
Flink生产实时监控和预警配置解析

Hi,我是王知无,一个大数据领域的原创作者。
放心关注我,获取更多行业的一手消息。
在实际的Flink 项目中,如何观察Flink的性能,如何监控Flink的运行状态,如何设置报警策略?下面简单讲下我的经验吧。
一、Flink webUI
首先聊下Flink webUI。如下图所示:
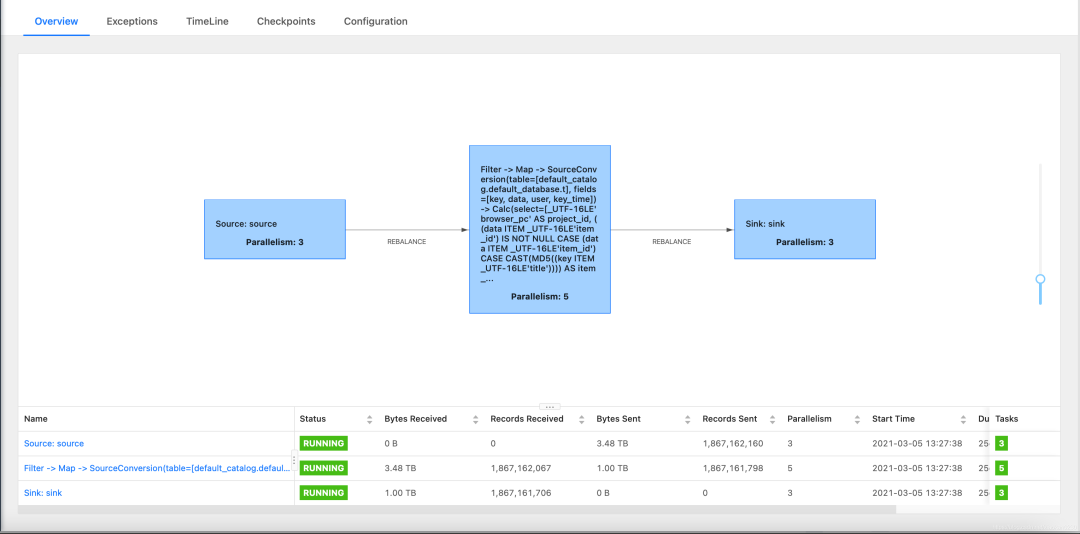
如果是本地调试模式,默认是不开启webui的。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
上面的初始化方式,本地调试默认不开启webui。
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
需要使用上面这种方式才能在本地调试的时候打开webui。当然了,也需要在pom文件中添加依赖
org.apache.flink
flink-runtime-web_2.11
${flink.version}
如果你是on yarn 模式,则必须使用第一种初始化方式,on yarn 默认可以查看webui。
下面是一个读取kafka数据,通过Flink 处理后,再写入目标kafka的任务。
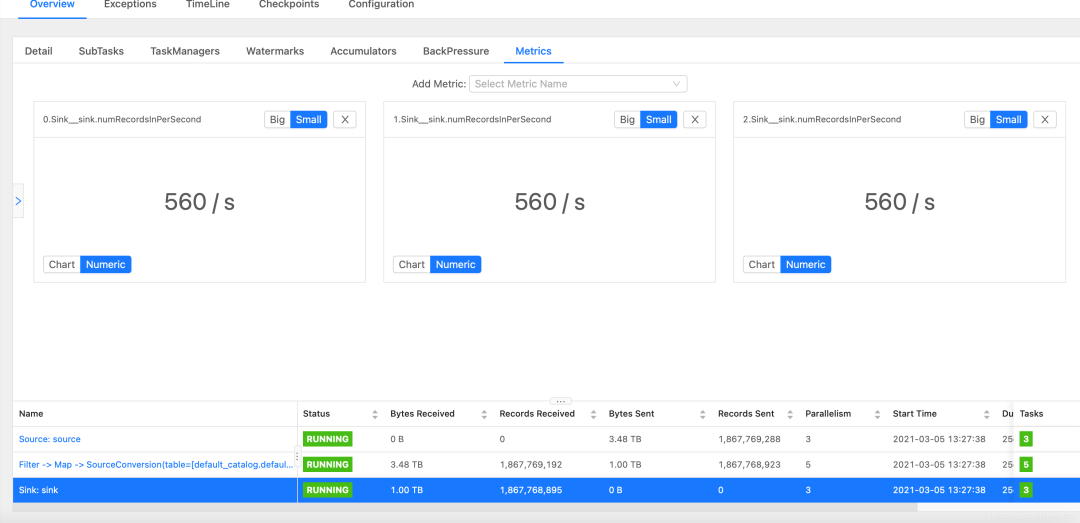
如上图所示,点击sink,在metrics中选择Sink__sink.numRecordsInPerSecond。这里有几个并行度,就需要全部选出来,如果你设置了50个并行度,那么就要选50次。
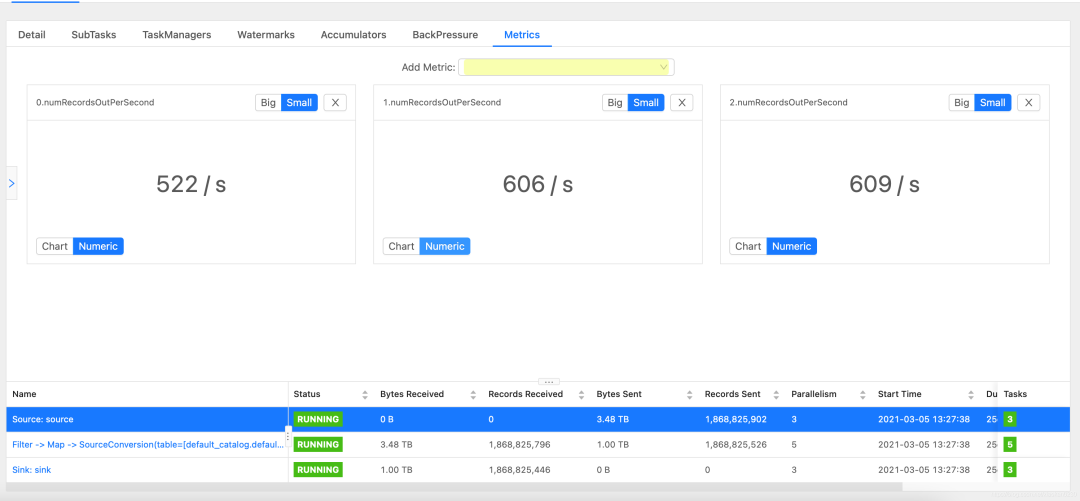
source也是同样操作
那么,从上图可知,该任务sink总速度为560*3=1680 条/s,source总速度为1737 条/s。基本相等
那么接下来,我们怎么判定速度是否正常呢?
我们可以借助kafka-eagle查看kafka topic的写入速度。
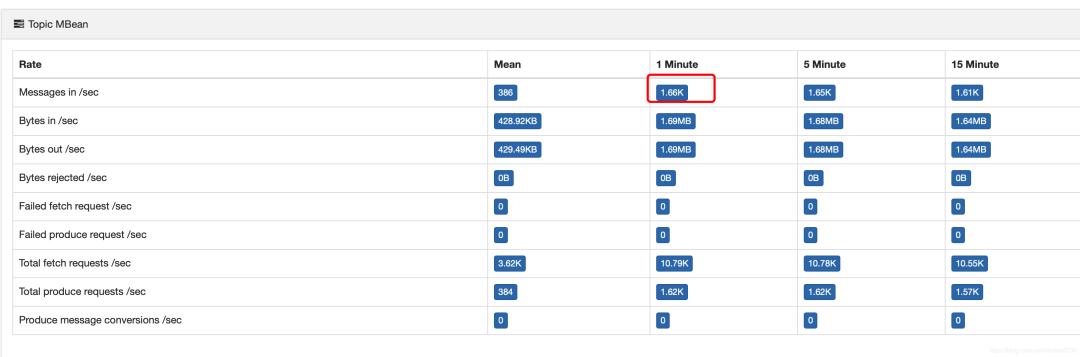
可以看到kafka的写入速度是1.66k/s,而我们的业务逻辑,输入和输出是1:1,所以,flink的写入速度和kafka的生产速度保持一直.
这里如果看到kafka的生产速度明显高于flink的source和sink速度,则基本可以断定,Flink已经产生反压,并且性能不符合线上要求。
那么是否kafka写入速度和Flink的消费速度一致,就表示万事大吉了呢?也不一定,我们需要通过FlinkWebui直接观察反压的情况。

如果和上图一样Ratio是0,并且status是ok,那么说明一切正常。
如果此时出现反压,说明Flink的消费速度,只能勉强等于日常的生产速度,并且此时有积压的数据。这种情况会在补数据的时候会比较明显,如果一个任务的极限性能仅仅等于或略大于生产日常的性能,则出现这种情况的概率会很高,
所以,一般来说,在Flink任务上线前,我们需要测试极限性能,一般要求至少3倍的日常速度,做到10倍以上,是最好的。
下面是一个读取kakfa 数据,处理后写mysql的任务。
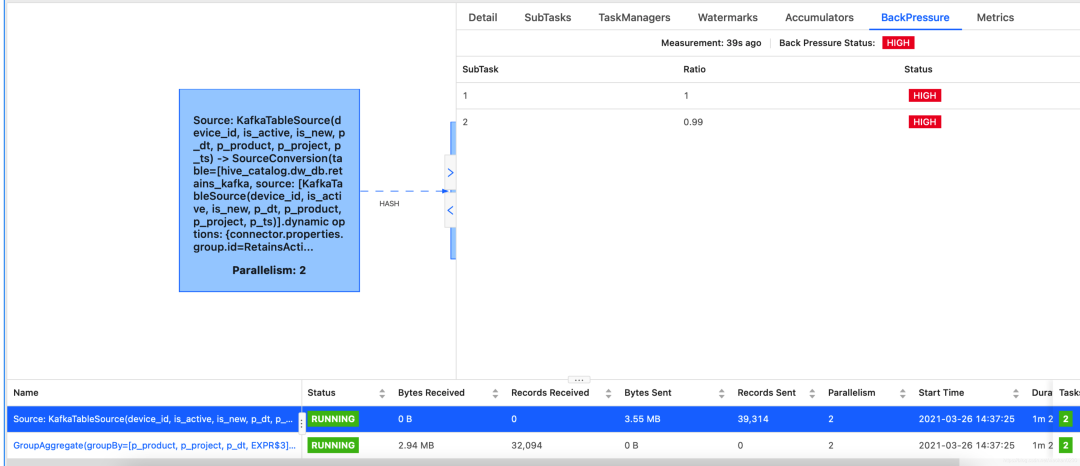
上图说明下游产生了反压,但是由于下游有group by 等一系列操作,我们无法确定瓶颈出在了哪里。如果需要查看具体哪一步产生了反压,我们可以通过如下设置来禁止合并。
env.disableOperatorChaining();

如上图所示,将所有子任务全部采集反压信息。从最上的子任务往下数,第一个反压为绿色的就是罪魁祸首。如上图所示,FlatMap,是红色,sink为绿色,说明反压在了sink,也就是说mysql的写入速度,不能满足我们的需求,导致上游Flink处理全部被限制了速度。
当然,罪魁祸首不一定只有一个,mysql的写入性能解决后,还有可能反压在其他阶段,但是我们通过这种方式,可以一步步定位问题,解决问题,有针对性的优化问题,而不是像某些领导赏识的同事一样,只知道增加并行度,最终极大增加了集群压力,一个任务动辄几百G,成为集群不稳定的因素之一,完了还甩锅给其他人,那就没意思了。
二、Kafka 消费 监控
我们知道,Flink在 打checkpoint时才向kafka集群提交offset消费信息的,所以如果仅仅站在kafka lag 的角度,我们看到的消费延迟是锯齿状的图形,大致长这样

上图是一个checkpoint为3min,并且flink没有反压的kafka lag监控图。
在脚本中我们可以通过如下命令获取kafka总lag
lag=`kafka/kafka_2.11-2.0.1/bin/kafka-consumer-groups.sh --bootstrap-server *.*.*.*:6667 --describe --group "$2" |grep "$3" 2>/dev/null |grep -v LAG|awk '{sum+=$5}END
这时候我们需要引入一个概念,Flink消费虚拟速度F0。设flink checkpoint间隔为t
F0=lag/t
例如,最高峰时,kafka 的lag 为30000 ,
F0=30000/60/3=167
Flink虚拟消费速度在最高峰时约等于167条/s。
设Flink 真实消费速度为F1.(通过webui 直接获得),预警倍数为m
再设预警消费速度为F2,F2=F1*m
例如Flink 任务日常的消费速度为167/s,峰值为250/s,我们设置预警倍数为2.那么当F0>F2时,我们触发报警。
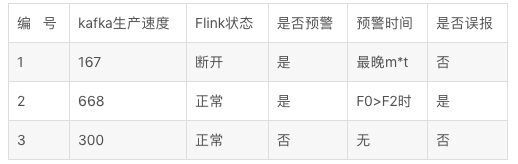
可以看到,仅仅通过Kafka lan监控Flink任务状态 ,在出现高峰时,可能存在误报的情况,但是如果将预警倍数设置太高,又可能降低Flink预警的及时性。实际情况中,我们需要根据业务情况,设置合理的m和t,在允许极少误报的情况下,做到实时任务的故障对用户无感知,当然,前提是笔记本随身携带。。。
三、yarn 监控
由于我们都是per job 模式,所以在yarn上都会有唯一名字,在脚本中可以通过如下方式获得num。
num=`yarn application -list | grep "FlinkJobName" | wc -l`
如果num小于1,那么就说明Flink任务挂了,简单直接。
但是也有一种情况,那就是集群yarn挂了。由于我们公司的集群建设做的很差,经常出现这种情况,所以在监控脚本中,不能监控到num=0就直接启动Flink,这样可能会导致下游数据翻倍,而是应该电话通知,人工确认状态后,再手动启动Flink任务。
例如,可以和kafka lag 监控综合来看,如果kafka lag一切正常,yarn 查不到任务信息,那大概率是说明yarn 挂了,但是Flink任务还在正常运行。
总结:
通过yarn,kafka,flink web ui 综合判断Flink任务健康状态。
通过设置合理的m和t做到最少的误报率和最高的SLA
Flink 程序质量是第一位,极限性能至少在高峰性能2倍以上,监控只是辅助,Flink 优化不到位,再多的监控也没法保证高SLA。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)