
双手沾泥,大模型应用并不神秘
【引子】感谢图灵出版社英子老师赠书——《大模型应用开发极简入门》,读过之后,正好和自己的大模型系列文章相互印证,于是将读后感汇成此文。

如今,大模型应用已经渗透到各个领域,从自然语言处理到计算机视觉,再到推荐系统。这些复杂而强大的模型,如 GPT-3.5/4、文心一言 和 Claude3,成为科技领域的瑰宝,引领着人工智能的浪潮。然而,对于许多初学者来说,这些大模型应用似乎充满神秘色彩,仿佛只有少数专家才能参与其中。事实上,深入了解这些模型的原理和应用,并付诸实践,并不遥不可及。
类比一下, 对于程序员而言,如果学习前端开发,应该怎么做?可能,我们要先学习HTML/Javascript/CSS 的基本原理,然后动手跟着教程写一些例子,最后在实际的前端应用中去不断实践,形成循环迭代,进而真正掌握这门技术。面向大模型的应用开发也是一样的,理解大模型的基本原理,实际动手实践,在具体应用中对大模型进行微调,同样是一个循环迭代的过程。
双手沾泥,探索大模型应用的世界,将为我们揭示更多的乐趣。
1. 大模型的基本原理
谈到大模型一般会从AI 说起,什么是程序员视角中的AI呢?可以参见《 老码农的AI漫谈 》和《 老码农眼中的简明AI 》。
人工智能在一定程度上是可以通过自然语言体现的,可以追溯到图灵测试。而通过大模型通常是指大型语言模型,确切地说,大概应该叫大型基础模型,是参数规模庞大、拥有深层结构的神经网络,能够处理复杂的任务。关于大模型的更多理解可以参考《老码农眼中的大模型(LLM)》。GPT-3/4、Claude3等类似的大模型与AI、机器学习和深度学习的关系如下图所示:

大模型的以 GPT-3 为例,这是一个由数十亿个参数组成的深度神经网络,通过无监督学习在大规模文本数据上进行预训练,从而具备了惊人的语言生成能力。这主要归功于Transformer架构,它能够处理长文本序列并记住上下文。Transformer的核心支柱是自注意力机制,即关注一句话中最相关的词,交叉注意力和自注意力是其中两个广泛使用的模块。其中,自注意力机制的示意图如下:
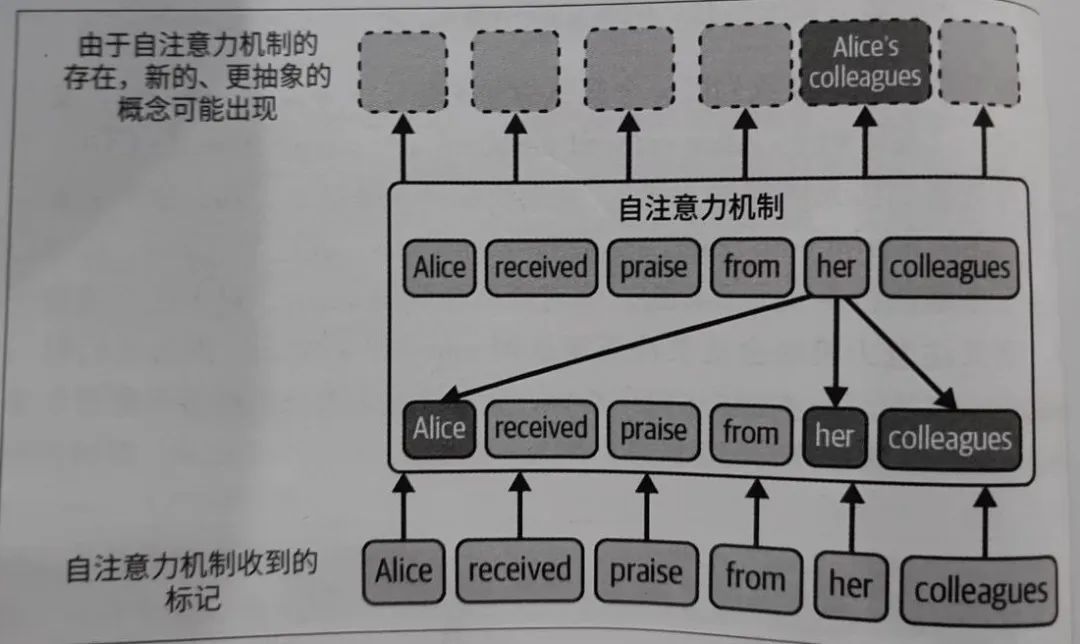
GPT-X等大模型充分利用了Transformer架构的潜力,而chatGPT可以看作融入了对话管理的大模型应用,背后的模型应该是gpt-3.5-turbo,它根据制定的输入提示词逐个预测下一个词,进而生成问答。另外,GPT-4同时支持插件功能。
OpenAI 提供的很多模型都会不断更新,但都是涉及到一些基本概念,例如提示词、token和嵌入。其中,提示词可以参考《 解读提示工程(Prompt Engineering) 》,进一步,还可以参考《Agent 应用于提示工程》;token 可以参考《 解读大模型(LLM)的token 》,同时注意token和tokenization的区别;嵌入可以参考《 《深入浅出Embedding》随笔 》。
2.动手体验
要想真正掌握大模型应用,光有理论知识是不够的。我们必须深入实践,通过亲手操作、不断尝试,才能真正理解其内在的逻辑和规律。这就像农民种地一样,只有双手沾泥,亲身感受土地的温暖和湿润,才能种出丰收的庄稼。同样,只有我们亲手搭建模型、调整参数、处理数据,才能真正掌握大模型应用的精髓。
对于大模型在各种任务上的表现, 可以在其厂商提供的控制台直接体验。例如, OpenAI Playground 就是一个很好的体验途径。
对程序员而言, 新技术的学习一般都会始于“永远的hello world”,大模型应用也不例外,只不过是基于Python这种编程语言而已,关于Python 的一些基础用法可以参考《 全栈Python 编程必备 》。
安装环境的命令 pip install openai ,5行代码实现hello world:
import openai
resp = openai.ChatCompletion.create{
model="gpt-3.5-turbo",
message =[{"role"= "user","content"="Hello World!"}], )
print(resp["choices"][0]["message"]["content"]
当然,这里默认设置了OPEN_API_KEY的环境变量。
GPT-3.5-turbo可能是最便宜且功能最多的模型,可以作为大模型应用开发的初始选择。
在广泛联系之前,要考虑一下成本和数据隐私。例如,OpenAI 是以每千个token定价的,且每个模型的定价不同。gpt-4模型的窗口大小是gpt-3.5-turbo的两倍,但成本会更高。另外,OpenAI会保留30天的用户输入,注意敏感信息的保护,管理好密钥。
3.尝试应用
开发基于大模型的应用,核心是将大模型与其提供的API结合起来,需要注意的是,应用要与模型解耦,绑定会带来紧耦合,不利于系统扩展。一个典型使用OpenAI API的web程序如下图所示:
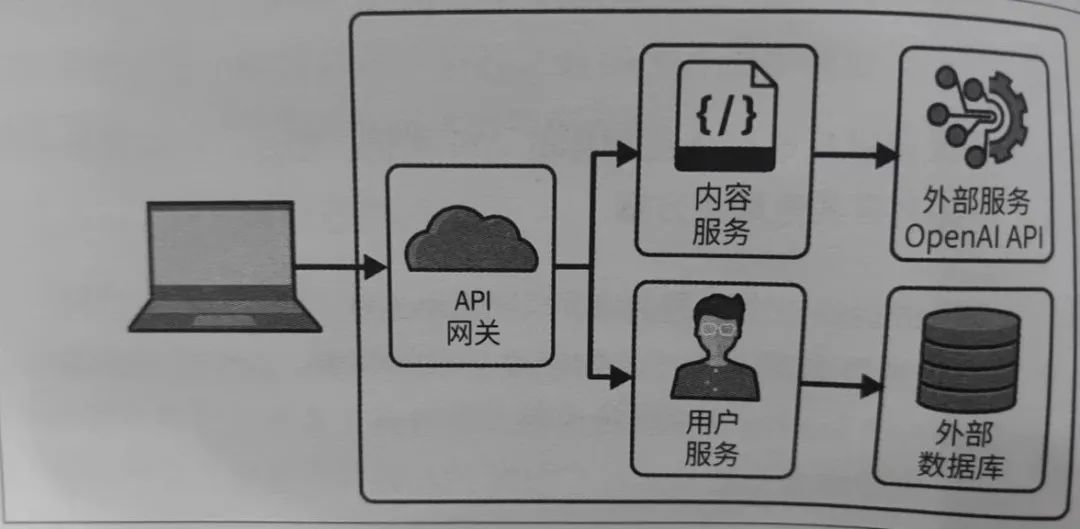
需要注意的是,大模型应用无法避免提示词注入,提示词的这一功能特性带来了安全风险。一般的应对策略包括:
-
使用特定规则控制用户输入
-
控制输入的长度
-
控制输出
-
监控与审计
-
意图分析
提示工程专注于以最佳实践的方式来构建LLM的最佳输入,从而尽可能以程序化方式生成目标结果。
由于大模型将数字视为token,所以缺乏真正的数学逻辑和类似的推理能力。可以在提示词末尾添加“让我们逐步思考”这样的话,这种技术被称为“零样本思维链”。思维链是指使用提示词鼓励模型逐步思考的技术,one-shot 和 few-shot也是常见技术手段,总之,提示工程是一个反复试错的迭代过程。
另外,面向特定任务, 我们还需要微调大模型,示意图如下:
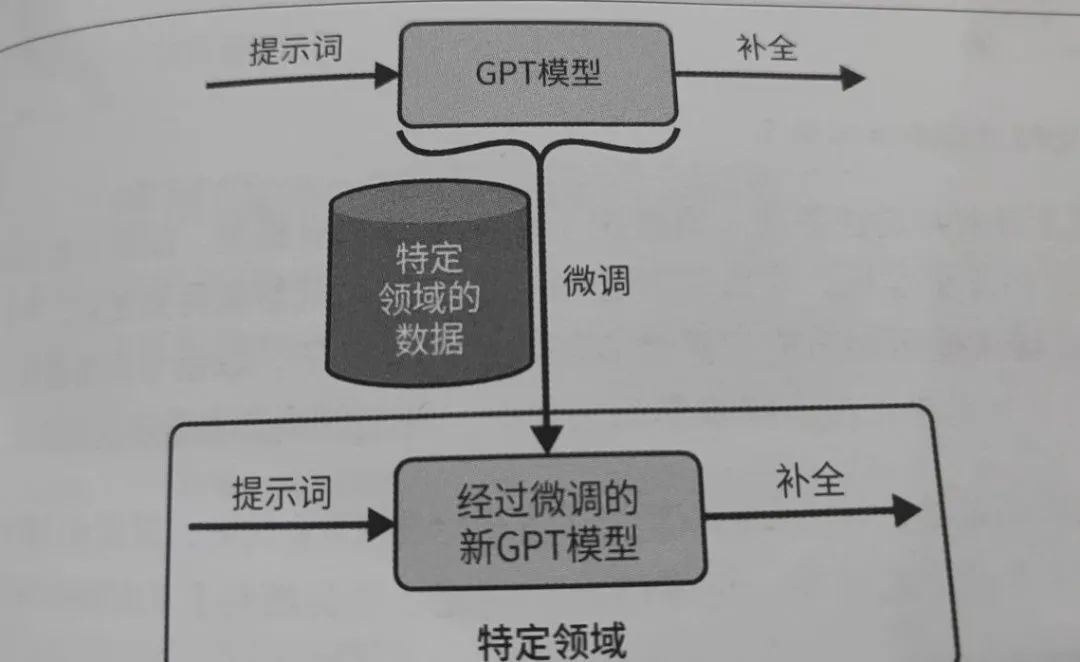
大多数时候,预训练的大模型需要在特定任务上进行微调,以适应具体应用场景。微调过程包括调整模型的超参数、选择合适的数据增强方法,以及解决过拟合等问题。微调要使用基础模型,而不能使用像InstructGPT系列中的模型。而且,微调通常也需要大量的数据,成本也不低。
通过深入研究微调的技术细节,我们能够更好地将大模型应用到实际问题中,提高模型的性能和泛化能力,更多有关微调的理解和思考可以参考《解读大模型的微调》。
《大模型应用开发极简入门》一书中给了一些不错的练手项目,都可以动手尝试。
4. 大模型应用框架的使用
站在巨人的肩膀上, 从零构建一个成熟且复杂的大模型应用并不是一件轻松的事。和web应用的开发类似, 是类似Spring 这样的应用框架, 给我们带来了极大的便利。对大模型应用而言也是如此,langchain就是一个当前看来还不错的应用框架。
关于Langchain的进一步了解,可以参考《 解读LangChain 》。Agent 及相关工具是LangChain框架提供的关键功能之一,让大模型能够执行各种操作并与各种功能集成,从而解决复杂的问题。在LangChain中使用Agent 的示意如下:
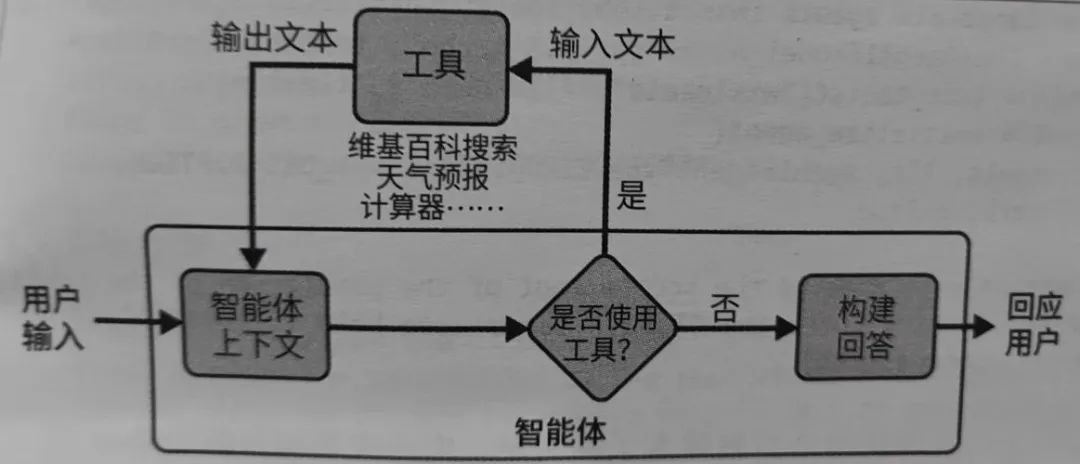
关于Agent 的更多理解,可以参考《 基于大模型(LLM)的Agent 应用开发 》。
document_loaders 是Langchain中的一个重要模块,通过这个模块,可以快速将文本数据从不同的数据源加载到应用程序中,然后,对文本实现向量化,例如使用 OpenAIEmbeddings 模块,从而使搜索更加容易。这是RAG的典型应用模式,关于RAG的更多理解可以参考《 大模型系列——解读RAG 》。LangChain 以向量数据库为核心,有多种向量数据库可以选择,关于向量数据库可以参考《 解读向量数据库 》。
另外,GPT-4的插件功能重新定义了我们与大模型的交互方式,我们可以自行开发插件,进而提供更为广泛的功能。
5. 小结
当然,通过一本书实现大模型应用开发入门是可能的, 但和传统软件开发一样,如果要掌握大模型应用的开发技能, 实践仍然是不二的法门。
-
通过阅读相关文献、参与在线课程,将有助于建立对大模型原理的深刻理解,就论文而言,《系统学习大模型的20篇论文》或许是个不错的起点;
-
通过与社区和团队共同探讨,将为我们提供更多的机会和启示;
-
通过亲自编写代码、搭建模型,我们能够深刻理解模型训练和推理的过程,可以与《如何构建基于大模型的App》相互印证。
双手沾泥,大模型应用并不神秘。选择一个熟悉的任务,让我们开始构建相应的大模型应用吧。
【关联阅读】