
陈怡然教授论文获2024 IEEE优秀论文奖!STN-iCNN:端到端的人脸解析框架

来源:新智元报道
来源:新智元报道
【导读】陈怡然教授论文拿下2024 IEEE CIS TETCI优秀论文奖。
陈怡然教授论文获奖!
这篇有关人脸识别/分析的论文拿下了2024 IEEE CIS TETCI优秀论文奖。
陈怡然教授在微博上表示,「四年前发表的文章居然得了2024年的杰出论文奖。」
论文题目:通过互联卷积神经网络进行端对端的人脸解析

人脸解析是一项重要的计算机视觉任务,需要对人脸部位(如眼睛、鼻子、嘴巴等)进行精确的像素分割,为进一步的人脸分析、修改和其他应用提供基础。
互联卷积神经网络(iCNN)被证明是一种有效的人脸解析模型。然而,最初的iCNN是在两个阶段分别训练的,这就限制了它的性能。
为了解决这个问题,本篇论文引入了一个简单的端到端人脸解析框架——STN辅助的iCNN(即:STN-iCNN),通过在两个孤立阶段之间添加空间变换器网络(STN)来扩展iCNN。
STN-iCNN利用STN为原始的两阶段iCNN管道提供可训练的连接,使端到端的联合训练成为可能。
此外,作为副产品,STN还能提供比原始裁剪器更精确的裁剪部分。
由于这两个优势,研究人员的方法显著提高了原始模型的精度。研究人员的模型在标准人脸解析数据集Helen数据集上取得了具有竞争力的性能。
它还在CelebAMask-HQ数据集上取得了优异的性能,证明了其良好的泛化能力。
STN-iCNN
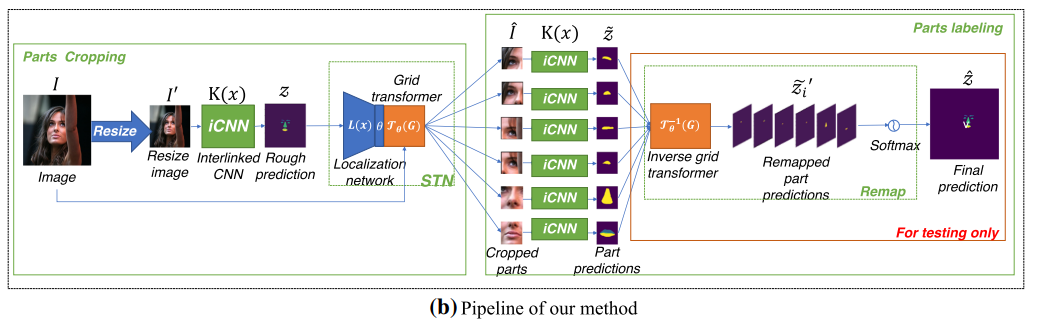
下面两张图片比较了STN-iCNN和传统的基线法的对比。
在图a中,我们可以看到基线法分为两步。
第一步是检测和裁剪人脸部分,第二步是分别标注裁剪的部分。由于在此过程中使用的裁剪方法不可区分,因此这两个阶段无法进行联合训练。
如开头所说,这限制了系统的性能。
研究人员提出的方法通过在基线方法的两个步骤之间添加空间变换器网络(STN),就可解决了这一问题。STN用一个可微分的空间变换器取代了原来的裁剪器,使模型能够端到端地训练。
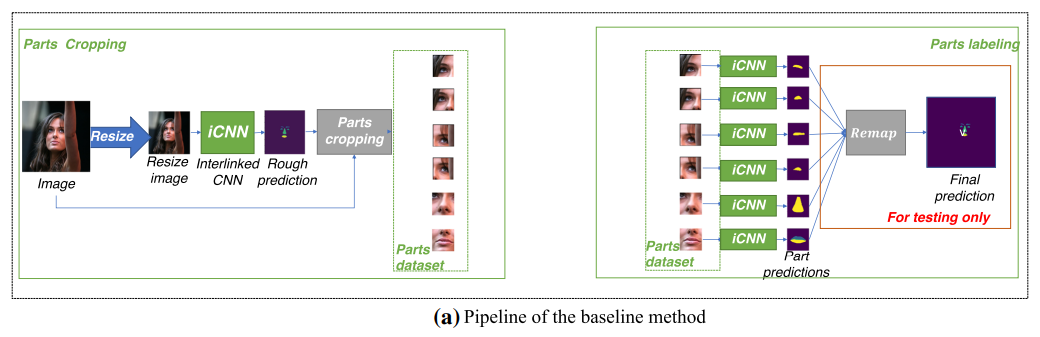
而像图b中的STN-iCNN方法,对于每幅输入的图像,首先会调整图像大小并传递给iCNN模型,由iCNN模型进行粗分割。
然后,将粗分割版本发送给STN,STN的定位网络预测变换器参数矩阵θ。然后,以θ为参数,网格变换器对原始图像中的相应部分进行裁剪。
最后,逆网格变换器将所有部分预测结果重映射为最终的整体预测结果。
下图是iCNN的结构示意图。
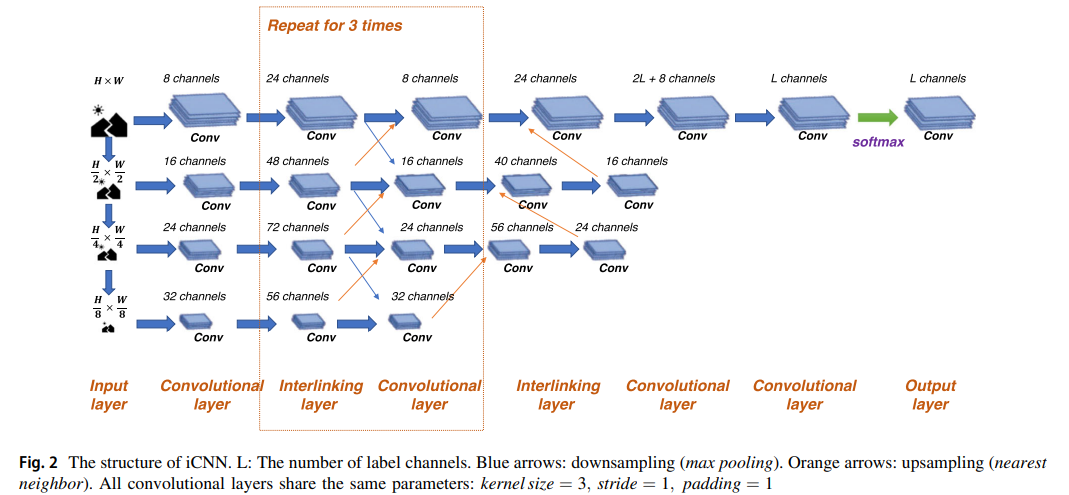
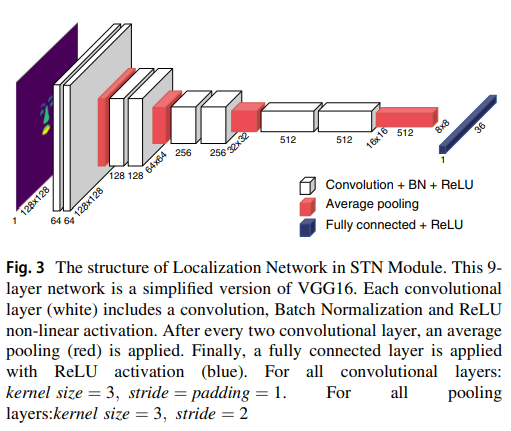
图3则是STN模块中的定位网络结构。
这个9层网络是VGG16的简化版本。每个卷积层(白色)包括卷积、批量归一化和ReLU非线性激活。
在每两个卷积层之后,应用平均池化(红色)。
最后,应用ReLU激活的全连接层(蓝色)。
研究人员将整个系统的训练过程分为预训练和端到端训练。
首先,为了达到更好的效果,先对系统进行了预训练。其中,有两个模块需要进行预训练,一个是用于粗分割的iCNN K,另一个是用于部件定位的定位网络L。
如下图所示,K的输入为调整后的图像I0,输出为粗略预测值z。
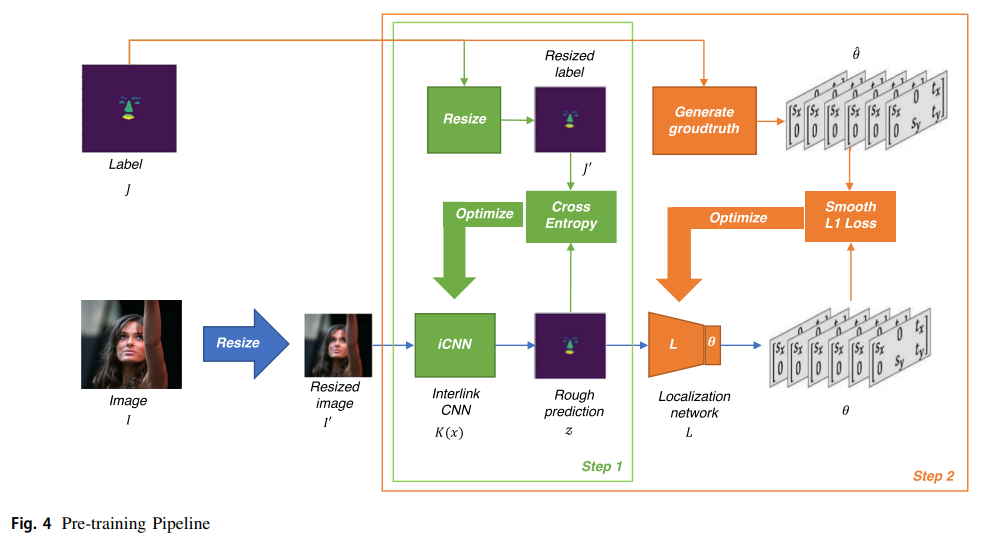
其优化目标是z和调整后的标签J'之间的交叉熵损失LR。

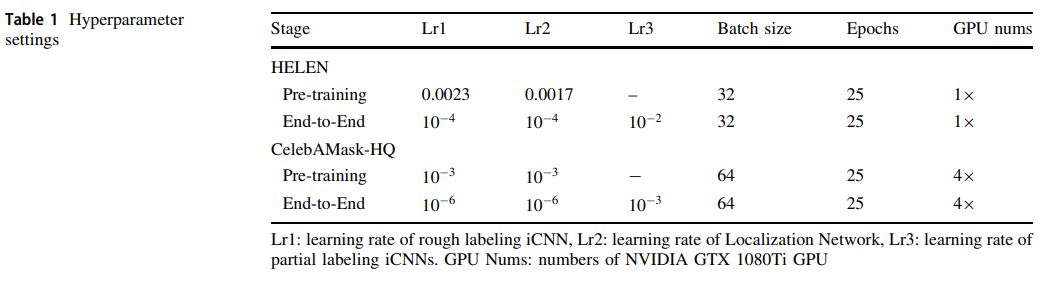
表1显示了详细的超参数。
研究人员分两个阶段对提出的模型进行训练:预训练和端到端训练。其中,在端到端训练之前加载了前一阶段获得的预训练参数。
对于HELEN数据集,训练和推理在单个英伟达GTX1080Ti GPU上执行,而对于CelebMaskA数据集,这些操作在4个英伟达GTX1080Ti GPU上执行,每个GPU的批量大小为16。
所提出的模型具有良好的效率。在推理效率方面,基线模型每张脸的运行时间为86毫秒,而提出的模型每张脸的运行时间为80毫秒。
对于HELEN的训练效率,预训练阶段需要0.5h,端到端阶段需要2.2h;对于CelebMaskA的训练效率,预训练阶段和端到端阶段分别需要1.6h和10.2h。
在CelebMaskA上的混合训练策略:在HELEN上训练,在CelebMaskAD上微调由于CelebMaskA的数据量较大,直接训练需要更多的计算资源和更长的训练时间。
在实践中,研究人员发现使用CelebMaskA中的2000张图像对已经在Helen数据集上训练过的模型进行微调,两者的性能相近。
这种方法在单个GPU上仅需2.1小时,节省了大量的训练时间。这证明了研究人员模型的通用性。
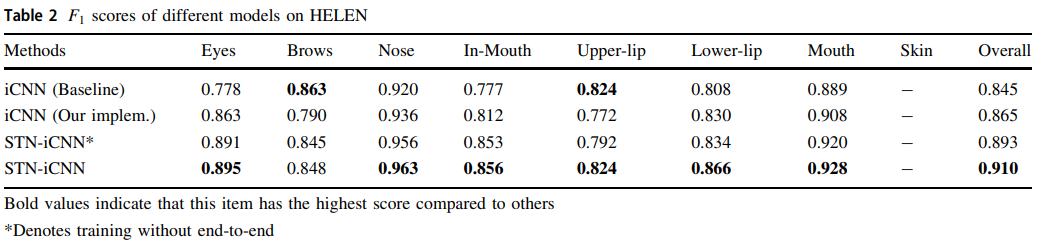
研究人员以之前一些研究者的结果为基线,将其与重新实现的iCNN和所提出的STN-iCNN在HELEN数据集上的结果进行了比较。
比较结果如表2所示,其中STNiCNN*表示STN-iCNN在端到端训练前的结果。
我们能看到,即使在端到端训练之前,模型的结果也有明显改善。
这是因为STN中的定位网络具有深度CNN层,因此可以从粗糙掩膜中学习语义部分的上下文关系。在粗略掩码不完整的情况下,仍然可以预测准确的变换矩阵。
因此,STN能够比原始裁剪器更精确地裁剪,从而提高了整体性能。
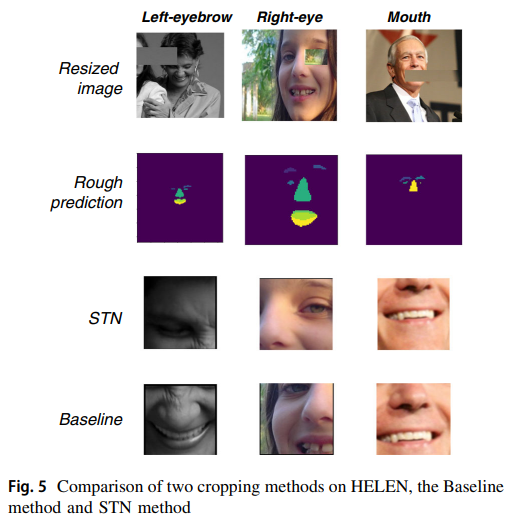
如图5所示,研究人员在HELEN数据集上对两种不同的裁剪方法进行了对比实验。在该实验中,研究人员选取了一些图像,并随机地将其面部部分(如左眉、右眼、嘴等)与背景信息覆盖在一起。然后研究人员将图像发送给粗略标注模型,得到不完整的粗略分割结果,见图5中的第2行。在粗略结果的基础上,研究人员使用基线方法和STN方法对未裁剪图像进行裁剪,并比较它们的裁剪结果。实验结果如图5最后两行所示。结果表明,STN方法即使在粗糙掩膜部分缺失的情况下也能正常工作。
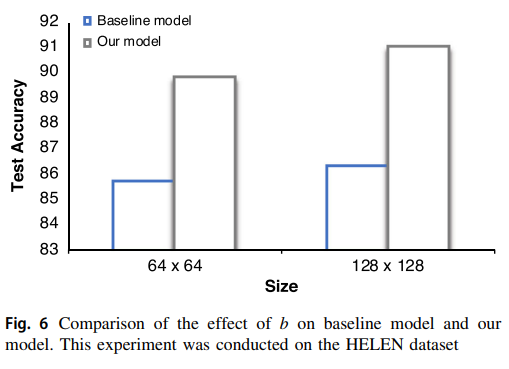
模型K的基线输入大小为64×64,考虑到眼睛和眉毛特征较小,研究人员的模型将输入大小改为128×128。
这一改变对基线方法的影响有限,但对研究人员的方法有明显改善,如图6所示。
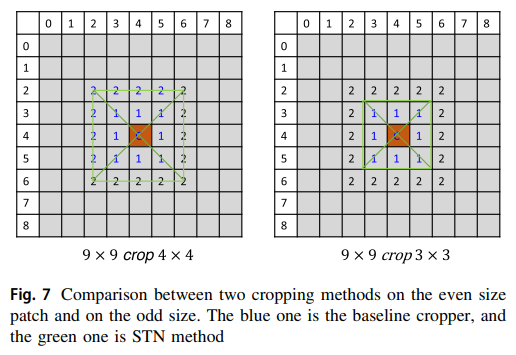
裁剪补丁的大小应该是奇数而不是偶数。这是为了保证,在网格采样过程中网格坐标为整数,从而使网格变换器等于基线方法在裁剪操作中的裁剪器。
如图7所示,可以看出当无法找到整数网格时,STN进行双线性插值,而基线裁剪器进行一像素偏移,从而导致结果不相等。
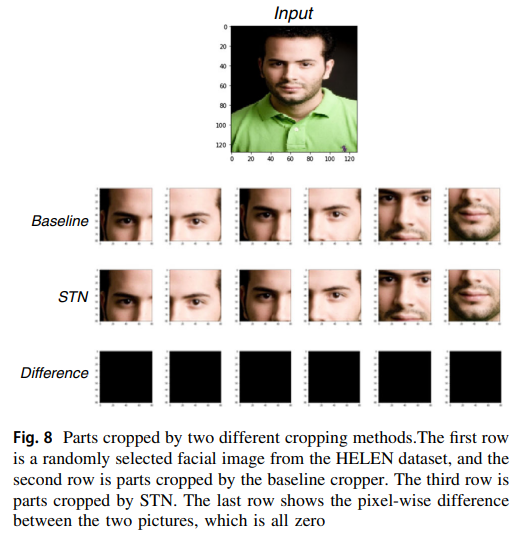
对于HELEN数据集,研究人员设置H ¼ W ¼ 81,对于CelebMaskA数据集,研究人员设置H ¼ W ¼ 127。两种裁剪方法在HELEN数据集上的比较结果如图8所示。
在选择了合适的超参数后,研究人员完成了本文提出的STN-iCNN的端到端训练,并在HELEN数据集上将其测试结果与最先进方法进行了比较。
从表3可以看出,本文提出的STN-iCNN大大提高了原始iCNN模型的性能。
值得一提的是,由于研究人员的模型无法处理毛发,也无法确定毛发对模型总体得分的影响,因此研究人员没有将其与Lin等人(2019)的结果进行比较。
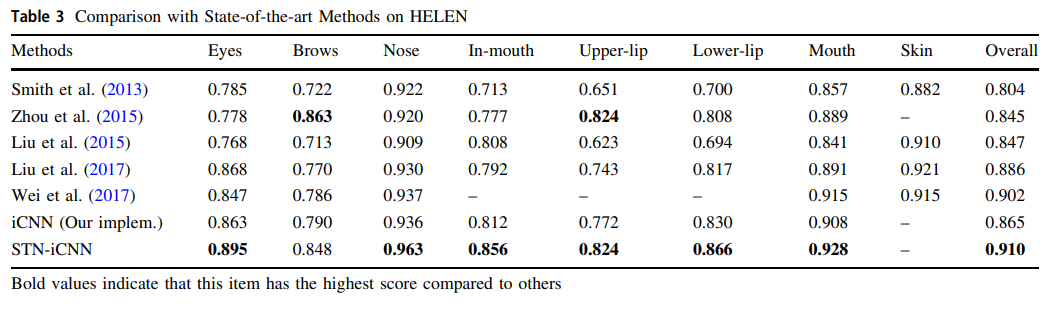
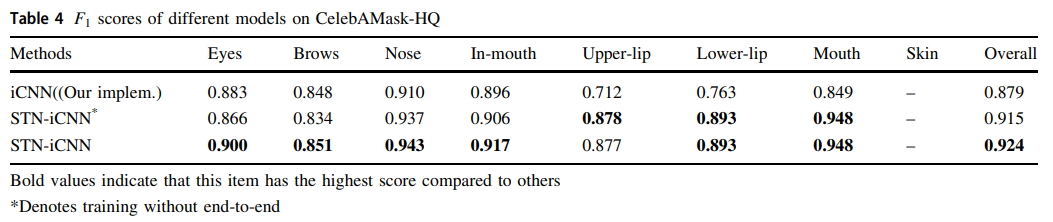
表4显示了基线模型和研究人员提出的模型在F1得分上的比较。
在CelebAMask-HQ上的结果再次证明了所提方法和端到端训练的有效性,表明研究人员的模型具有一定的泛化能力。
更多论文内容尽在参考链接中。
参考资料:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7947053/pdf/11571_2020_Article_9615.pdf


评论