
聊聊布隆过滤器

前言
布隆过滤器作为一个精巧且实用的数据结构,对于后端程序员来讲,学习和理解布隆过滤器有很大的必要性。希望通过这篇文章让更多人了解布隆过滤器的原理,并且会实际去使用它!
什么是布隆过滤器?
布隆过滤器 (Bloom Filter)是由 Burton Howard Bloom 于 1970 年提出,我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。而且,存放在布隆过滤器的数据不容易删除。
Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
 位数组
位数组总结:一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。
布隆过滤器使用场景
判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,上亿)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤(判断一个邮件地址是否在垃圾邮件列表中)、黑名单功能(判断一个IP地址或手机号码是否在黑名单中)等等。
网页爬虫对URL去重,避免爬取相同的 URL 地址。
比如用户日常刷新闻,每次推荐给该用户的内容不能重复,过滤已经看过的内容。
以上场景都需要判断给定数据是否存在,因此布隆过滤器主要是为了解决海量数据的存在性问题。
布隆过滤器的原理介绍
当一个元素加入布隆过滤器中的时候,会进行如下操作:
使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
根据得到的哈希值,在位数组中把对应下标的值置为 1。
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
对给定元素再次进行相同的哈希计算;
得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
Bloom Filter 的简单原理图如下:
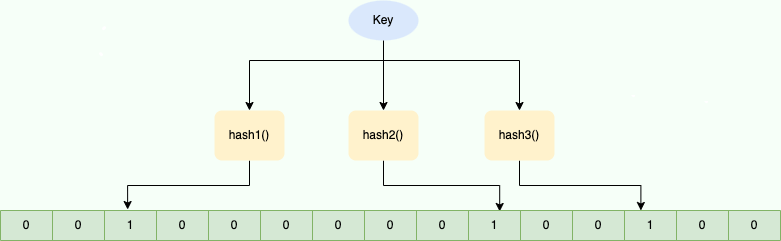 Bloom Filter 的简单原理示意图
Bloom Filter 的简单原理示意图如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。
综上,我们可以得出:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
如何实现布隆过滤器
Guava 实现
Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要自己去实现一个布隆过滤器。
首先我们需要在项目中引入 Guava 的依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.0-jre</version>
</dependency>
实际使用如下:
我们创建了一个最多存放 最多 1500 个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之(0.01)
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(),
1500,
0.01);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
在我们的示例中,当 mightContain() 方法返回 true 时,我们可以 99%确定该元素在过滤器中,当过滤器返回 false 时,我们可以 100%确定该元素不存在于过滤器中。
Guava 提供的布隆过滤器的实现还是很不错的(想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。
Redis 中的布隆过滤器
Redis v4.0 之后有了 Module(模块/插件)功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 ,使用户可以根据需要额外集成一些实用功能。
详情可以查看官网:https://redis.io/resources/modules
官网推荐了 RedisBloom 作为 Redis 布隆过滤器的 Module,其他还有:
redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
pyreBloom(Python 中的快速 Redis 布隆过滤器):https://github.com/seomoz/pyreBloom
......
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
链接:https://zhuanlan.zhihu.com/p/638609566
(版权归原作者所有,侵删)