
Elasticsearch从入门到放弃:浅谈算分
今天来聊一个 Elasticsearch 的另一个关键概念——相关性算分。在查询 API 的结果中,我们经常会看到 _score 这个字段,它就是用来表示相关性算分的字段,而相关性就是描述一个文档和查询语句的匹配程度。
打分的本质其实就是排序,Elasticsearch 会把最符合用户需求的文档排在最前面。
在 Elasticsearch 5.0 之前,相关性算分算法采用的是 TF-IDF 算法,而在5.0之后采用的是 BM 25 算法。听到这也许你会比较疑惑,想知道这两个算法到底是怎么样的。别急,下面我们来具体了解一下。
TF-IDF
首先来看字面意思,TF 是 Term Frequency 的缩写,也就是词频。IDF 是 Inverse Document Frequency 的缩写,也就是逆文档频率。
词频
词频比较好理解,就是要搜索的目标单词在文档中出现的频率。算式为检索词出现的次数除以文档的总字数。最简单的相关性算法就是将检索词进行分词后对他们的词频进行相加。例如,我要搜索“我的算法”,其相关性就可以表示为:
TF(我) + TF(的) + TF(算法)
但这里也有些问题,像“的”这样的词,虽然出现的次数很多,但是对贡献的相关度几乎没有用处。所以在考虑相关度时不应该考虑他们,对于这类词,我们统称为 Stop Word。
逆文档频率
聊完了 TF,我们再来看看 IDF,在了解逆文档频率之前,首先需要知道什么是文档频率,也就是 DF。
DF 其实是检索词在所有文档中出现的频率。例如,“我”在较多的文档中出现,“的”在非常多的文档中都会出现,而“算法”只会在较少的文档中出现。这就是文档频率,那逆文档频率,简单理解就是:
log(全部文档数 / 检索词出现过的文档总数)
针对上面的例子,我们将它更具体的呈现一下。假设我们文档总数为1亿,出现“我”字的文档有5000万,那么它的 IDF 就是 log(2) = 1 。“的”在1亿文档中都有出现,IDF 就是 log(1) = 0,而算法只在20万个文档中出现,那么它的 IDF 就是 log(500) ,大约是8.96。
由此可见,IDF 越大的单词越重要。
好了,现在各位 TF 和 IDF 应该都有一定的了解了,那么 TF-IDF 本质上就是对 TF 进行一个加权求和。
TF(我) * IDF(我) + TF(的) * IDF(的) + TF(算法) * IDF(算法)
BM 25
BM25可以看作是对 TF-IDF 的一个优化,其优化的效果是,当 TF 无限增加时, TF-IDF 的结果会随之增加,而 BM 25 的结果会趋近于一个数值。这就限制了一个 term 对于检索词整体相关性的影响。
BM25算法的公式如下:
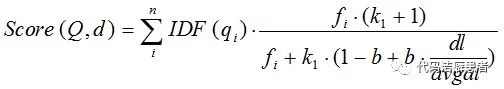
想要详细了解BM25算法的同学可以参考这篇文章BM25 The Next Generation of Lucene Relevance。
Explain API
如果想要了解一个查询是如何进行打分的,我们可以使用 Elasticsearch 提供的 Explain API,其用法非常简单,只需要在参数中增加
"explain": true
也可以在 path 中增加 _explain,例如:
curl -X GET "localhost:9200/my-index-000001/_explain/0?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"match" : { "message" : "elasticsearch" }
}
}
'
这时,返回结果中就会有一个 explanation 字段,用来描述具体的算分过程。
小结
关于 Elasticsearch 的算分,相信各位也有一个初步的认识了,如果感兴趣的话也可以自己进行更加深入的研究,也欢迎各位和我一起交流。