO预训练模型进行了15个epoch的微调,在8G RTX2080ti上将Batch Size设置为32,并使用随机梯度下降法(SGD)来进行训练。调整学习率为,使用1个epoch的warm up和余弦下降法,权重衰减为 0.0005,SGD动量为0.9。input size为600×960,不使用任何数据增强(如马赛克,Mixup,水平翻转等) 。在推理上,作者将输入大小保持在600×960 ,并Tesla V100GPU上测试。
信息融合: 融合前一帧信息和当前帧信息对于流媒体任务非常重要。作者选择三种不同的特征模式来融合:Input、Backbone和FPN。输入特征为将两个相邻的帧concat在一起。可以看到,Input和Backbone融合模式使性能降低了0.9和0.7 AP,FPN模式显著提高了 3.0AP。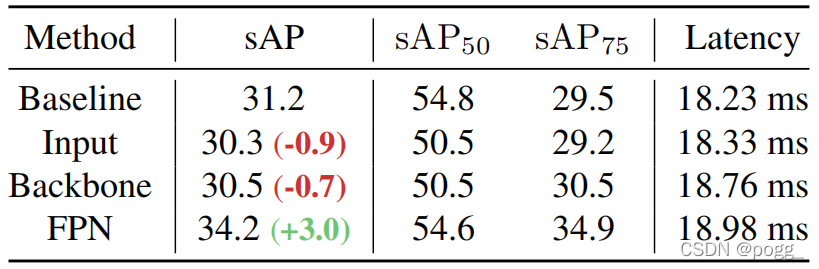 DFP和TAL的影响: 作者在不同Input Size上对YOLOX进行了多项实验,实验结果可以看下图,Pipe为原模型
DFP和TAL的影响: 作者在不同Input Size上对YOLOX进行了多项实验,实验结果可以看下图,Pipe为原模型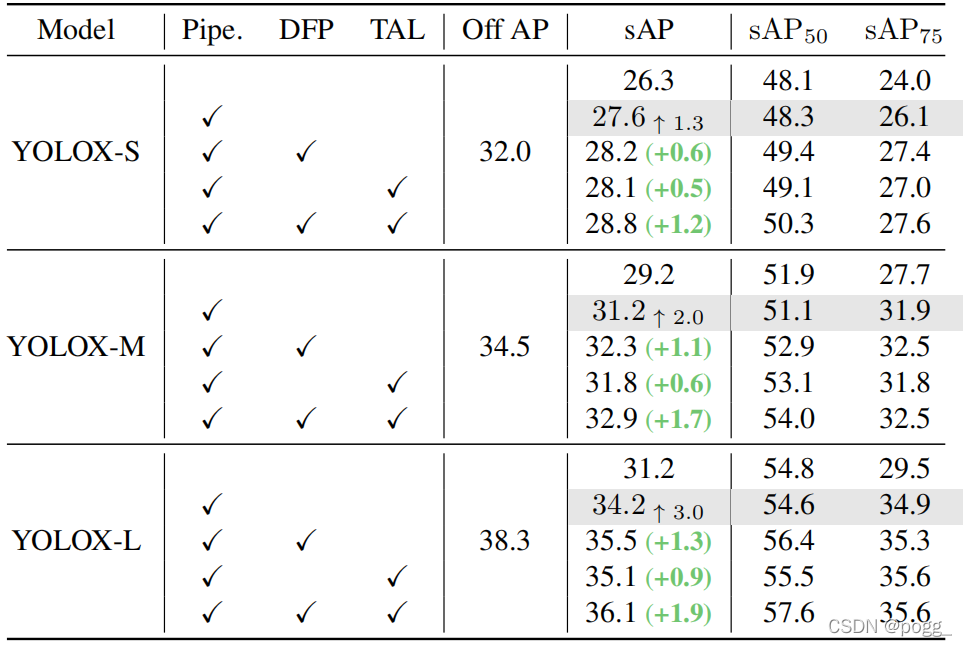 DFP 和 TAL 可以将 sAP 的准确率提高 大约1.0 AP,它们的组合进一步提高了近 2.0 AP 的性能。
DFP 和 TAL 可以将 sAP 的准确率提高 大约1.0 AP,它们的组合进一步提高了近 2.0 AP 的性能。
和: 的值作为一个阈值来监控新对象,而控制对新对象的关注程度。 作者将 设置为大于 1.0。并对这两个超参数进行网格搜索。
如下图所示, 和 分别在 0.3 和 1.4 时达到最佳性能。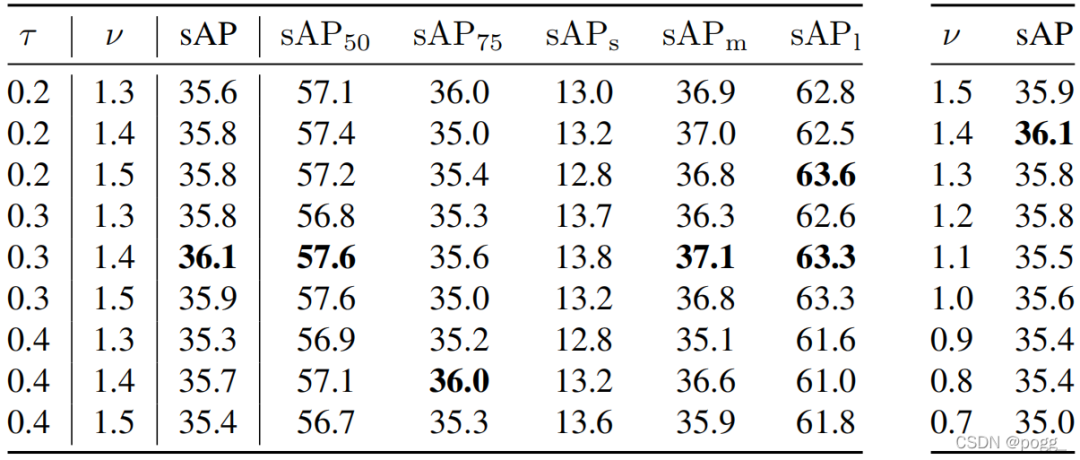 不同速度下的性能: 对于0x速度(即静态图片),预测结果应该与2D图像检测(离线测试)的结果相同。但是,采用视频流的方式,可以看到与离线相比性能显著下降(-1.9 AP),这意味着模型的推断存在误差。通过DFP模块,可以恢复了性能下降的趋势。
不同速度下的性能: 对于0x速度(即静态图片),预测结果应该与2D图像检测(离线测试)的结果相同。但是,采用视频流的方式,可以看到与离线相比性能显著下降(-1.9 AP),这意味着模型的推断存在误差。通过DFP模块,可以恢复了性能下降的趋势。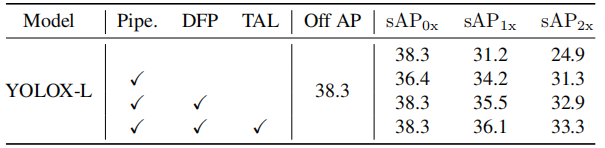 与卡尔曼滤波的比较:下表报告了基于卡尔曼滤波器的预测与作者提出的方法的对比。对于普通的sAP (1×),作者的方法仍然比高级基线高 0.5 AP。此外,以更快的移动速度(2×)评估时,作者的模型显示出更强的鲁棒性优势(33.3 sAP 与 31.8 sAP),带来了更少的额外推理延迟(0.8 ms对 3.1 ms)。
与卡尔曼滤波的比较:下表报告了基于卡尔曼滤波器的预测与作者提出的方法的对比。对于普通的sAP (1×),作者的方法仍然比高级基线高 0.5 AP。此外,以更快的移动速度(2×)评估时,作者的模型显示出更强的鲁棒性优势(33.3 sAP 与 31.8 sAP),带来了更少的额外推理延迟(0.8 ms对 3.1 ms)。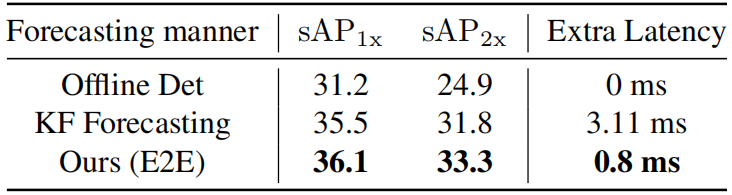 结果可视化: 如作者展示了可视化结果。对于Baseline检测器,预测边界框会遇到严重的滞后。车辆和行人移动得越快,预测的变化就越大。对于像红绿灯这样的小物体,预测框和GT之间的重叠变得很小,甚至没有。相比之下,作者的方法减轻了预测框和移动对象之间的不匹配,并准确拟合结果。
结果可视化: 如作者展示了可视化结果。对于Baseline检测器,预测边界框会遇到严重的滞后。车辆和行人移动得越快,预测的变化就越大。对于像红绿灯这样的小物体,预测框和GT之间的重叠变得很小,甚至没有。相比之下,作者的方法减轻了预测框和移动对象之间的不匹配,并准确拟合结果。
总结
本文重点关注处理延迟的Streaming感知任务。在这个任务下,作者提出了使用具有未来预测能力的在线感知实时检测器,并进一步构建了双流感知模块(DFP)和趋势感知损失(TAL),缓解了流感知中的处理滞后问题。大量实验表明,该实时检测器表现出Sota性能,并在不同的测试速度下获得了稳健的结果。