
为什么 Redis 单线程却能支撑高并发?

阅读本文大概需要 7 分钟。
几种 I/O 模型
Blocking I/O

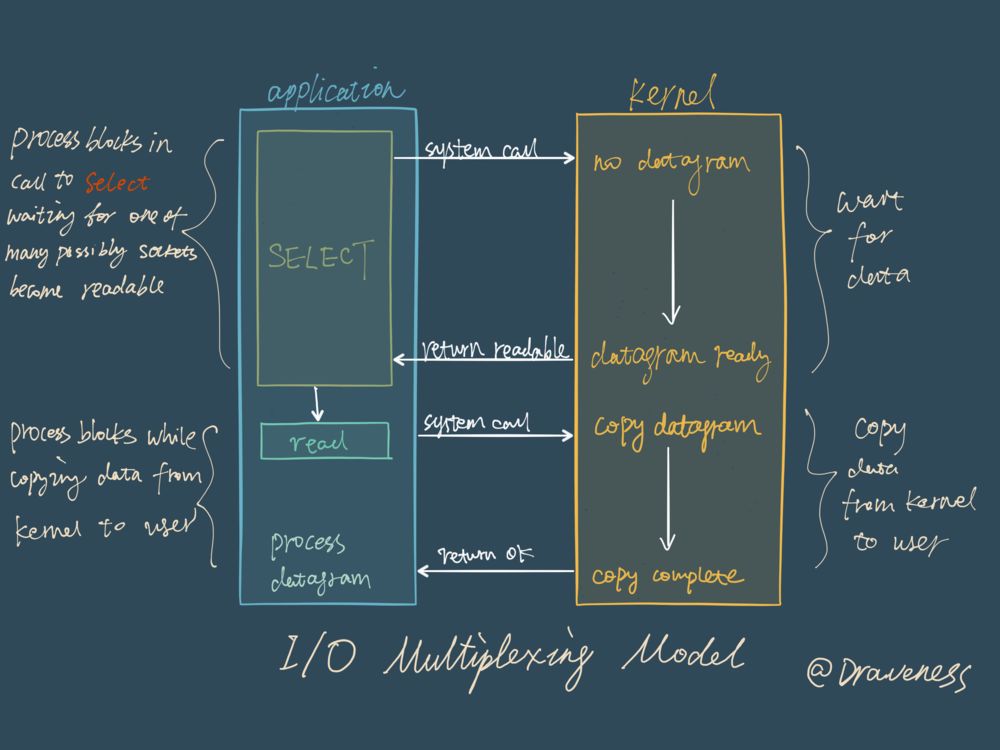
I/O 多路复用
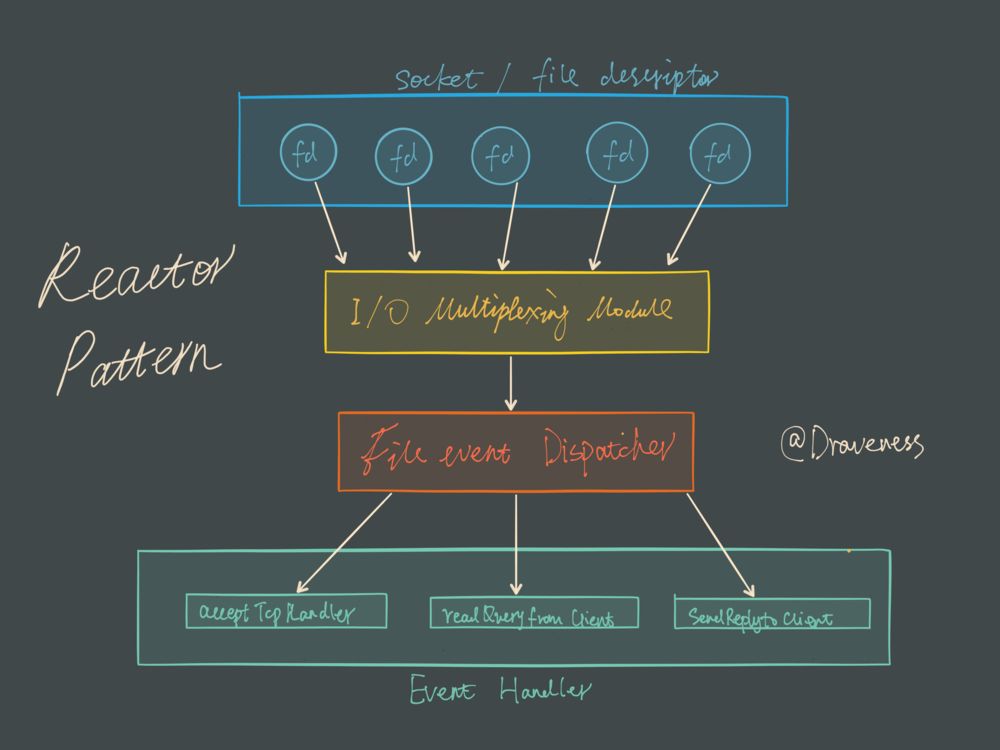
Reactor 设计模式
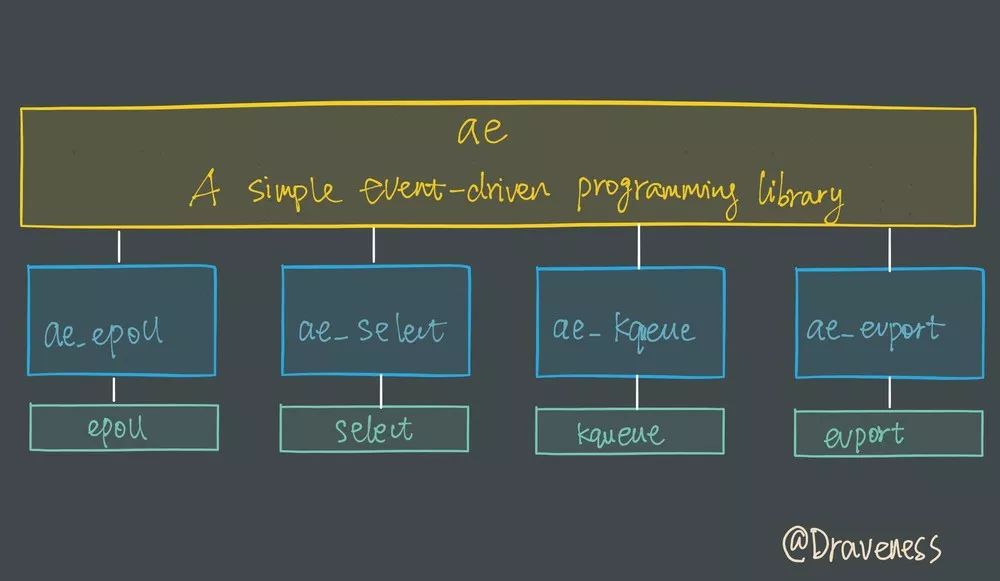
I/O 多路复用模块
// select
typedef struct aeApiState {
fd_set rfds, wfds;
fd_set _rfds, _wfds;
} aeApiState;
// epoll
typedef struct aeApiState {
int epfd;
struct epoll_event *events;
} aeApiState;
封装 select 函数
int fd = /* file descriptor */
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(fd, &rfds)
for ( ; ; ) {
select(fd+1, &rfds, NULL, NULL, NULL);
if (FD_ISSET(fd, &rfds)) {
/* file descriptor `fd` becomes readable */
}
}
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
FD_ZERO(&state->rfds);
FD_ZERO(&state->wfds);
eventLoop->apidata = state;
return 0;
}
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
if (mask & AE_READABLE) FD_SET(fd,&state->rfds);
if (mask & AE_WRITABLE) FD_SET(fd,&state->wfds);
return 0;
}
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, j, numevents = 0;
memcpy(&state->_rfds,&state->rfds,sizeof(fd_set));
memcpy(&state->_wfds,&state->wfds,sizeof(fd_set));
retval = select(eventLoop->maxfd+1,
&state->_rfds,&state->_wfds,NULL,tvp);
if (retval > 0) {
for (j = 0; j <= eventLoop->maxfd; j++) {
int mask = 0;
aeFileEvent *fe = &eventLoop->events[j];
if (fe->mask == AE_NONE) continue;
if (fe->mask & AE_READABLE && FD_ISSET(j,&state->_rfds))
mask |= AE_READABLE;
if (fe->mask & AE_WRITABLE && FD_ISSET(j,&state->_wfds))
mask |= AE_WRITABLE;
eventLoop->fired[numevents].fd = j;
eventLoop->fired[numevents].mask = mask;
numevents++;
}
}
return numevents;
}
封装 epoll 函数
static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
if (!state->events) {
zfree(state);
return -1;
}
state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */
if (state->epfd == -1) {
zfree(state->events);
zfree(state);
return -1;
}
eventLoop->apidata = state;
return 0;
}
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* If the fd was already monitored for some event, we need a MOD
* operation. Otherwise we need an ADD operation. */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}
typedef union epoll_data {
void *ptr;
int fd; /* 文件描述符 */
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll 事件 */
epoll_data_t data;
};
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) {
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
if (retval > 0) {
int j;
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN) mask |= AE_READABLE;
if (e->events & EPOLLOUT) mask |= AE_WRITABLE;
if (e->events & EPOLLERR) mask |= AE_WRITABLE;
if (e->events & EPOLLHUP) mask |= AE_WRITABLE;
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
return numevents;
}
子模块的选择
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
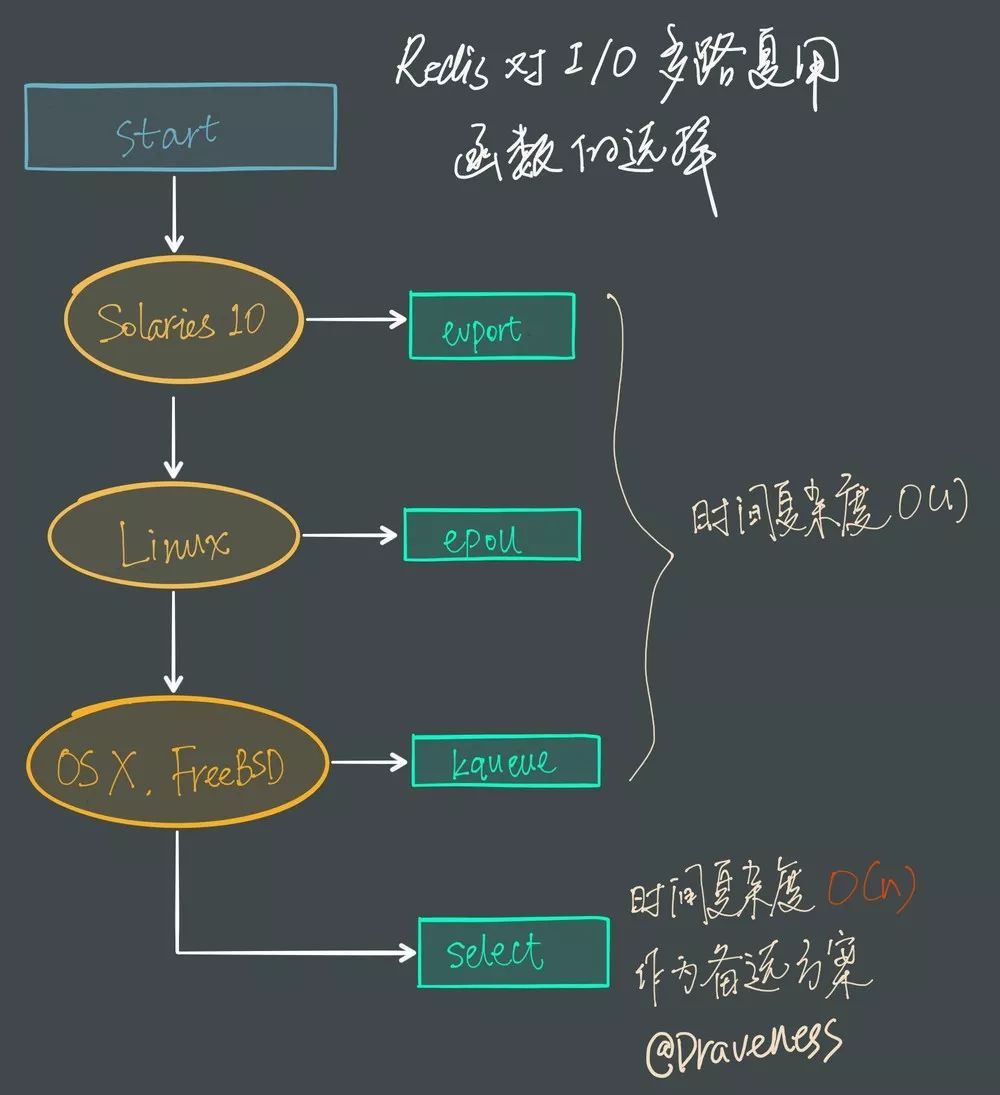
$O(1)$ 的 I/O 多路复用函数作为底层实现,包括 Solaries 10 中的 evport、Linux 中的 epoll 和 macOS/FreeBSD 中的 kqueue,上述的这些函数都使用了内核内部的结构,并且能够服务几十万的文件描述符。$O(n)$,并且只能同时服务 1024 个文件描述符,所以一般并不会以 select 作为第一方案使用。总结
扫码加入技术交流群,不定时「送书」
推荐阅读:
如何解决MySQL order by limit语句的分页数据重复问题?
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
朕已阅 
评论