
开箱即用!深入浅出Prometheus监控神器

导语 | Prometheus是一个开源的完整监控解决方案,本文将从指标抓取到查询及可视化展示,以及最后的监控告警,对Prometheus做一个基本的认识。
一、简介
Prometheus是古希腊神话里泰坦族的一名神明,名字的意思是“先见之明”,下图中是Prometheus被宙斯惩罚,饱受肝脏日食夜长之苦。

下面就是我们CRUD Boy所了解的Prometheus,下面是其官网封面图引导语:From metrics to insight,从指标到洞察力,通过指标去洞察你的系统,为我们的系统提供指标收集和监控的开源解决方案。也就是说,Prometheus是一个数据监控的解决方案,让我们能随时掌握系统运行的状态,快速定位问题和排除故障。

Prometheus发展速度很快,12年开发完成,16年加入CNCF,成为继K8s 之后第二个CNCF托管的项目,目前Github 42k的🌟,而且社区很活跃,维护频率很高,基本稳定在1个月1个小版本的迭代速度。
二、整体生态
Prometheus提供了从指标暴露,到指标抓取、存储和可视化,以及最后的监控告警等一系列组件。
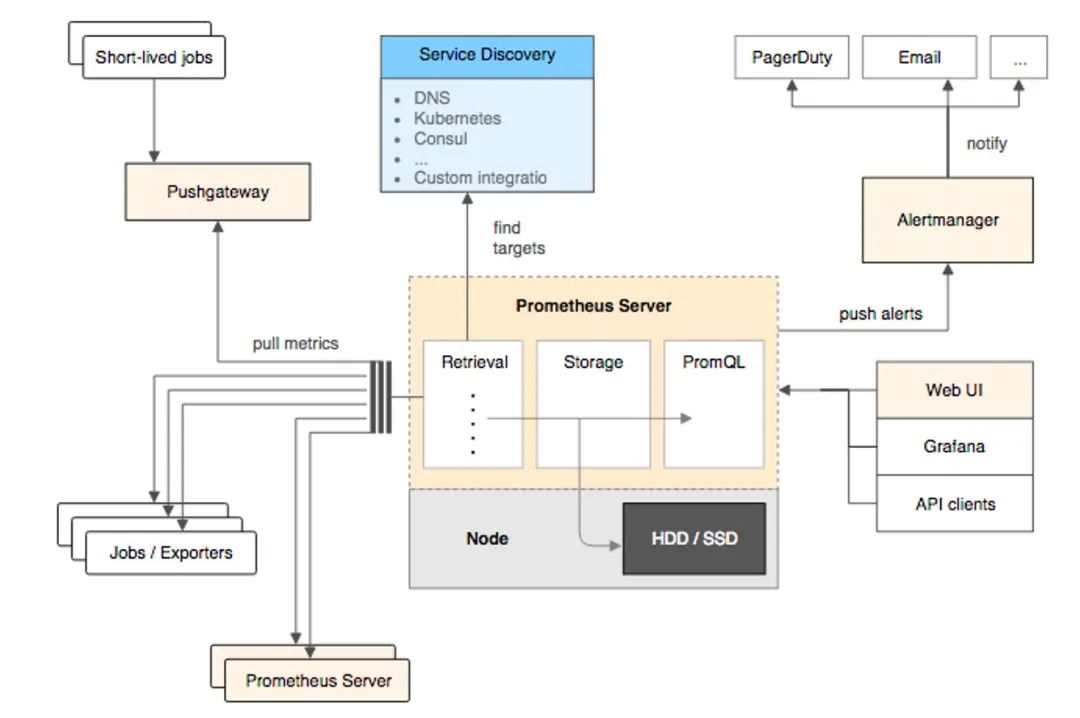
(一)指标暴露
每一个被Prometheus监控的服务都是一个Job,Prometheus为这些Job 提供了官方的SDK ,利用这个SDK可以自定义并导出自己的业务指标,也可以使用Prometheus官方提供的各种常用组件和中间件的Exporter(比如常用的MySQL,Consul等等)。对于短时间执行的脚本任务或者不好直接 Pull指标的服务,Prometheus提供了PushGateWay网关给这些任务将服务指标主动推Push到网关,Prometheus再从这个网关里Pull指标。
(二)指标抓取
上面提到了Push和Pull,其实这是两种指标抓取模型。
Pull模型:监控服务主动拉取被监控服务的指标。
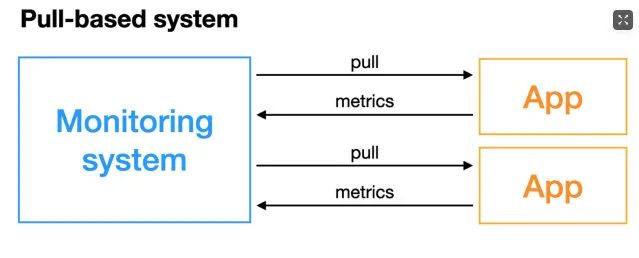
被监控服务一般通过主动暴露metrics端口或者通过Exporter的方式暴露指标,监控服务依赖服务发现模块发现被监控服务,从而去定期的抓取指标。
Push模型:被监控服务主动将指标推送到监控服务,可能需要对指标做协议适配,必须得符合监控服务要求的指标格式。
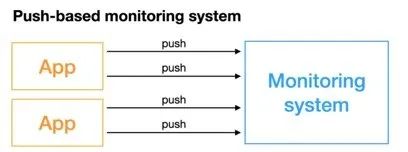
对于Prometheus中的指标抓取,采用的是Pull模型,默认是一分钟去拉取一次指标,通过Prometheus.yaml配置文件中的scrape_interval配置项配置,Prometheus对外都是用的Pull模型,一个是Pull Exporter的暴露的指标,一个是Pull PushGateway暴露的指标。
(三)指标存储和查询
指标抓取后会存储在内置的时序数据库中,Prometheus也提供了PromQL 查询语言给我们做指标的查询,我们可以在Prometheus的WebUI上通过 PromQL,可视化查询我们的指标,也可以很方便的接入第三方的可视化工具,例如grafana。
(四)监控告警
prometheus提供了alertmanageer基于promql来做系统的监控告警,当promql查询出来的指标超过我们定义的阈值时,prometheus会发送一条告警信息到alertmanager,manager会将告警下发到配置好的邮箱或者微信。
三、工作原理
Prometheus的从被监控服务的注册到指标抓取到指标查询的流程分为五个步骤:
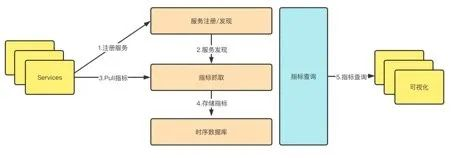
(一)服务注册
被监控服务在Prometheus中是一个Job存在,被监控服务的所有实例在 Prometheus中是一个target的存在,所以被监控服务的注册就是在 Prometheus中注册一个Job和其所有的target,这个注册分为:静态注册
静态注册:静态的将服务的IP和抓取指标的端口号配置在Prometheus yaml文件的scrape_configs配置下:
scrape_configs:- job_name: "prometheus"static_configs:- targets: ["localhost:9090"]
以上就是注册了一个名为prometheus的服务,这个服务下有一个实例,暴露的抓取地址是localhost:9090。
动态注册:动态注册就是在Prometheus yaml文件的scrape_configs配置下配置服务发现的地址和服务名,Prometheus会去该地址,根据你提供的服务名动态发现实例列表,在Prometheus中,支持consul,DNS,文件,K8s等多种服务发现机制。基于consul的服务发现:
job_name: "node_export_consul"metrics_path: /node_metricsscheme: httpconsul_sd_configs:server: localhost:8500services:node_exporter
我们consul的地址就是:localhost:8500,服务名是node_exporter,在这个服务下有一个exporter实例:localhost:9600。
注意:如果是动态注册,最好加上这两配置,静态注册指标拉取的路径会默认的帮我们指定为 metrics_path:/metrics,所以如果暴露的指标抓取路径不同或者是动态的服务注册,最好加上这两个配置。不然会报错“INVALID“ is not a valid start token,演示下,百度了一下,这里可能是数据格式不统一导致。
metrics_path: /node_metricsscheme: http
最后可以在webUI中查看发现的实例:

目前,Prometheus支持多达二十多种服务发现协议:
(二)配置更新
在更新完Prometheus的配置文件后,我们需要更新我们的配置到程序内存里,这里的更新方式有两种,第一种简单粗暴,就是重启Prometheus,第二种是动态更新的方式。如何实现动态的更新Prometheus配置。
第一步:首先要保证启动Prometheus的时候带上启动参数:--web.enable-lifecycle
prometheus --config.file=/usr/local/etc/prometheus.yml --web.enable-lifecycle第二步:去更新我们的Prometheus配置:
curl -v --request POST 'http://localhost:9090/-/reload'第三步:更新完配置后,我们可以通过Post请求的方式,动态更新配置:
原理:
Prometheus在web模块中,注册了一个handler:
if o.EnableLifecycle {router.Post("/-/quit", h.quit)router.Put("/-/quit", h.quit)router.Post("/-/reload", h.reload) // reload配置router.Put("/-/reload", h.reload)}
通过h.reload这个handler方法实现:这个handler就是往一个channle中发送一个信号:
func (h *Handler) reload(w http.ResponseWriter, r *http.Request) {rc := make(chan error)h.reloadCh <- rc // 发送一个信号到channe了中if err := <-rc; err != nil {http.Error(w, fmt.Sprintf("failed to reload config: %s", err), http.StatusInternalServerError)}}
在main函数中会去监听这个channel,只要有监听到信号,就会做配置的reload,重新将新配置加载到内存中
case rc := <-webHandler.Reload():if err := reloadConfig(cfg.configFile, cfg.enableExpandExternalLabels, cfg.tsdb.EnableExemplarStorage, logger, noStepSubqueryInterval, reloaders...); err != nil {level.Error(logger).Log("msg", "Error reloading config", "err", err)rc <- err} else {rc <- nil}
(三)指标抓取和存储
Prometheus对指标的抓取采取主动Pull的方式,即周期性的请求被监控服务暴露的metrics接口或者是PushGateway,从而获取到Metrics指标,默认时间是15s抓取一次,配置项如下:
global:scrape_interval: 15s
抓取到的指标会被以时间序列的形式保存在内存中,并且定时刷到磁盘上,默认是两个小时回刷一次。并且为了防止Prometheus 发生崩溃或重启时能够恢复数据,Prometheus也提供了类似MySQL中binlog一样的预写日志,当Prometheus崩溃重启时,会读这个预写日志来恢复数据。
四、Metric指标
(一)数据模型
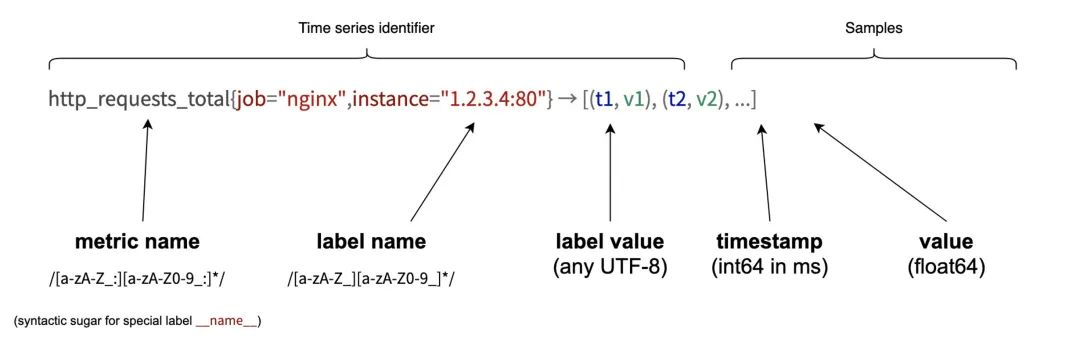
Prometheus采集的所有指标都是以时间序列的形式进行存储,每一个时间序列有三部分组成:
指标名和指标标签集合:metric_name{
。
时间戳:描述当前时间序列的时间,单位:毫秒。
样本值:当前监控指标的具体数值,比如http_request_total的值就是请求数是多少。
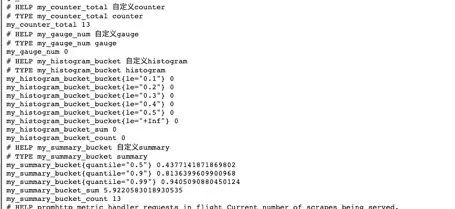
可以通过查看Prometheus的metrics接口查看所有上报的指标:

所有的指标也都是通过如下所示的格式来标识的:
{ >, ...} value // 指标的具体格式,<指标名>{标签集合} 指标值
(二)指标类型
Prometheus底层存储上其实并没有对指标做类型的区分,都是以时间序列的形式存储,但是为了方便用户的使用和理解不同监控指标之间的差异,Prometheus定义了4种不同的指标类型:计数器counter,仪表盘gauge,直方图histogram,摘要summary。
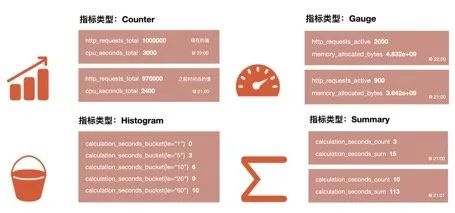
Counter计数器:
Counter类型和redis的自增命令一样,只增不减,通过Counter指标可以统计Http请求数量,请求错误数,接口调用次数等单调递增的数据。同时可以结合increase和rate等函数统计变化速率,后续我们会提到这些内置函数。

Gauge仪表盘:
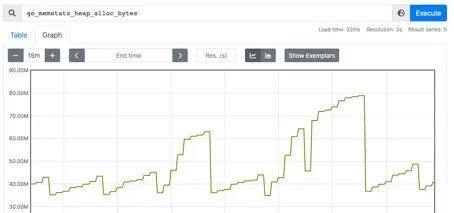
和Counter不同,Gauge是可增可减的,可以反映一些动态变化的数据,例如当前内存占用,CPU利用,Gc次数等动态可上升可下降的数据,在Prometheus上通过Gauge,可以不用经过内置函数直观的反映数据的变化情况,如下图表示堆可分配的空间大小:
上面两种是数值指标,代表数据的变化情况,Histogram和Summary是统计类型的指标,表示数据的分布情况。
Histogram直方图:
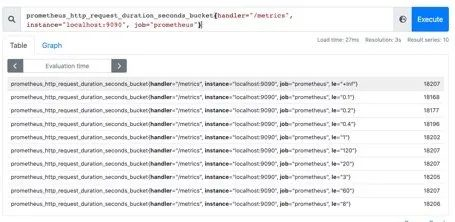
Histogram是一种直方图类型,可以观察到指标在各个不同的区间范围的分布情况,如下图所示:可以观察到请求耗时在各个桶的分布。
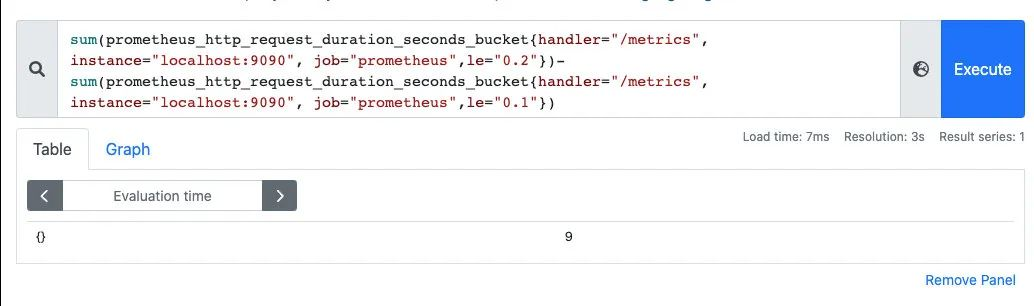
有一点要注意的是,Histogram是累计直方图,即每一个桶的是只有上区间,例如下图表示小于0.1毫秒(le=“0.1”)的请求数量是18173个,小于 0.2毫秒(le=“0.2”)的请求是18182 个,在le=“0.2”这个桶中是包含了 le=“0.1”这个桶的数据,如果我们要拿到0.1毫秒到0.2毫秒的请求数量,可以通过两个桶想减得到。
在直方图中,还可以通过histogram_quantile函数求出百分位数,比如 P50,P90,P99等数据。
Summary摘要
Summary也是用来做统计分析的,和Histogram区别在于,Summary直接存储的就是百分位数,如下所示:可以直观的观察到样本的中位数,P90和P99。
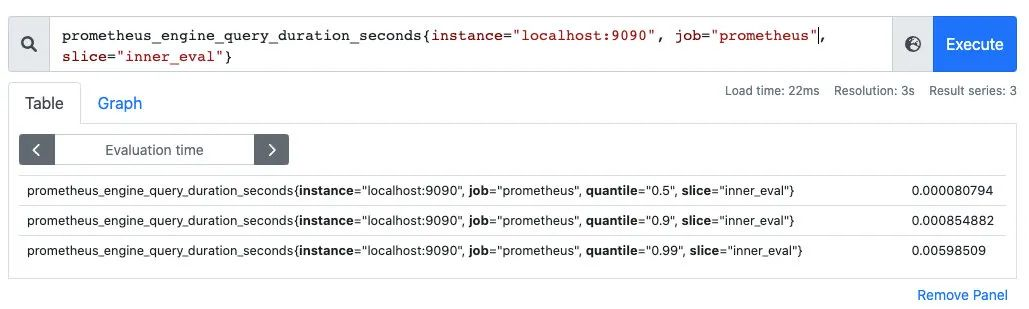
Summary的百分位数是客户端计算好直接让Prometheus抓取的,不需要 Prometheus计算,直方图是通过内置函数histogram_quantile在 Prometheus服务端计算求出。
(三)指标导出
指标导出有两种方式,一种是使用Prometheus社区提供的定制好的 Exporter对一些组件诸如MySQL,Kafka等的指标作导出,也可以利用社区提供的Client来自定义指标导出。
github.com/prometheus/client_golang/prometheus/promhttp自定义Prometheus exporter:
package mainimport ("net/http""github.com/prometheus/client_golang/prometheus/promhttp")func main() {http.Handle("/metrics", promhttp.Handler())http.ListenAndServe(":8080", nil)}
访问:http://localhost:8080/metrics,即可看到导出的指标,这里我们没有自定义任何的指标,但是能看到一些内置的Go的运行时指标和promhttp相关的指标,这个Client默认为我们暴露的指标,go_:以 go_ 为前缀的指标是关于Go运行时相关的指标,比如垃圾回收时间、goroutine 数量等,这些都是Go客户端库特有的,其他语言的客户端库可能会暴露各自语言的其他运行时指标。promhttp_:来自promhttp工具包的相关指标,用于跟踪对指标请求的处理。
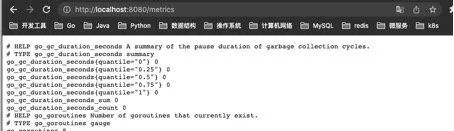

添加自定义指标:
package mainimport ("net/http""github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promhttp")func main() {// 1.定义指标(类型,名字,帮助信息)myCounter := prometheus.NewCounter(prometheus.CounterOpts{Name: "my_counter_total",Help: "自定义counter",})// 2.注册指标prometheus.MustRegister(myCounter)// 3.设置指标值myCounter.Add(23)http.Handle("/metrics", promhttp.Handler())http.ListenAndServe(":8080", nil)}
运行:
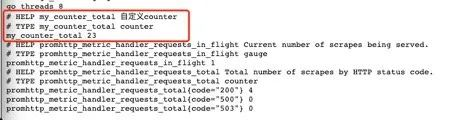
模拟下在业务中上报接口请求量:
package mainimport ("fmt""net/http""github.com/prometheus/client_golang/prometheus")var (MyCounter prometheus.Counter)// init 注册指标func init() {// 1.定义指标(类型,名字,帮助信息)MyCounter = prometheus.NewCounter(prometheus.CounterOpts{Name: "my_counter_total",Help: "自定义counter",})// 2.注册指标prometheus.MustRegister(MyCounter)}// Sayhellofunc Sayhello(w http.ResponseWriter, r *http.Request) {// 接口请求量递增MyCounter.Inc()fmt.Fprintf(w, "Hello Wrold!")}
main.go:
package mainimport ("net/http""github.com/prometheus/client_golang/prometheus/promhttp")func main() {http.Handle("/metrics", promhttp.Handler())http.HandleFunc("/counter",Sayhello)http.ListenAndServe(":8080", nil)}
一开始启动时,指标counter是0
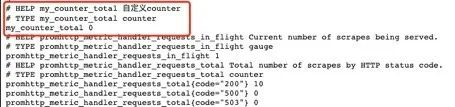
调用:/counter接口后,指标数据发生了变化,这样就可以简单实现了接口请求数的统计:
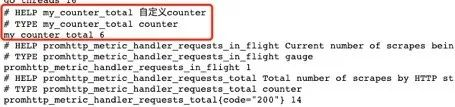
对于其他指标定义方式是一样的:
var (MyCounter prometheus.CounterMyGauge prometheus.GaugeMyHistogram prometheus.HistogramMySummary prometheus.Summary)// init 注册指标func init() {// 1.定义指标(类型,名字,帮助信息)MyCounter = prometheus.NewCounter(prometheus.CounterOpts{Name: "my_counter_total",Help: "自定义counter",})// 定义gauge类型指标MyGauge = prometheus.NewGauge(prometheus.GaugeOpts{Name: "my_gauge_num",Help: "自定义gauge",})// 定义histogramMyHistogram = prometheus.NewHistogram(prometheus.HistogramOpts{Name: "my_histogram_bucket",Help: "自定义histogram",Buckets: []float64{0.1,0.2,0.3,0.4,0.5}, // 需要指定桶})// 定义SummaryMySummary = prometheus.NewSummary(prometheus.SummaryOpts{Name: "my_summary_bucket",Help: "自定义summary",// 这部分可以算好后在setObjectives: map[float64]float64{0.5: 0.05,0.9: 0.01,0.99: 0.001,},})// 2.注册指标prometheus.MustRegister(MyCounter)prometheus.MustRegister(MyGauge)prometheus.MustRegister(MyHistogram)prometheus.MustRegister(MySummary)}
上面的指标都是没有设置标签的,我们一般的指标都是带有标签的,如何设置指标的标签呢?
如果我要设置带标签的counter类型指标,只需要将原来的NewCounter方法替换为NewCounterVec方法即可,并且传入标签集合。
MyCounter *prometheus.CounterVec// 1.定义指标(类型,名字,帮助信息)MyCounter = prometheus.NewCounterVec(prometheus.CounterOpts{Name: "my_counter_total",Help: "自定义counter",},// 标签集合[]string{"label1","label2"},)// 带标签的set指标值MyCounter.With(prometheus.Labels{"label1":"1","label2":"2"}).Inc()

其他同理。
五、PromQL
刚刚提到了Prometheus中指标有哪些类型以及如何导出我们的指标,现在指标导出到Prometheus了,利用其提供的PromQL可以查询我们导出的指标。
PromQL是Prometheus为我们提供的函数式的查询语言,查询表达式有四种类型:
字符串:只作为某些内置函数的参数出现;
标量:单一的数字值,可以是函数参数,也可以是函数的返回结果;
瞬时向量:某一时刻的时序数据;
区间向量:某一时间区间内的时序数据集合。
(一)瞬时查询
直接通过指标名即可进行查询,查询结果是当前指标最新的时间序列,比如查询Gc累积消耗的时间:
go_gc_duration_seconds_count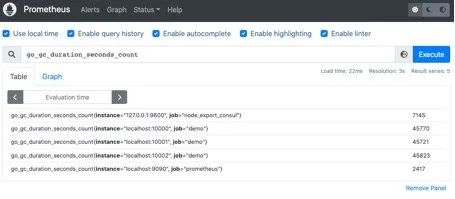
我们可以看到查询出来有多个同名指标结果 可以用{}做标签过滤查询:比如我们想查指定实例的指标:
go_gc_duration_seconds_count{instance="127.0.0.1:9600"}
而且也支持则表达式,通过=~指定正则表达式,如下所示:查询所有instance是localhost开头的指标
go_gc_duration_seconds_count{instance=~"localhost.*"}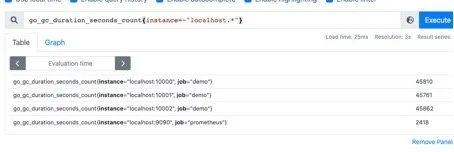
(二)范围查询
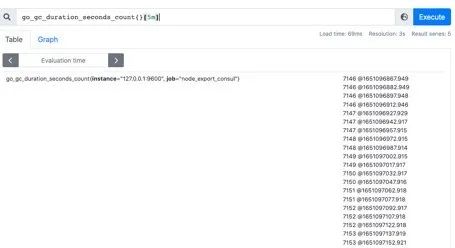
范围查询的结果集就是区间向量,可以通过[]指定时间来做范围查询,查询5分钟内的Gc累积消耗时间:
go_gc_duration_seconds_count{}[5m]注意:这里范围查询第一个点并不一定精确到刚刚好5分钟前的那个时序样本点,他是以5分钟作为一个区间,寻找这个区间的第一个点到最后一个样本点。
时间单位:
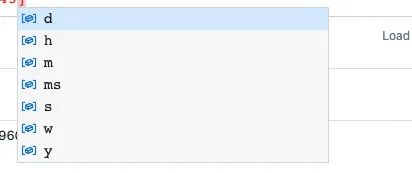
d:天,h:小时,m:分钟,ms:毫秒,s:秒,w:周,y:年
同样支持类似SQL中的offset查询,如下:查询一天前当前5分钟前的时序数据集:
go_gc_duration_seconds_count{}[5m] offset 1d(三)内置函数
Prometheus内置了很多函数,这里主要记录下常用的几个函数的使用:
rate和irate函数:rate函数可以用来求指标的平均变化速率
rate函数=时间区间前后两个点的差 / 时间范围一般rate函数可以用来求某个时间区间内的请求速率,也就是我们常说的QPS
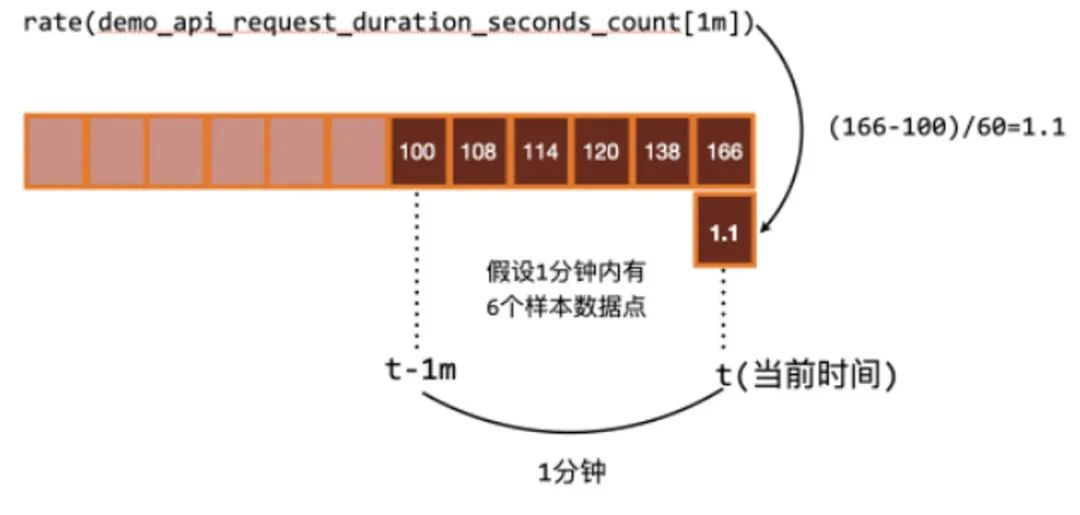
但是rate函数只是算出来了某个时间区间内的平均速率,没办法反映突发变化,假设在一分钟的时间区间里,前50秒的请求量都是0到10左右,但是最后10秒的请求量暴增到100以上,这时候算出来的值可能无法很好的反映这个峰值变化。这个问题可以通过irate函数解决,irate函数求出来的就是瞬时变化率。
时间区间内最后两个样本点的差 / 最后两个样本点的时间差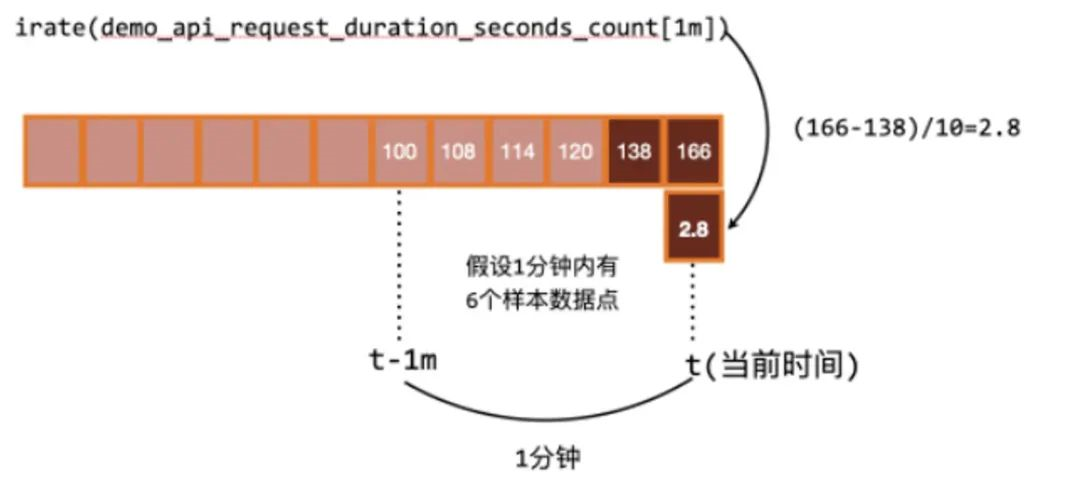
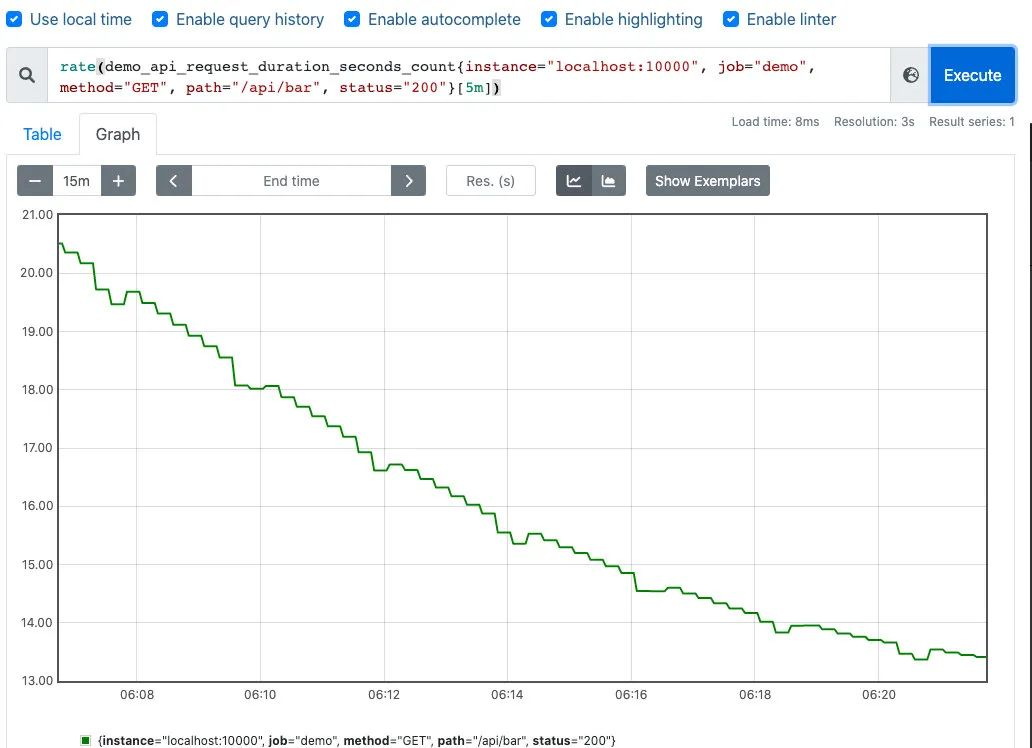
可以通过图像看下两者的区别:irate函数的图像峰值变化大,rate函数变化较为平缓。
rate函数
irate函数

聚合函数:Sum() by() without()
也是上边的例子,我们在求指定接口的QPS的时候,可能会出现多个实例的QPS的计算结果,如下是存在多个接口,三个服务的QPS。
rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])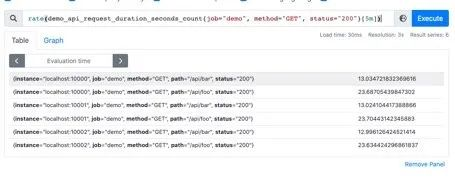
利用sum函数可以将三个QPS聚合,即可得到整个服务该接口的QPS:其实Sum就是将指标值做相加。
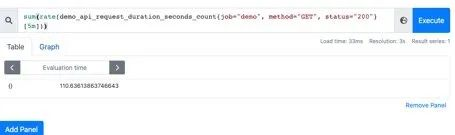
但是这样直接的相加太笼统抽象了,可以配合by和without函数在sum的时候,基于某些标签分组,类似SQL中的group by
例如,我可以根据请求接口标签分组:这样拿到的就是具体接口的QPS:
sum(rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])) by(path)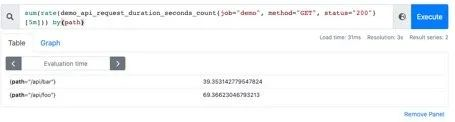
也可以不根据接口路径分组:通过without指定:
sum(rate(demo_api_request_duration_seconds_count{job="demo", method="GET", status="200"}[5m])) without(path)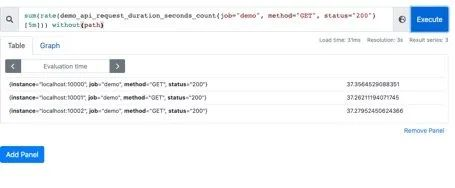
可以通过histogram_quantile函数做数据统计:可以用来统计百分位数:第一个参数是百分位,第二个histogram指标,这样计算出来的就是中位数,即P50
histogram_quantile(0.5,go_gc_pauses_seconds_total_bucket)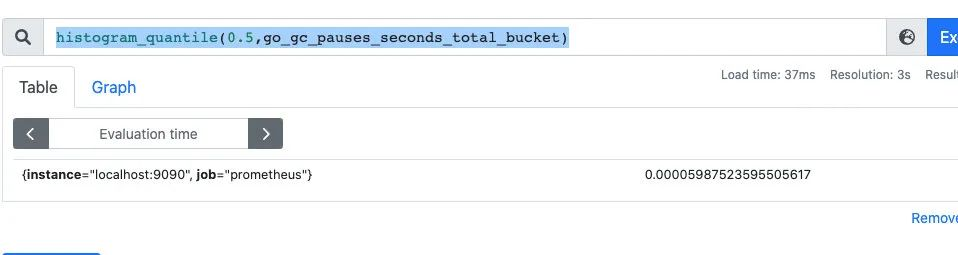
分享之前和同事一起发现的坑:
在刚刚写的自定义exporter上新增几个histogram的样本点:
MyHistogram.Observe(0.3)MyHistogram.Observe(0.4)MyHistogram.Observe(0.5)
histogram的桶设置:
MyHistogram = prometheus.NewHistogram(prometheus.HistogramOpts{Name: "my_histogram_bucket",Help: "自定义histogram",Buckets: []float64{0,2.5,5,7.5,10}, // 需要指定桶})
如果这样的话,所有指标都会直接进入到第一个桶,即0到2.5这个桶,如果我要计算中位数,那么这个中位数按照数学公式来算的话,肯定是在0到2.之间的,而且肯定是0.3到0.5之间。
我用histogram_quantile函数计算下:计算结果是1.25,其实已经不对了。
histogram_quantile(0.5,my_histogram_bucket_bucket)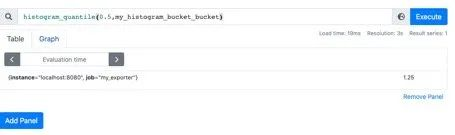
我在计算下P99,等于2.475:
histogram_quantile(0.99,my_histogram_bucket_bucket)
我的指标都是不大于1的,为啥算出来的P50和P99都这么离谱呢?
这是因为Prometheus他是不保存你具体的指标数值的,他会帮你把指标放到具体的桶,但是他不会保存你指标的值,计算的分位数是一个预估的值,怎么预估呢?就是假设每个桶内的样本分布是均匀的,线性分布来计算的,比如刚刚的P50,其实就是算排在第50%位置的样本值,因为刚刚所有的数据都落在了第一个桶,那么他在计算的时候就会假定这个50%值在第一个桶的中点,他就会假定这个数就是0.5_ 2.5,P99就是第一个桶的99%的位置,他就会假定这个数就是0.99 _ 2.5。
导致这个误差较大的原因就是我们的bucket设置的不合理。
重新定义桶:
// 定义histogramMyHistogram = prometheus.NewHistogram(prometheus.HistogramOpts{Name: "my_histogram_bucket",Help: "自定义histogram",Buckets: []float64{0.1,0.2,0.3,0.4,0.5}, // 需要指定桶})
上报数据:
MyHistogram.Observe(0.1)MyHistogram.Observe(0.3)MyHistogram.Observe(0.4)

重新计算 P50,P99:


桶设置的越合理,计算的误差越小。
六、Grafana可视化
除了可以利用Prometheus提供的webUI可视化我们的指标外,还可以接入Grafana来做指标的可视化。
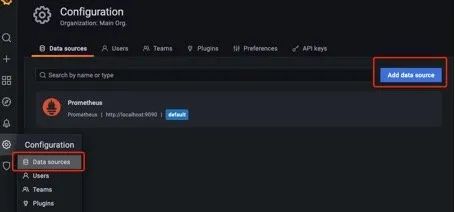
第一步,对接数据源:
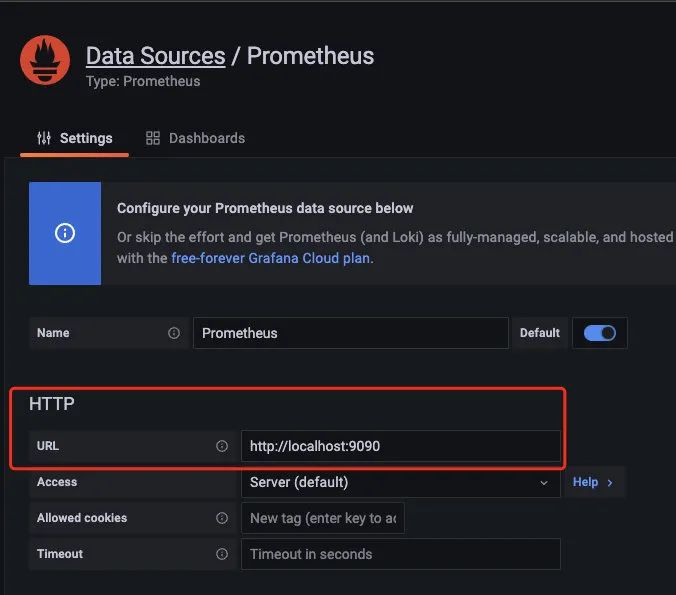
配置好prometheus的地址:
第二步:创建仪表盘
编辑仪表盘:
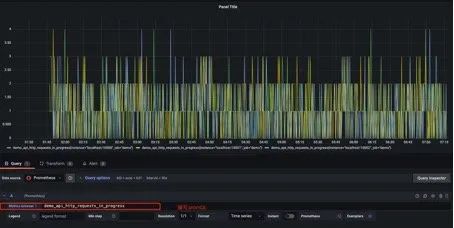
在metrics处编写PromQL即可完成查询和可视化:
仪表盘编辑完后,可以导出对应的 json 文件,方便下次导入同样的仪表盘:
以上是我之前搭建的仪表盘:
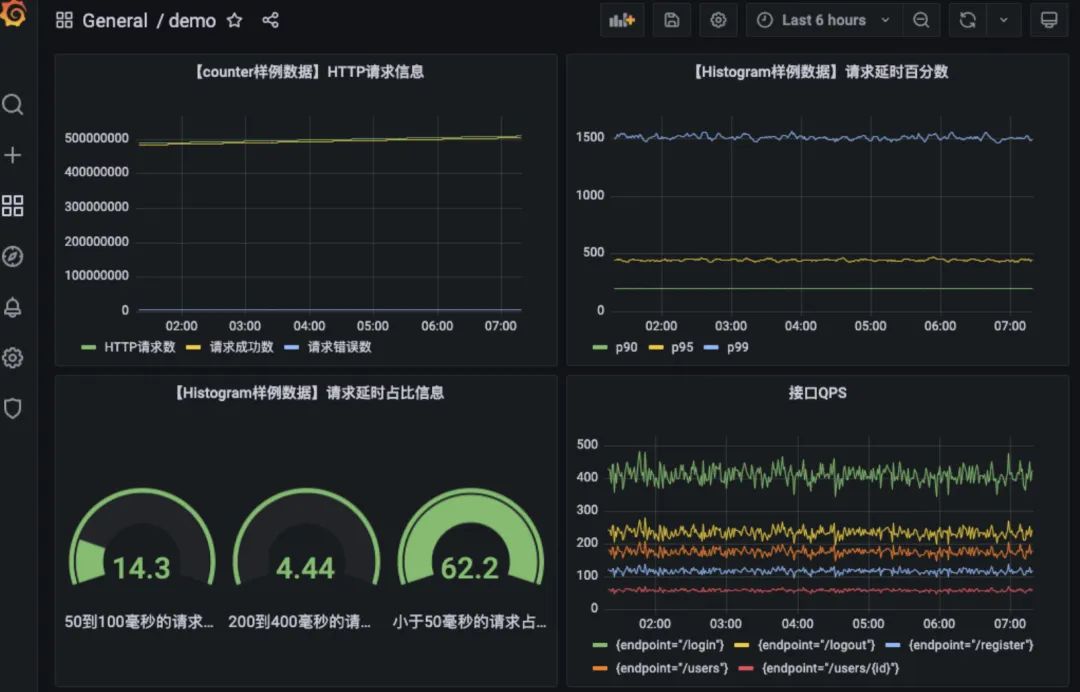
七、监控告警
AlertManager是prometheus提供的告警信息下发组件,包含了对告警信息的分组,下发,静默等策略。配置完成后可以在webui上看到对应的告警策略信息。告警规则也是基于PromQL进行定制的。
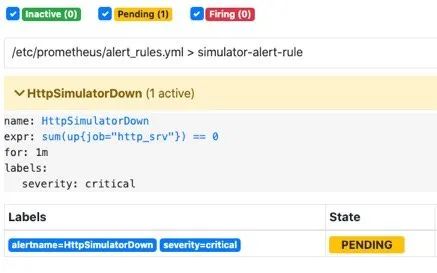
编写告警配置:当Http_srv这个服务挂了,Prometheus采集不到指标,并且持续时间1分钟,就会触发告警
groups:name: simulator-alert-rulerules:alert: HttpSimulatorDownexpr: sum(up{job="http_srv"}) == 0for: 1mlabels:severity: critical
在prometheus.yml中配置告警配置文件,需要配置上alertmanager的地址和告警文件的地址
# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets: ['localhost:9093']# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:- "alert_rules.yml"#- "first_rules.yml"
配置告警信息,例如告警发送地址,告警内容模版,分组策略等都在alertmanager的配置文件中配置:
global:smtp_smarthost: 'smtp.qq.com:465'smtp_from: 'xxxx@qq.com'smtp_auth_username: 'xxxx@qq.com'smtp_auth_password: 'xxxx'smtp_require_tls: falseroute:group_interval: 1mrepeat_interval: 1mreceiver: 'mail-receiver'# group_by //采用哪个标签作为分组# group_wait //分组等待的时间,收到报警不是立马发送出去,而是等待一段时间,看看同一组中是否有其他报警,如果有一并发送# group_interval //告警时间间隔# repeat_interval //重复告警时间间隔,可以减少发送告警的频率# receiver //接收者是谁# routes //子路由配置receivers:name: 'mail-receiver'email_configs:to: 'xxxx@qq.com'
当我kill进程:

prometheus已经触发告警:
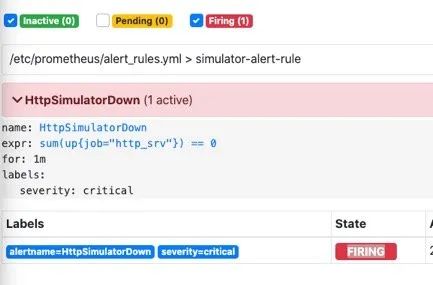
在等待1分钟,如果持续还是符合告警策略,则状态为从pending变为FIRING会发送邮件到我的邮箱
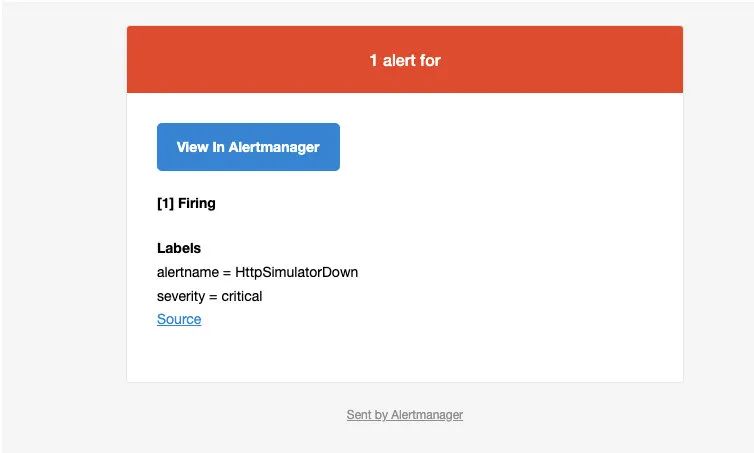
此时我的邮箱收到了一条告警消息:
alertmanager也支持对告警进行静默,在alertmanager的WEBUI中配置即可:
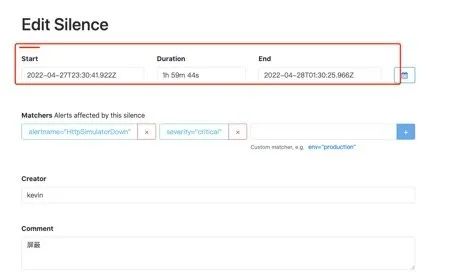
间隔了4分钟,没有收到告警,静默生效:

一个小时没有收到告警信息:

参考资料:
作者简介

kevinkrcai
腾讯后台开发工程师
腾讯后台开发工程师,目前负责游戏知几AI助手的后台开发工作。
推荐阅读
