
为什么 Redis 单线程能达到百万+QPS?
高效的数据结构
多路复用 IO 模型
事件机制
1、高效的数据结构
2、多路复用 IO 模型
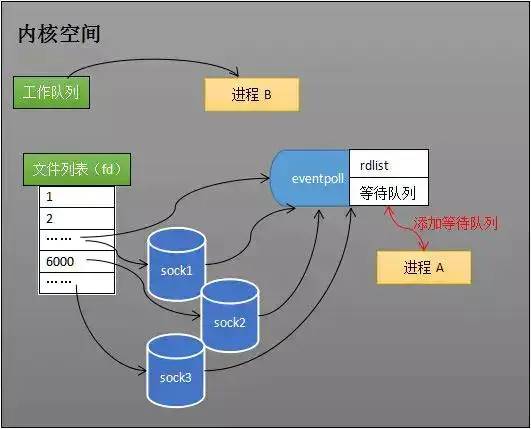
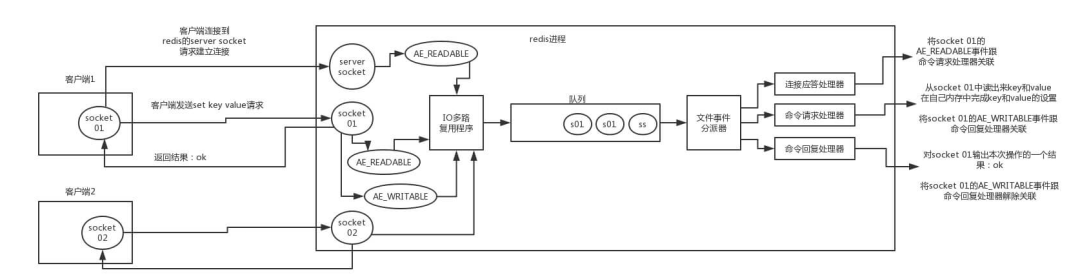
首先 redis 服务器运行,监听套接字的 AE_READABLE 事件处于监听的状态下,此时连接应答处理器工作
客户端与 Redis 服务器发起建立连接,监听套接字产生 AE_READABLE 事件,当 IO 多路复用程序监听到其准备就绪后,将该事件压入队列中,由文件事件分派器获取队列中的事件交于连接应答处理器工作处理,应答客户端建立连接成功,同时将客户端 socket 的 AE_READABLE 事件压入队列由文件事件分派器获取队列中的事件交命令请求处理器关联
客户端发送 set key value 请求,客户端 socket 的 AE_READABLE 事件,当 IO 多路复用程序监听到其准备就绪后,将该事件压入队列中,由文件事件分派器获取队列中的事件交于命令请求处理器关联处理
命令请求处理器关联处理完成后,需要响应客户端操作完成,此时将产生 socket 的 AE_WRITEABLE 事件压入队列,由文件事件分派器获取队列中的事件交于命令恢复处理器处理,返回操作结果,完成后将解除 AE_WRITEABLE 事件与命令恢复处理器的关联
reactor模式
为什么说存储的值不宜过大
评论