
ECCV2022|何恺明团队开源ViTDet:只用普通ViT,不做分层设计也能搞定目标检测
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
做目标检测就一定需要 FPN 吗?来自 Facebook AI Research 的 Yanghao Li、何恺明等研究者在 arXiv 上上传了一篇论文,证明了将普通的、非分层的视觉 Transformer 作为主干网络进行目标检测的可行性。
研究概览

方法细节
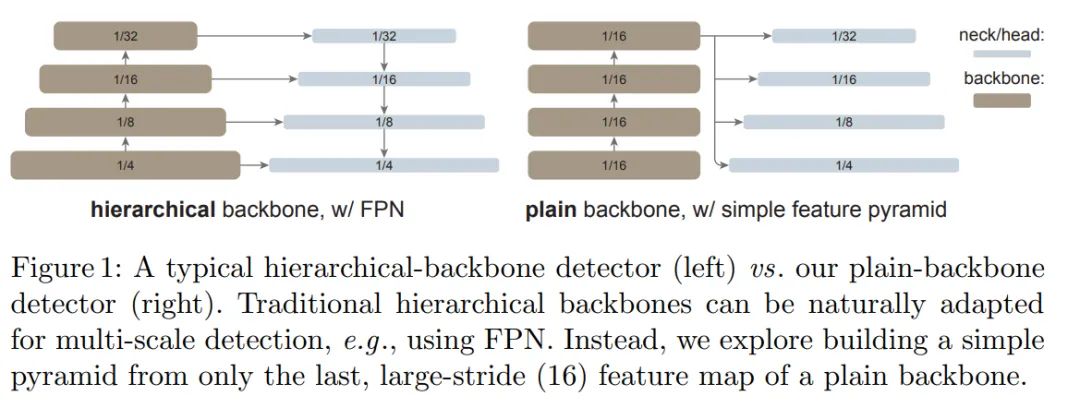
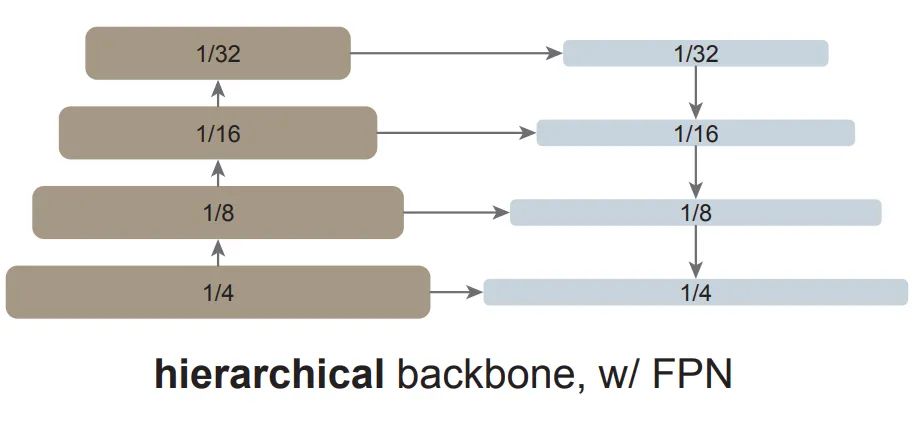
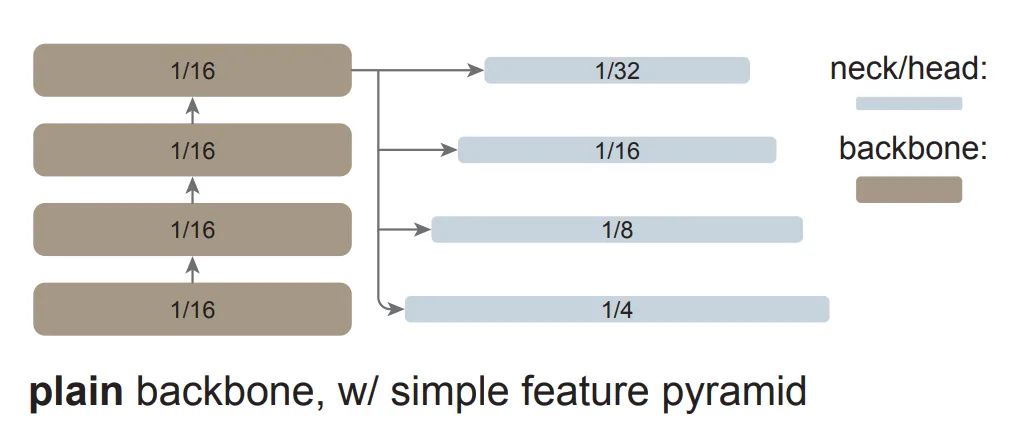
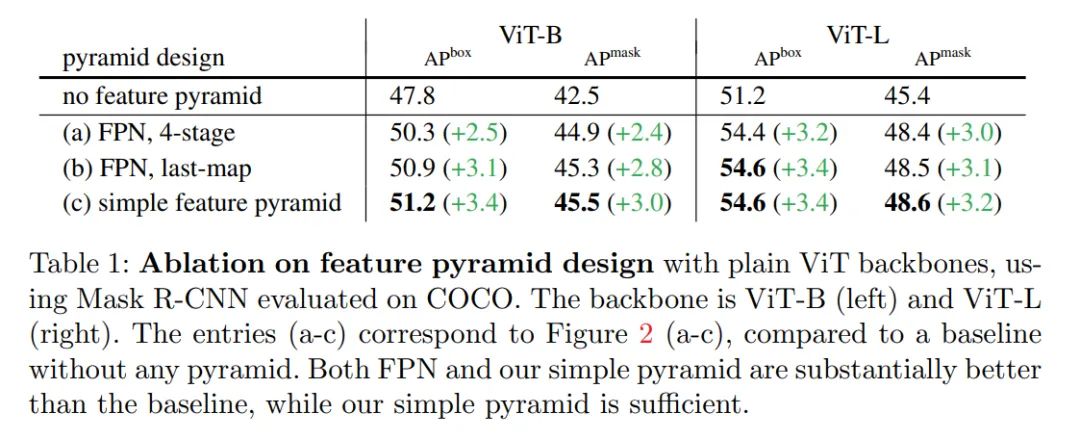
简单的特征金字塔
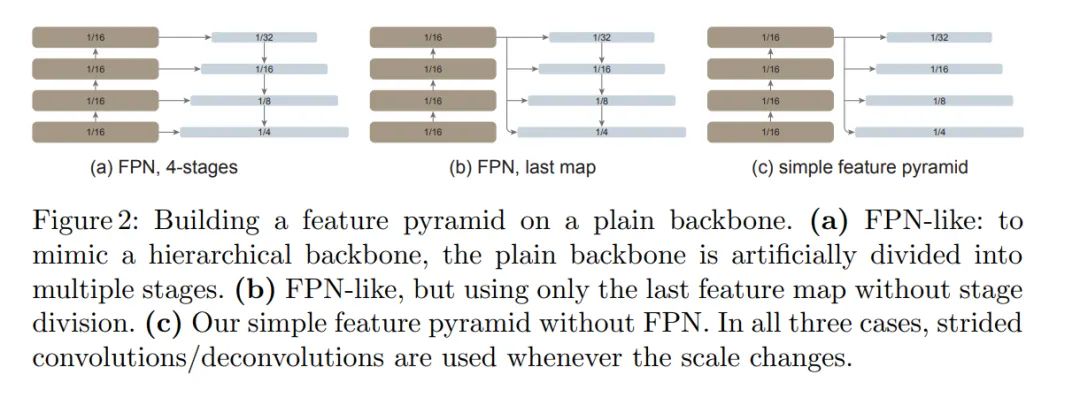
主干网络调整
全局传播。该策略在每个子集的最后一个块中执行全局自注意力。由于全局块的数量很少,内存和计算成本是可行的。这类似于(Li et al., 2021 )中与 FPN 联合使用的混合窗口注意力。
卷积传播。该策略在每个子集之后添加一个额外的卷积块来作为替代。卷积块是一个残差块,由一个或多个卷积和一个 identity shortcut 组成。该块中的最后一层被初始化为零,因此该块的初始状态是一个 identity。将块初始化为 identity 使得该研究能够将其插入到预训练主干网络中的任何位置,而不会破坏主干网络的初始状态。
实验结果
消融研究
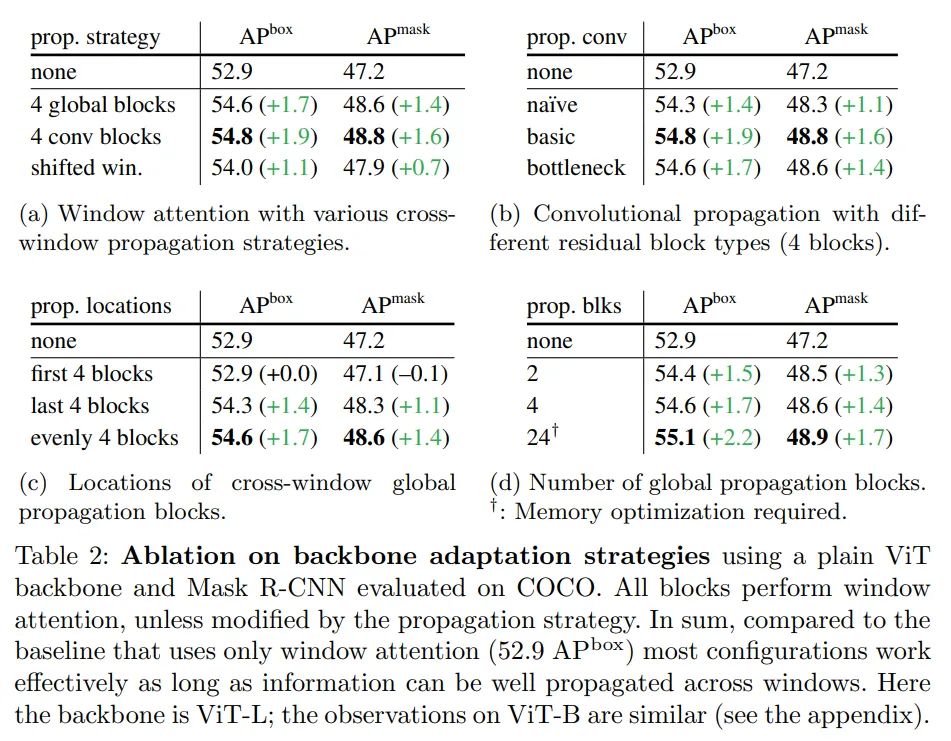
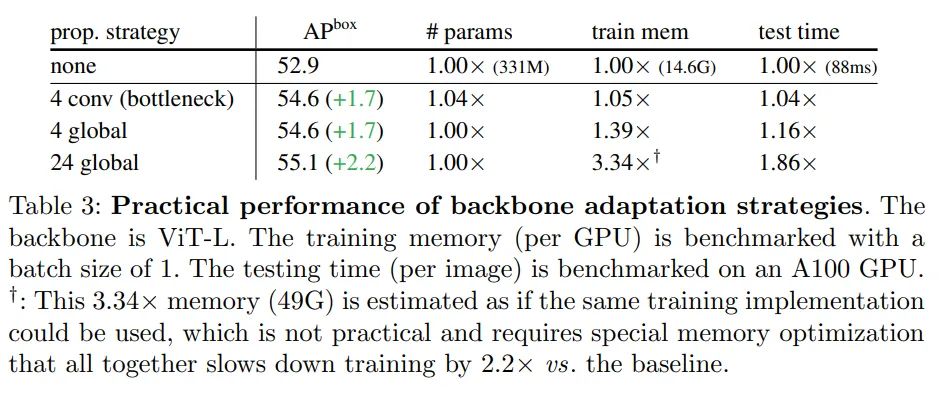
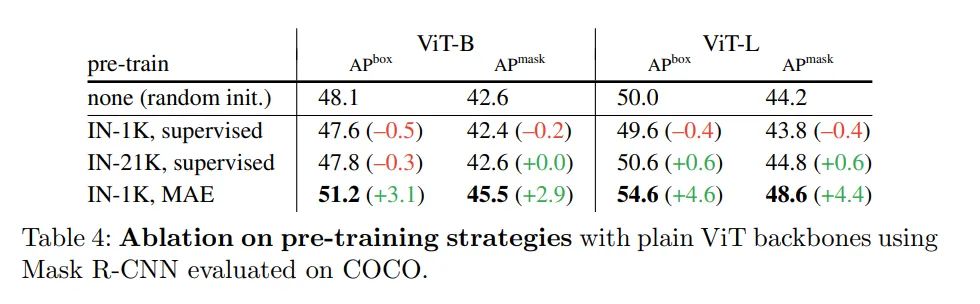
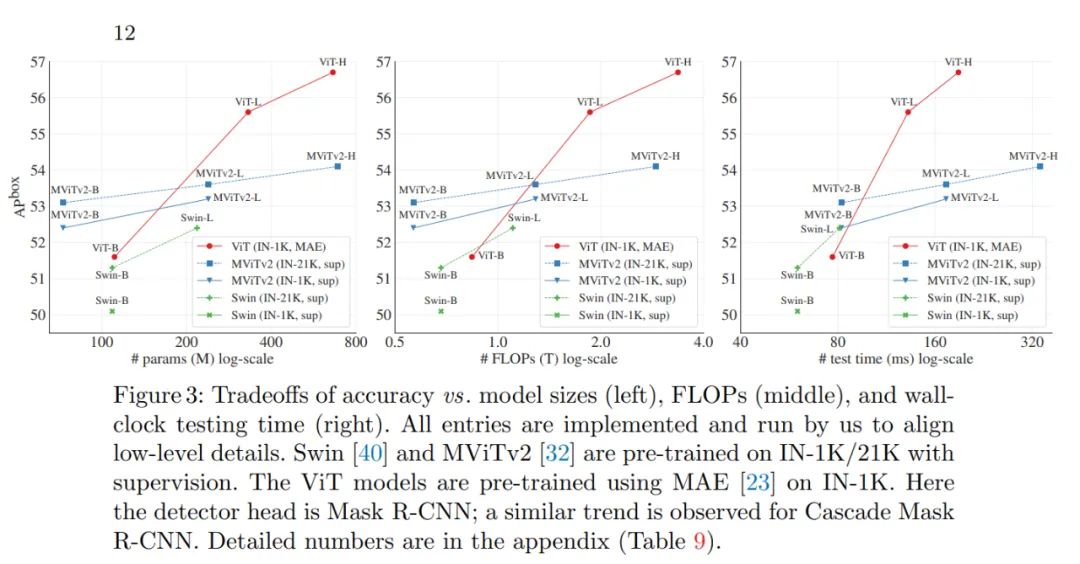
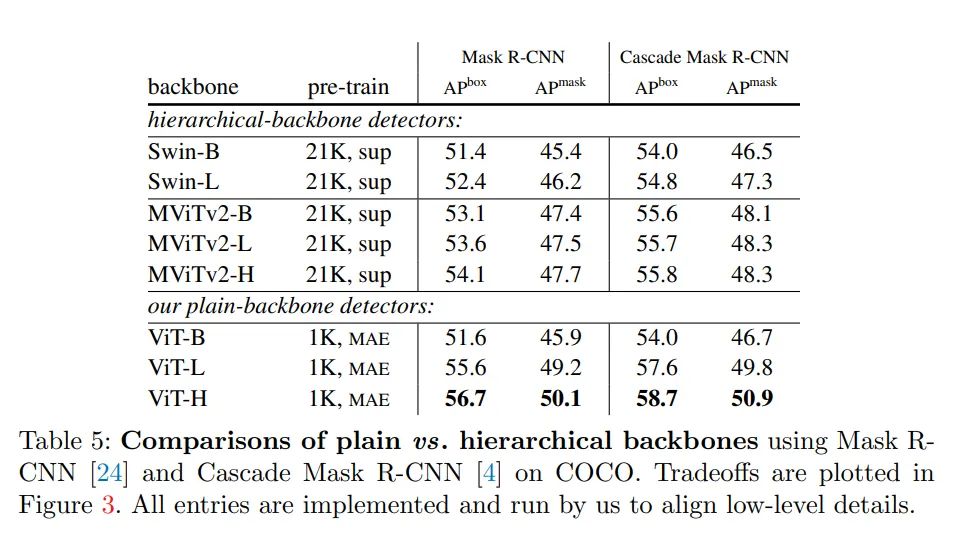
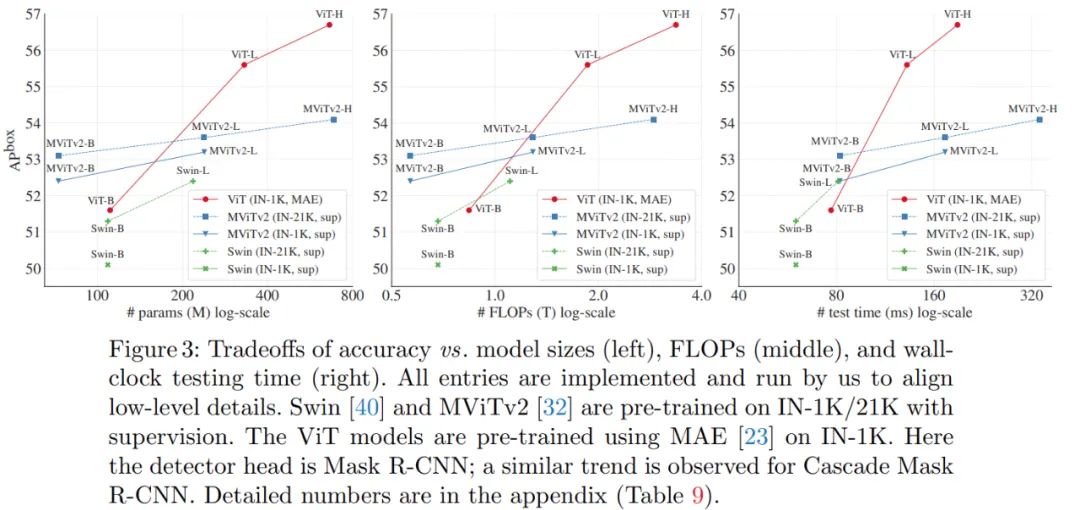
与分层主干的对比
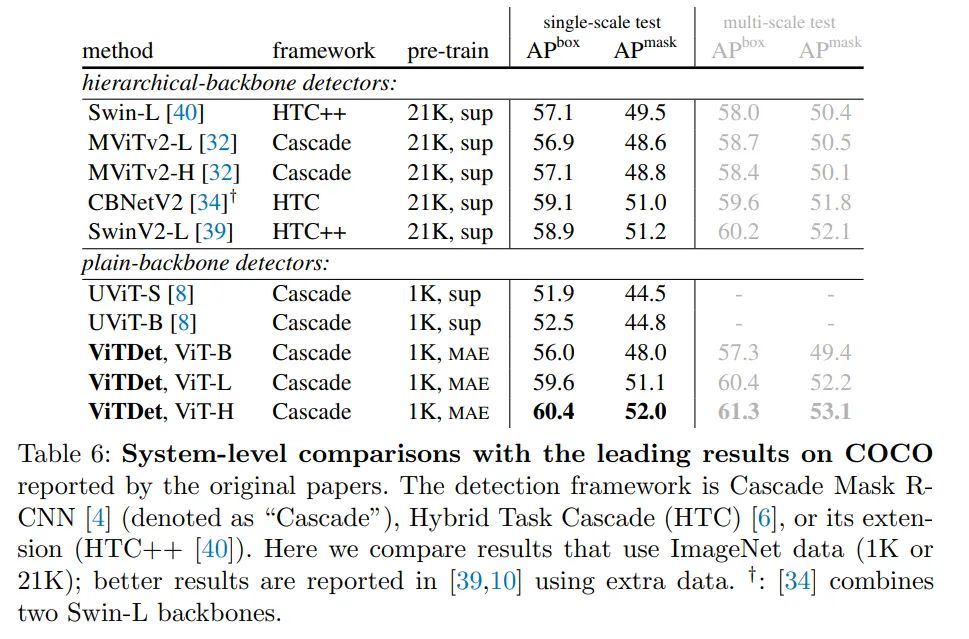
与之前系统的对比

点个在看 paper不断!
评论