
【统计学习方法】 第2章 感知机代码实现(二)
点击上方“公众号”可订阅哦!
”只要你相信我,闭上眼就能到“
感知机的代码搞了一天才搞明白,做一个总结,我要坚持下去……
1
●
小标题
首先准备一条直线,在直线周围添加噪声,生成原始数据集,
import numpy as npimport randomimport matplotlib.pyplot as plt# 定义一个函数def random_point_nearby_line(weight , bias , size = 10):x_point = np.linspace(-1, 1, size)[:,np.newaxis]noise = np.random.normal(0, 0.5, x_point.shape)y_point = weight * x_point + bias + noiseinput_arr = np.hstack((x_point, y_point))return input_arr
# 直线的真正参数real_weight = 2real_bias = 1size = 100
# 生成输入的数据input_point = random_point_nearby_line(real_weight, real_bias, size)# 给数据打标签,在直线之上还是直线之下,above=1,below=-1label = np.sign(input_point[:,1] - (input_point[:,0] * real_weight + real_bias)).reshape((size, 1))
接下来是初始化参数,
# 初始化参数weight = [0, 0]bias = 0learning_rate = 0.1train_num = 1000
train_data = list(zip(input_point, label))训练
for i in range(train_num):train = random.choice(train_data)[x1,x2],y_label = train;y_predict = np.sign(weight[0]*x1 + weight[1]*x2 + bias)# print("train data:x:(%d, %d) y:%d ==>y_predict:%d" %(x1,x2,y_label,y_predict))if y_label*y_predict<=0:weight[0] = weight[0] + learning_rate*y_label*x1weight[1] = weight[1] + learning_rate*y_label*x2bias = bias + learning_rate*y_labelprint("update weight and bias:")print(weight[0], weight[1], bias)print("stop training :")print(weight[0], weight[1], bias)
输出:
stop training :[-1.28282828] [0.61316304] [-0.6]
可视化
for i in range(len(input_point)):if label[i] == 1:plt.plot(input_point[i][0], input_point[i][1], 'ro')else:plt.plot(input_point[i][0], input_point[i][1], 'bo')#plt.plot()x_1 = []x_2 = []for i in range(-1,3):x_1.append(i)x_2.append((-weight[0]*i-bias)/weight[1])plt.plot(x_1,x_2)plt.show()
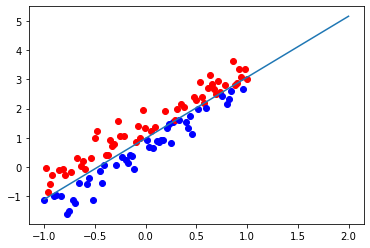
END
扫码关注
微信号|sdxx_rmbj
评论