
Kubernetes 锁机制设计与实现
资源锁是通过一个资源的CRUD操作,然后配合分布式锁的一些机制来完成,分布式环境中Leader节点的选举,今天我们来臆测下k8s里面是如何基于configMap来实现的吧
1. 面向终态的锁基础篇
在分布式系统中通常由各种各样的锁,我们先来看下,主流的锁里面有哪些共性,以及是如何进行设计的。
1.1 分布式系统中的锁
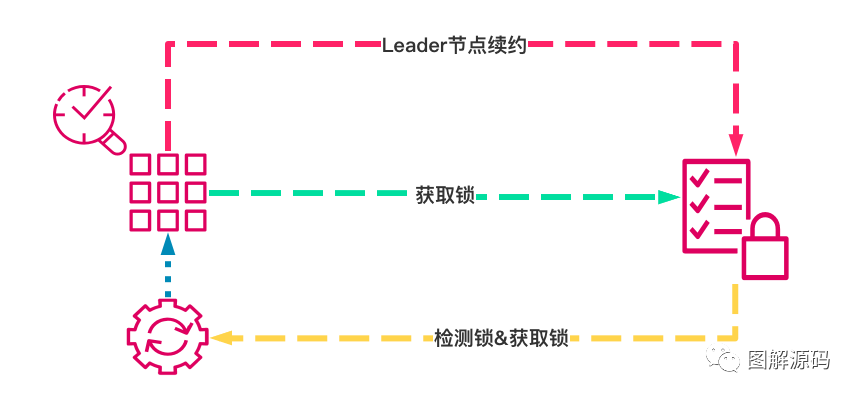 在分布式系统中锁有很多种实现方式:基于CP模型的、基于AP模型的,但是这些锁机制都有一些通用的设计原则,接下来我们先看下这部分
在分布式系统中锁有很多种实现方式:基于CP模型的、基于AP模型的,但是这些锁机制都有一些通用的设计原则,接下来我们先看下这部分
1.1.1 锁凭证
锁凭证主要来证明谁持有锁,不同系统里面的实现各不相同,比如在zookeeper中是临时顺序节点,而在redission中则是通过uuid+threadID组成,而k8s中则是LeaderElectionRecord, 通过该凭证来识别当前是哪个客户端加的锁
1.1.2 锁超时
当有leader节点持有锁之后,其余的节点就需要尝试竞争锁,在CP系统中通常会由服务端进行维护,即如果发现对应的节点没有心跳,则会进行节点的踢出,并且通过watch这种机制进行回调,而在AP系统中则需要客户端自己维护,比如redission里面的时间戳
1.1.3 时钟
在分布式系统中通常我们无法保证各个节点的物理时钟完全一致,通常就会有一个逻辑时钟的概念,在很多系统中比如raft和zab中其实就是一个递增的全局计数器,但是在redission中则是通过物理时钟,即需要保证大家的物理时钟尽可能同步,不能超过锁超时的时间
1.2 网络分区问题
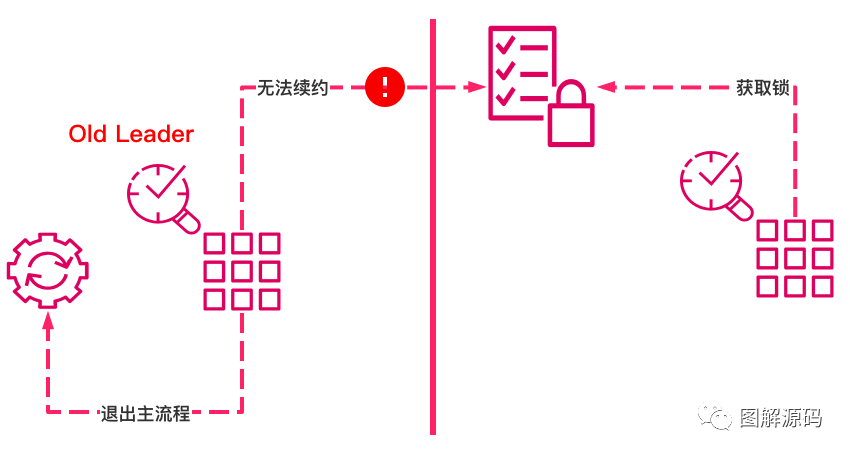 无论是CP还是AP,在分布式系统中通常我们都要保证P即分区可用性,那如果持有锁的Leader节点发生网络分区的情况,则需要一种保护机制,即Leader节点需要主动退出
无论是CP还是AP,在分布式系统中通常我们都要保证P即分区可用性,那如果持有锁的Leader节点发生网络分区的情况,则需要一种保护机制,即Leader节点需要主动退出
在zookeeper中因为leader节点需要通过session来进行心跳的维护,如果说对应的leader节点发生分区,则session就无法进行心跳的发生,就会退出,就需要通知我们的主流程来进行退出清理工作
1.3 资源锁的实现机制
资源锁其实就是可以通过操作一个资源(顺序一致性),借助前面说的锁的思想来实现分布式锁,其首先核心流程如下:
通过资源对象来存储锁凭证信息
即将标识当前Leader节点的信息放入到对应的凭证里面,并尝试进行锁竞争,进行锁的获取的尝试
锁超时
k8s的锁超时的机制比较有趣,即他并不关心你的逻辑时钟,而是以本地时钟为准,即每个节点会存储观测到leader节点变更的时间,然后根据本地的锁超时时间来检测,是否重新发起leader的竞争
2. 核心源码剖析
因为篇幅原因这里只介绍基于configMap的resourceLock, 其他的都大同小异
2.1 LeaderElectionRecord
在我的理解上这个数结构的设计,才是真正的那把锁(就好像生活中我们可以随便买把锁,锁各种门)。通过这个锁屏蔽底层的各种锁实现系统的实现细节,但注意这把锁并不是严格的分布式互斥锁
2.1.1 数据结构
在锁的实现中,数据主要分为三类:身份凭证、时间戳、全局计数器,然后我们依次来看猜下对应的设计思路
身份凭证:HolderIdentity
身份凭证主要是用于标识一个节点信息,在一些分布式协调系统中通常都是系统自带的机制,比如zookeeper中的session, 在此处资源锁的场景下,主要是为了用于后续流程里验证当前节点是否获取到锁
时间戳:LeaseDurationSeconds、AcquireTime、RenewTime
因为之前说的时间同步的问题,这里的时间相关的主要是用于leader节点触发节点变更来使用(Lease类型也在使用),非Leader节点则根据当前记录是否变更来检测leader节点是否存活
LeaderTransitions
计数器主要就是通过计数来记录leader节点切换的次数
2.2 ConfigMapLock
所谓的资源锁其实就是通过创建一个ConfigMap实例来保存我们的锁信息,并通过这个实例信息的维护,来实现锁的竞争和释放
2.2.1 创建锁
通过利用etcd的幂等性操作,可以保证同时只会有一个leader节点进行锁创建成功,并且通过Annotations来提交上面说的LeaderElectionRecord来进行锁的提交
2.2.2 获取锁
2.2.3 更新锁
2.3 LeaderElector
LeaderElector的核心流程分为三部分:竞争锁、超时检测、心跳维护,首先所有节点都会进行资源锁的竞争,但是最终只会有一个节点成为Leader节点, 然后核心流程就会按照角色分成两个主流程, 让我们一起来看下其实现
2.3.1 核心流程
如果节点没有acquire成功则会一直进行尝试,直至取消或者竞选成功,而leader节点则会执行成为leader节点的回调(补充基于leader的zookeeper的实现机制)
2.3.2 锁的续约
如果竞选为leader节点,则就需要进行锁的续约操作,就是通过调用上面提到的更新锁的操作来,周期性的更新锁记录信息即LeaderElectionRecord,从而达到续约的目标
2.3.3 锁的释放
锁的释放则比较好玩,就是更新对应的资源,去掉annotations里面的信息,这样在获取锁的时候,因为检测到当前资源没有被任何凭证信息,就会尝试进行竞选
2.3.4 锁的竞争
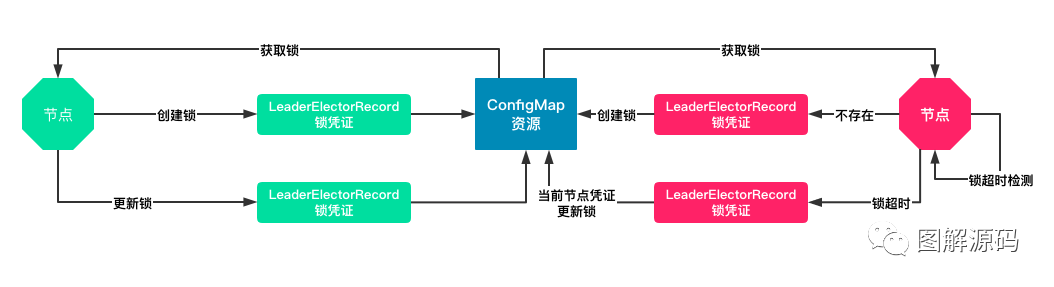 锁的竞争整体分为四个部分: 1)获取锁 2)创建锁 3)检测锁 4)更新锁,下面来依次看下对应的实现
锁的竞争整体分为四个部分: 1)获取锁 2)创建锁 3)检测锁 4)更新锁,下面来依次看下对应的实现
获取锁
首先会尝试获取对应的锁,在获取锁中会检测对应的annotations中是否存在,如果不存在则oldLeaderElectionRecord就为空,即当前资源锁没有被人持有
创建锁
如果检测到对应的锁不存在,则就会直接进行锁的创建,如果创建成功则表明当前节点获取锁,则就成为leader,执行leader的回调逻辑
检查锁
在k8s里面并没有使用逻辑时钟而是使用本地时间,通过对比每次锁凭证是否更新,来进行本地observedTime的更新,如果leader没有在LeaseDuration内来更新对应的锁凭证信息,则当前节点就会尝试成为leader
同时这里还会保障最终的一致性锁,因为后续的renew其实也是走的这个逻辑,如果说当前节点最开始持有锁,但是被别的节点抢占,则当前节点会主动让出锁
更新锁
核心逻辑其实就是Lock.Update这个地方,设计的比较有意思,不同于强一致性的锁,在k8s中我们可以同时有多个节点都走到这里,但是因为更新etcd是一个原子的操作,最终只会有一个节点更新成功,那如何保证最终的锁的语义呢,其实就要配合上面的检测锁,这样就可以实现一个面向终态的最终的锁机制
3. 疑问
回过来看锁是因为最近在做系统设计的时候,想到的一个问题。在PAAS系统中通常会有N多的Operator,那在一些冲突的场景该如何解决呢?比如扩缩容、发布、容灾这几个控制器,如果要操作同一个app下面的pod该如何被调度呢?
其实我理解这个流程中是无法做到各种完美cover各种异常冲突的,但是我们可以玩另外一种有意思的事情,比如我们可以加一个保护状态,因为对生产稳定压倒一起。即对应的控制器,关注当前的状态是否处于稳定状态,如果是非稳定状态,则就应该自身冻结,等当前应用处于非保护状态再进行操作,保证SLA的同时也不影响各种好玩的操作
云原生学习笔记地址: https://www.yuque.com/baxiaoshi/tyado3
 点击屏末 | 阅读原文 | 学习云原生
点击屏末 | 阅读原文 | 学习云原生