
避免成为调包侠,从数学角度再看深度学习
知其然知其所以然。想要深耕深度学习,背后的数学原理还需要掌握。这就有一本值得推荐的新书。


第一章:引言部分,主要介绍了该书定义的一些符号表示、理论基础、是否需要新的理论解决还未解决的问题;
第二章:大型神经网络的泛化能力,主要包括核(Kernel)相关问题、基于范数的边界和边际理论、优化和隐式正则化、经典理论的局限性;
第三章:深度在神经网络表达中的作用,主要包括径向函数逼近、深度 ReLU 网络、表达性的可替代概念;
第四章:深度神经网络克服了维数的诅咒,主要包括流形假设、随机抽样、PDE 假设;
第五章:深度神经网络的优化,主要包括损失分析、随机梯度下降的惰性训练和可证明的收敛;
第六章:特殊架构的影响,主要包括卷积神经网络、残差神经网络、 Framelets 和 U-Nets 、批归一化、稀疏神经网络与剪枝、递归神经网络;
第七章:深度神经网络学习的特征描述,主要包括不变性与散射变换、分层的稀疏表示;
第八章:自然科学的有效性,主要包括深度神经网络遇到逆问题、基于 PDF 模型。

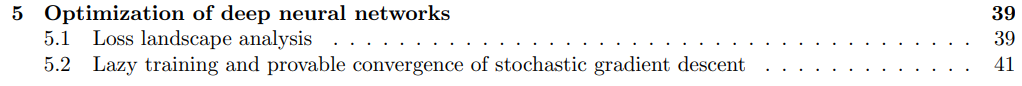




评论