
【59期】MySQL索引是如何提高查询效率的呢?(MySQL面试第二弹)

阅读本文大概需要 11 分钟。
来自:juejin.im/post/5cb1dec9f265da0382610968
About MySQL
Why MySQL
运行速度快
易使用
SQL语言支持
移植性好
功能丰富
成本低廉

MySQL Index
SELECT语句从数据表中查询部分数据行的时候,得到的就是另外一个数据表和数据行的集合。索引是如何工作的
t_user_action_log 表,方便下面进行演示。CREATE DATABASE `ijiangtao_local_db_mysql` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE ijiangtao_local_db_mysql;
DROP TABLE IF EXISTS t_user_action_log;
CREATE TABLE `t_user_action_log` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` VARCHAR(32) DEFAULT NULL COMMENT '用户名',
`ip_address` VARCHAR(50) DEFAULT NULL COMMENT 'IP地址',
`action` INT4 DEFAULT NULL COMMENT '操作:1-登录,2-登出,3-购物,4-退货,5-浏览',
`create_time` TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 1, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.1', 2, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 1, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.3', 1, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 2, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.4', 1, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 2, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.1', 1, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 2, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 1, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 3, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 5, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 2, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 2, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 3, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 3, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 5, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 3, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 3, CURRENT_TIMESTAMP);
INSERT INTO t_user_action_log (name, ip_address, `action`, create_time) values ('LiSi', '8.8.8.2', 4, CURRENT_TIMESTAMP);
action为2的所有记录,SQL如下:SELECT id, name, ip_address FROM t_user_action_log WHERE `action`=2;
explain分析这条查询语句:EXPLAIN SELECT id, name, ip_address FROM t_user_action_log WHERE `action`=2;

type为ALL表示要进行全表扫描。这样效率无疑是极慢的。下面为
action列添加索引:ALTER TABLE t_user_action_log ADD INDEX (`action`);

Extra的值是Using Where,加索引后Extra的值为空。
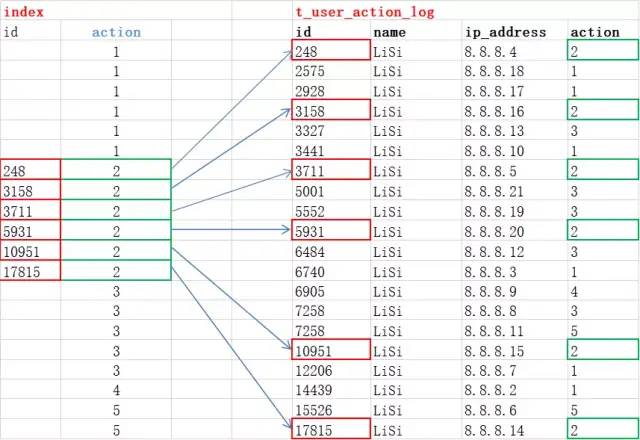
action值为2的索引值分类存储在了索引空间,可以快速地查询到索引值所对应的列。如何使用
创建索引
CREATE INDEX创建,语法如下:CREATE INDEX indexName ON tableName (columnName(length));
ip_address这一列创建一个长度为16的索引:CREATE INDEX index_ip_addr ON t_user_action_log (ip_address(16));
ALTER语句创建,语法如下:ALTER TABLE tableName ADD INDEX indexName(columnName);
ALTER语句创建索引前面已经有例子了。下面提供一个设置索引长度的例子:ALTER TABLE t_user_action_log ADD INDEX ip_address_idx (ip_address(16));
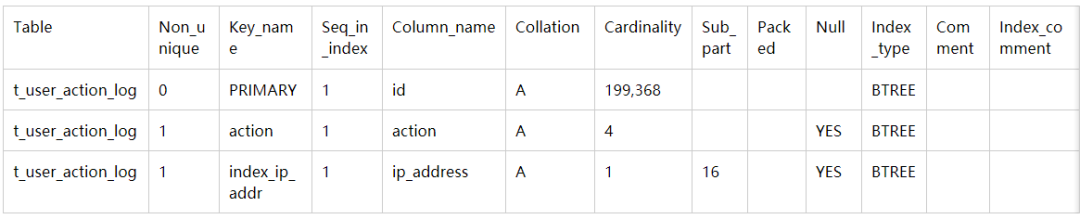
SHOW INDEX FROM t_user_action_log;

id INT NOT NULL,
columnName columnType,
INDEX [indexName] (columnName(length))
);
查看索引
show语句查看索引:SHOW INDEX FROM t_user_action_log;
删除索引
ALTER命令可以删除索引,例如:ALTER TABLE t_user_action_log DROP INDEX index_ip_addr;
索引的使用原则
写操作比较频繁的列慎重加索引
索引越多占用磁盘空间越大
不要为输出列加索引
select ip_address from t_user_action_log
where name='LiSi'
group by action
order by create_time;
name action create_time 列上,而不是 ip_address。考虑维度优势
action列的值包含:1、2、3、4、5,那么该列的维度就是5。对短小的值加索引
为字符串前缀加索引
length的例子,这里就不举例子了。复合索引的左侧索引
CREATE INDEX indexName ON tableName (column1 DESC, column2 DESC, column3 ASC);

索引加锁
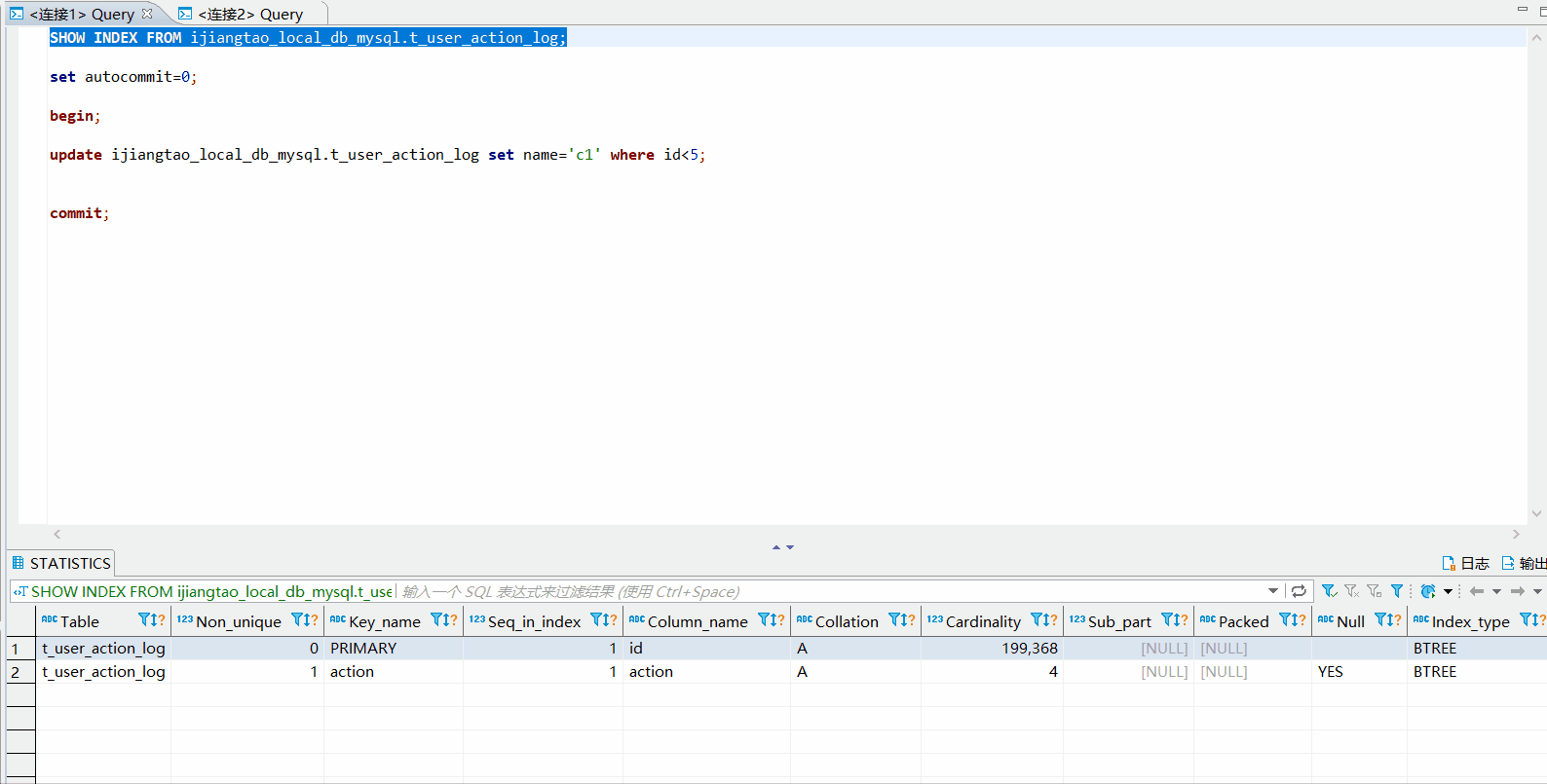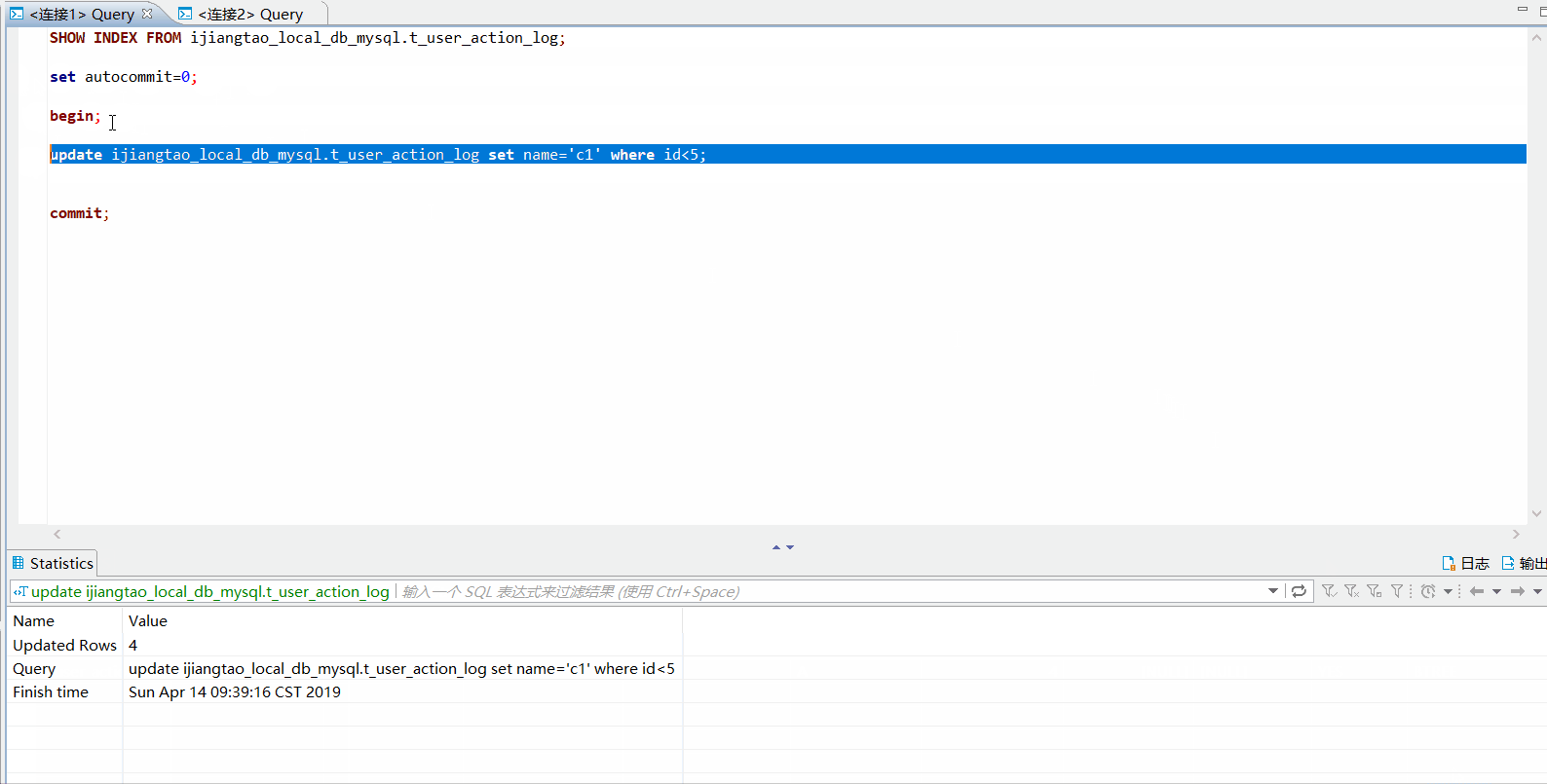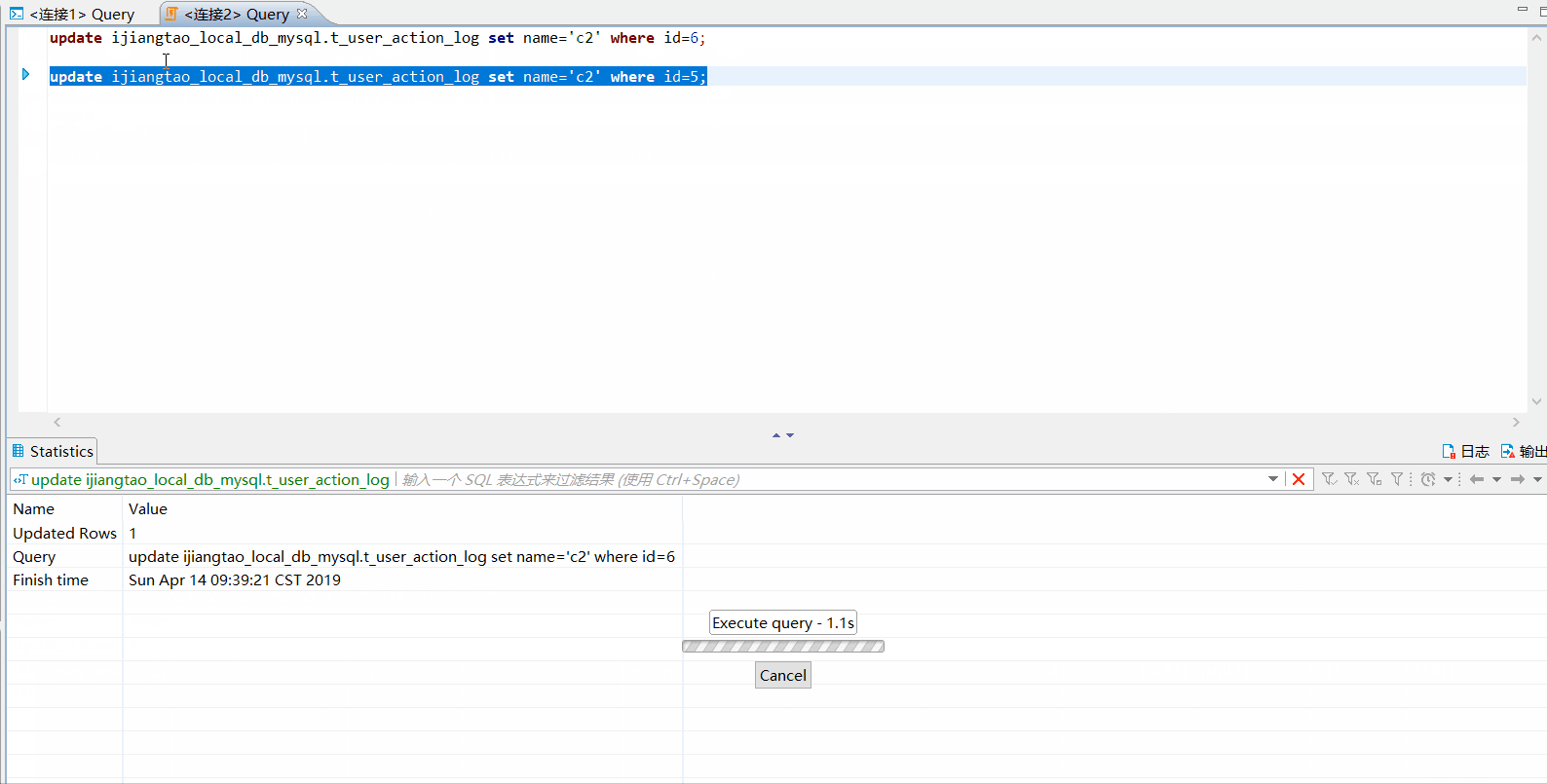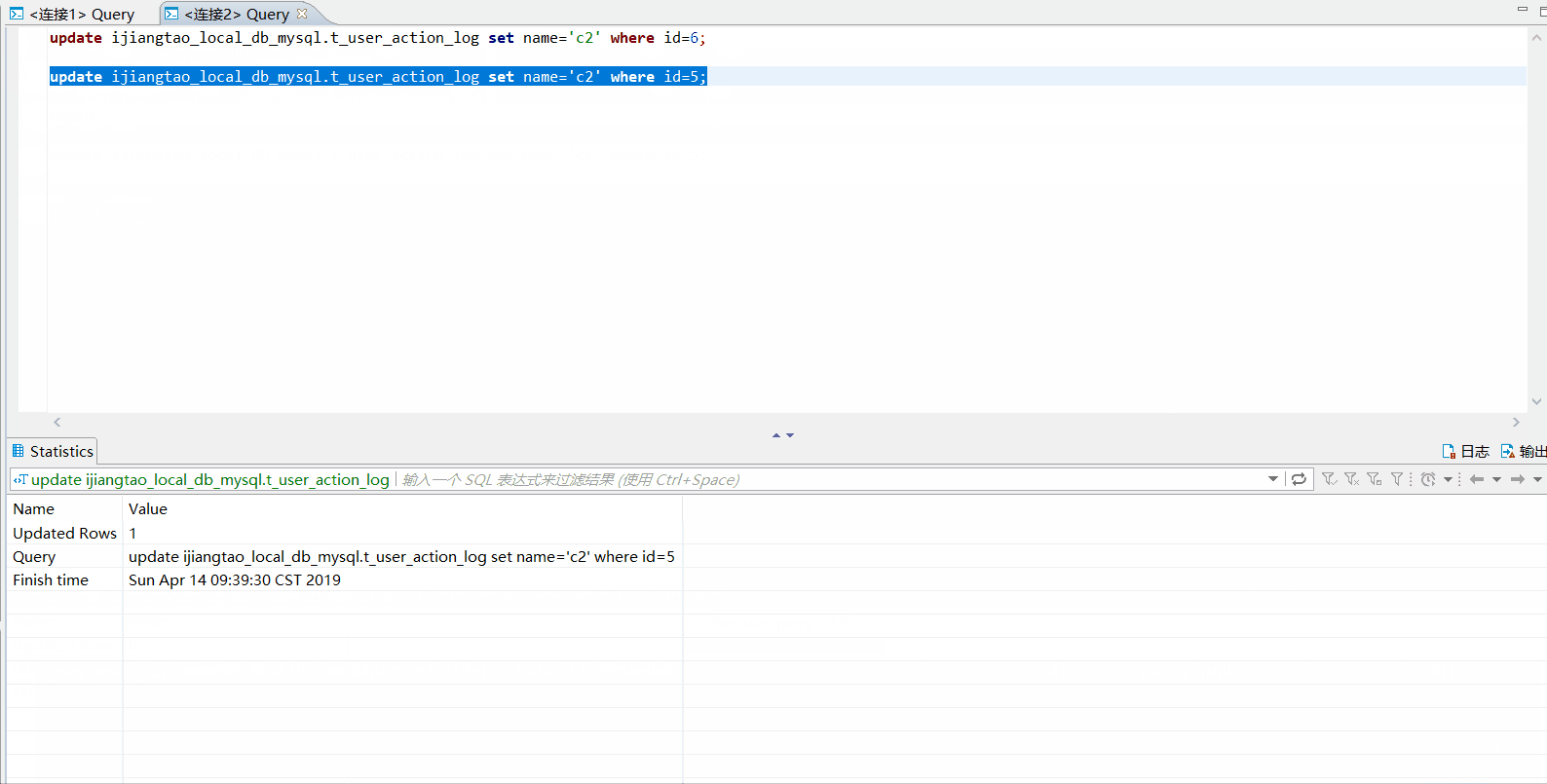
t_user_action_log表目前有一个id为主键,还有一个二级索引action。id值为1 2 3 4所在的行,查询锁会锁住id值为1 2 3 4 5所在的行。update ijiangtao_local_db_mysql.t_user_action_log set name='c1' where id<5;
首先创建数据库连接1,开启事务,并执行update语句
set autocommit=0;
begin;
update ijiangtao_local_db_mysql.t_user_action_log set name='c1' where id<5;
然后开启另外一个连接2,分别执行下面几个update语句
-- 没有被锁
update ijiangtao_local_db_mysql.t_user_action_log set name='c2' where id=6;
-- 被锁
update ijiangtao_local_db_mysql.t_user_action_log set name='c2' where id=5;
id=5的数据行已经被锁定,id=6的数据行可以正常提交。连接1提交事务,连接2的
id=1和id=5的数据行可以update成功了。
-- 在连接1提交事务
commit;
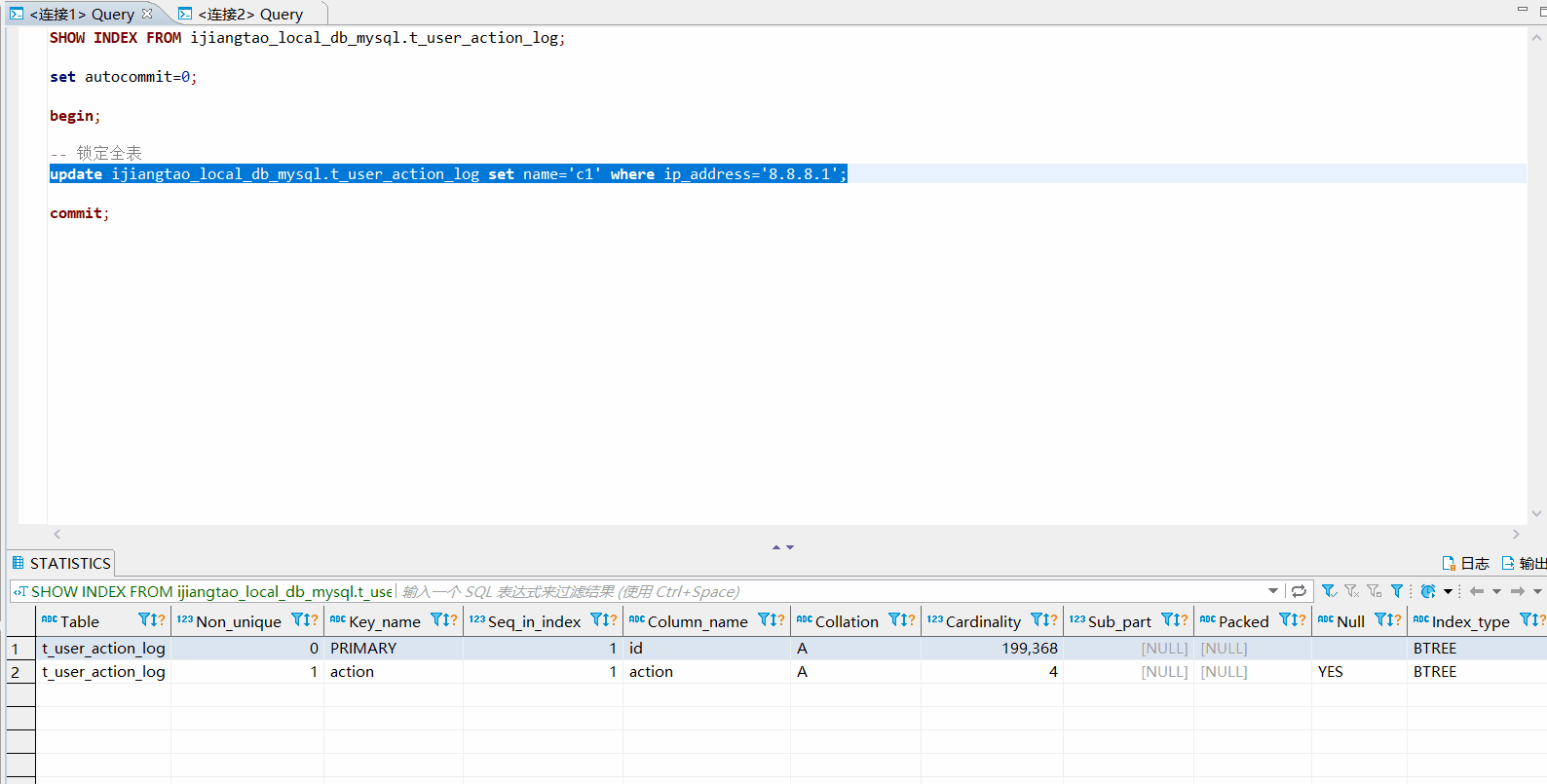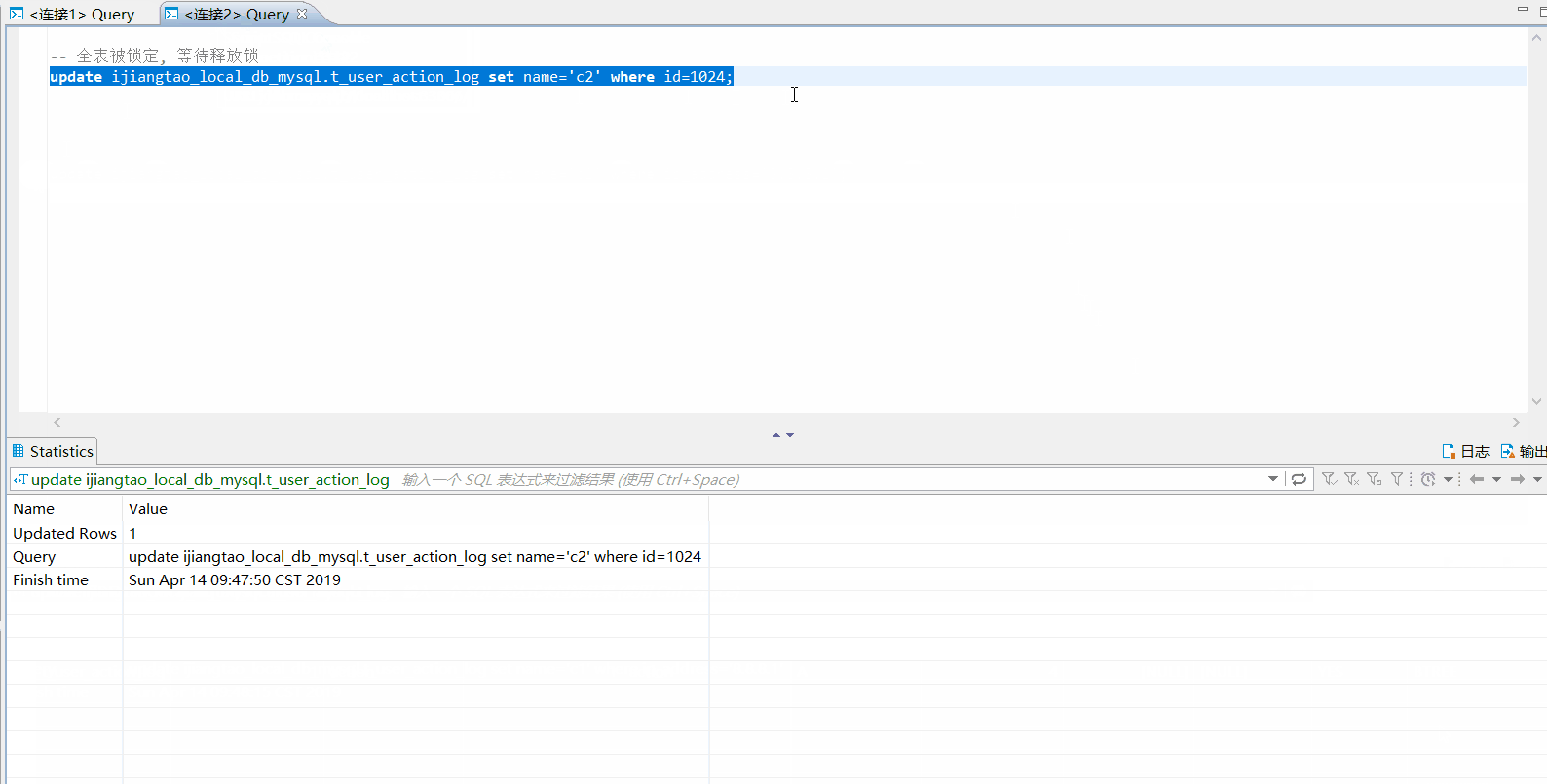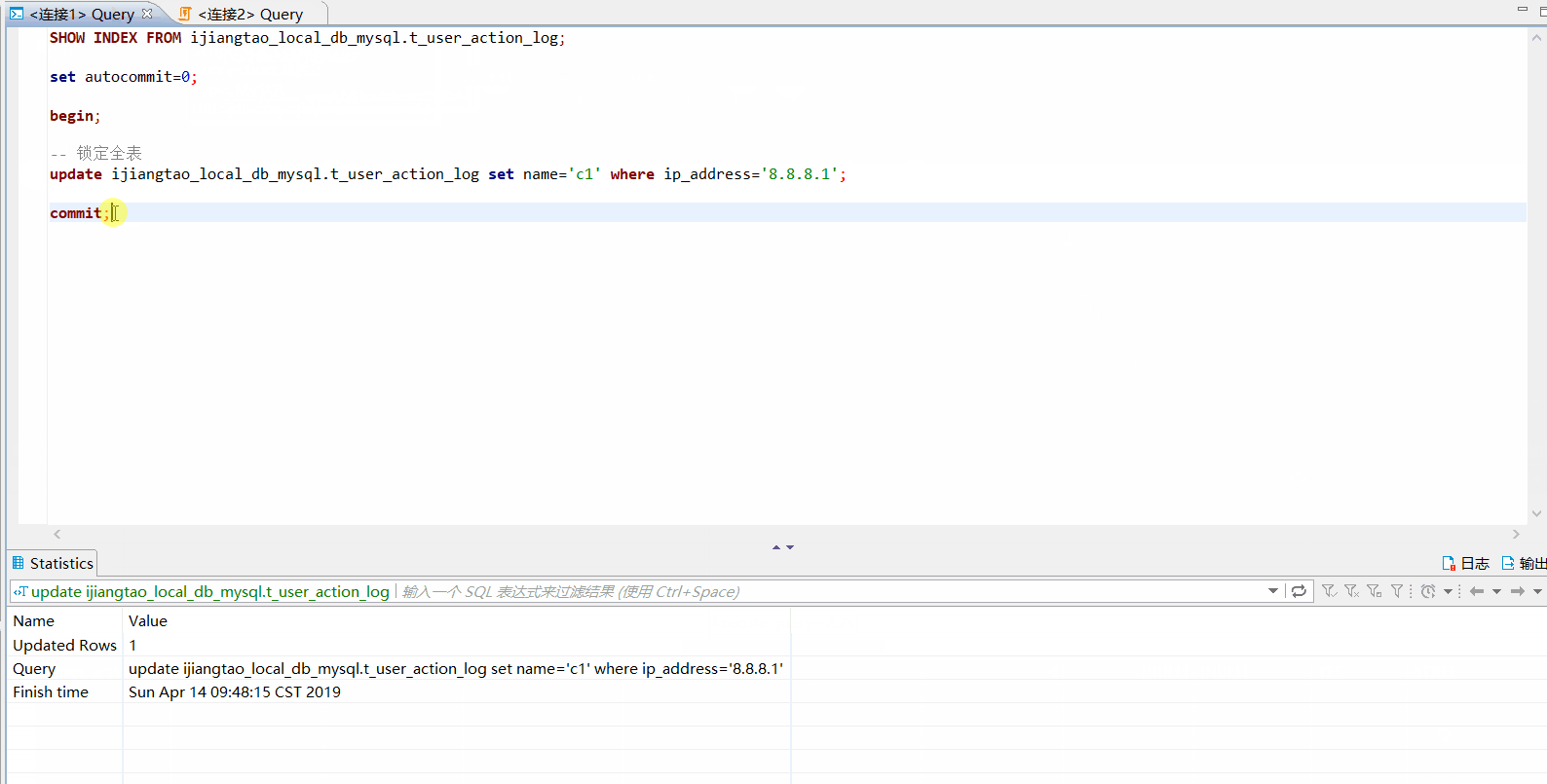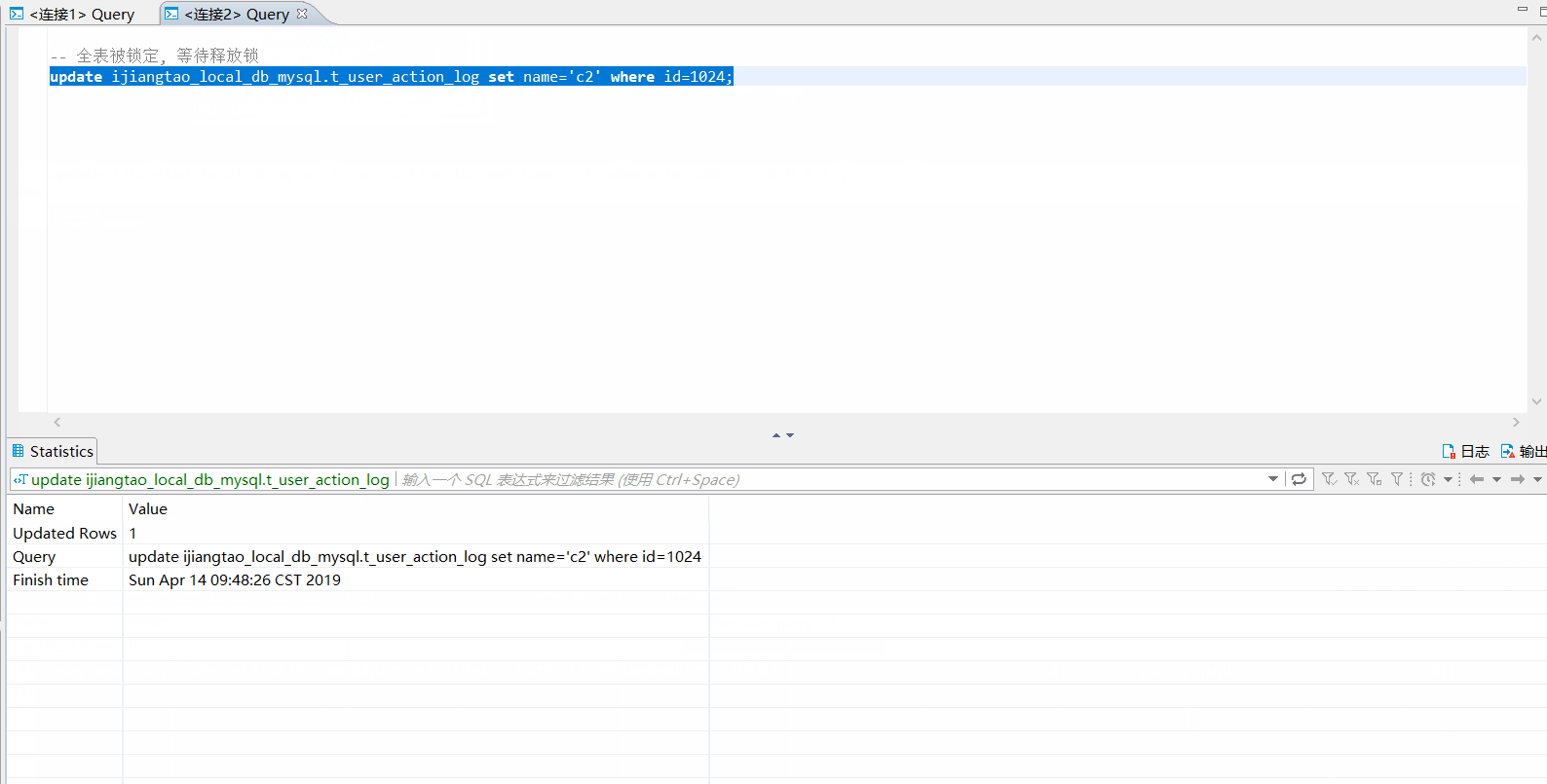
如果不使用索引
ip_address没有索引的话,会锁定全表。commit;之前,连接2对该表的update全部需要等待连接1释放锁。set autocommit=0;
begin;
update ijiangtao_local_db_mysql.t_user_action_log set name='c1' where ip_address='8.8.8.1';
覆盖索引
索引通常比记录要小,覆盖索引查询只需要读索引,而不需要读记录。
索引都按照值的大小进行顺序存储,相比与随机访问记录,需要更少的I/0。
大多数数据引擎能更好的缓存索引,例如MyISAM只缓存索引。
ijiangtao_local_db_mysql表的action列包含索引。使用explain分析下面的查询语句,对于索引覆盖查询(index-covered query),分析结果Extra的值是Using index,表示使用了覆盖索引 :explain select `action` from ijiangtao_local_db_mysql.t_user_action_log;

聚簇索引
AUTO_INCREMENT列作为主键,应该尽量避免使用随机的聚簇主键。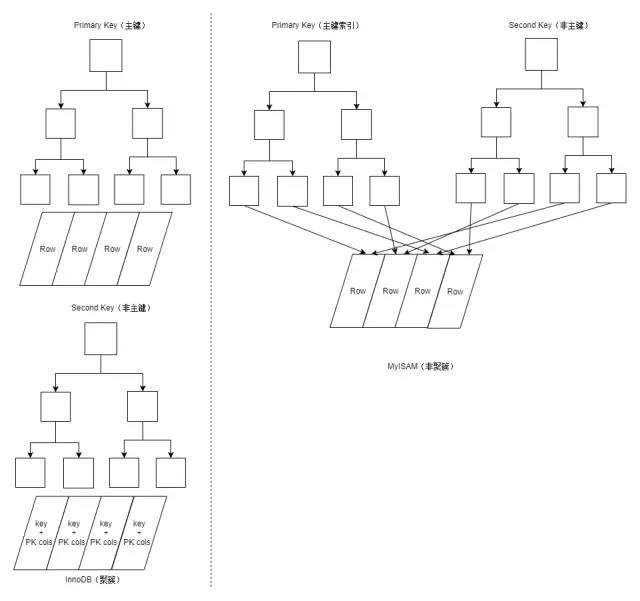
选择合适的索引类型
B树索引
Hash索引
查询优化建议
使用explain分析查询语句
explain命令分析查询语句了,这里再解释一下其中几个有参考价值的字段的含义:select_type
SIMPLE
简单SELECT,不使用UNION或子查询等。PRIMARY
查询中若包含任何复杂的子部分,最外层的select被标记为PRIMARY。UNION
UNION中的第二个或后面的SELECT语句。DEPENDENT UNION
UNION中的第二个或后面的SELECT语句,取决于外面的查询。UNION RESULT
UNION的结果。SUBQUERY
子查询中的第一个SELECT。DEPENDENT SUBQUERY
子查询中的第一个SELECT,取决于外面的查询。DERIVED
派生表的SELECT, FROM子句的子查询。UNCACHEABLE SUBQUERY
一个子查询的结果不能被缓存,必须重新评估外链接的第一行。
type
ALL:
Full Table Scan,MySQL将遍历全表以找到匹配的行。index:
Full Index Scan,index与ALL区别为index类型只遍历索引树。range:
只检索给定范围的行,使用一个索引来选择行。ref:
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。eq_ref:
类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件。const:
当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。
如将主键置于where列表中,MySQL就能将该查询转换为一个常量。NULL:
MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
Key
possible_keys
ref
explain命令是查询优化的第一步 !声明NOT NULL
考虑使用数值类型代替字符串
考虑使用ENUM类型
CREATE TABLE shirts (
name VARCHAR(40),
size ENUM('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),
('polo shirt','small');
SELECT name, size FROM shirts WHERE size = 'medium';
总结
推荐阅读:
【56期】你说你熟悉并发编程,那么你说说Java锁有哪些种类,以及区别
微信扫描二维码,关注我的公众号
朕已阅 