
深入浅出理解 Prometheus,优点全掌握
点击“程序员面试吧”,选择“星标🔝”
下拉至文末查看更多

背景
概念:Instance、Job、Metric、Metric Name、Metric Label、Metric Value、Metric Type(Counter、Gauge、Histogram、Summary)、DataType(Instant Vector、Range Vector、Scalar、String)、Operator、Function
日常监控
假设需要监控 WebServerA 每个API的请求量为例,需要监控的维度包括:服务名(job)、实例IP(instance)、API名(handler)、方法(method)、返回码(code)、请求量(value)。
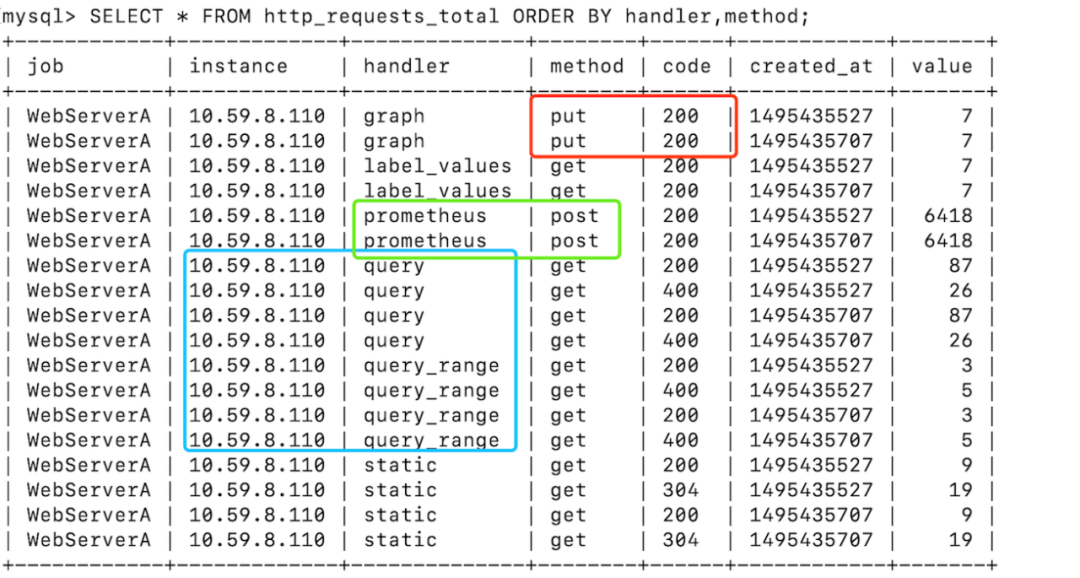
如果以SQL为例,演示常见的查询操作:
查询 method=put 且 code=200 的请求量(红框)
SELECT * from http_requests_total WHERE code=”200” AND method=”put” AND created_at BETWEEN 1495435700 AND 1495435710;
查询 handler=prometheus 且 method=post 的请求量(绿框)
SELECT * from http_requests_total WHERE handler=”prometheus” AND method=”post” AND created_at BETWEEN 1495435700 AND 1495435710;
查询 instance=10.59.8.110 且 handler 以 query 开头 的请求量(绿框)
SELECT * from http_requests_total WHERE handler=”query” AND instance=”10.59.8.110” AND created_at BETWEEN 1495435700 AND 1495435710;
通过以上示例可以看出,在常用查询和统计方面,日常监控多用于根据监控的维度进行查询与时间进行组合查询。如果监控100个服务,平均每个服务部署10个实例,每个服务有20个API,4个方法,30秒收集一次数据,保留60天。那么总数据条数为:100(服务) 10(实例) 20(API) 4(方法) 86400(1天秒数)* 60(天) / 30(秒)= 138.24 亿条数据,写入、存储、查询如此量级的数据是不可能在Mysql类的关系数据库上完成的。因此 Prometheus 使用 TSDB 作为存储引擎。
存储引擎
存储的数据量级十分庞大 大部分时间都是写入操作 写入操作几乎是顺序添加,大多数时候数据到达后都以时间排序 写操作很少写入很久之前的数据,也很少更新数据。大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库 删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据 基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用 读操作是十分典型的升序或者降序的顺序读 高并发的读操作十分常见
那么 TSDB 是怎么实现以上功能的呢?
"labels": [{"latency": "500"}]"samples":[{"timestamp": 1473305798,"value": 0.9}]
原始数据分为两部分 label, samples。前者记录监控的维度(标签:标签值),指标名称和标签的可选键值对唯一确定一条时间序列(使用 series_id 代表);后者包含包含了时间戳(timestamp)和指标值(value)。
series^│. . . . . . . . . . . . server{latency="500"}│. . . . . . . . . . . . server{latency="300"}│. . . . . . . . . . . server{}│. . . . . . . . . . . .v<-------- time ---------->
TSDB 使用 timeseries:doc:: 为 key 存储 value。为了加速常见查询查询操作:label 和 时间范围结合。TSDB 额外构建了三种索引:Series, Label Index 和 Time Index。
以标签 latency 为例:
Series
存储两部分数据。一部分是按照字典序的排列的所有标签键值对序列(series);另外一部分是时间线到数据文件的索引,按照时间窗口切割存储数据块记录的具体位置信息,因此在查询时可以快速跳过大量非查询窗口的记录数据
Label Index
每对 label 为会以 index:label: 为 key,存储该标签所有值的列表,并通过引用指向 Series 该值的起始位置。
Time Index
数据会以 index:timeseries:: 为 key,指向对应时间段的数据文件
数据计算
一次计算,处处查询

本文作者:cyningsun
本文地址:https://www.cyningsun.com/02-22-2020/hidden-secret-to-understanding-prometheus.html