
【CV】 何凯明大神新作MAE | CVPR2022最佳论文候选
文章转自:微信公众号【机器学习炼丹术】 笔记作者:炼丹兄(已授权转载) 联系方式:微信cyx645016617 论文题目:“Masked Autoencoders Are Scalable Vision Learners”
0摘要

本文证明了蒙面自动编码器(MAE)是一种可扩展的计算机视觉自监督学习器。我们的MAE方法很简单:我们屏蔽输入图像的随机补丁并重建丢失的像素。
这样的设计基于两个core:
我们开发了一种非对称编码器-解码器体系结构,其中的编码器仅在可见的补丁子集上运行(不带掩码),以及一个轻量级解码器,该解码器从潜在表示和掩码令牌重建原始图像。 其次,我们发现掩蔽高比例的输入图像(例如75%)会产生一项不平凡且有意义的自我监督任务。将这两种设计结合起来,使我们能够高效地训练大型模型:我们加快训练速度(3倍或更多)并提高准确性。
1 方法
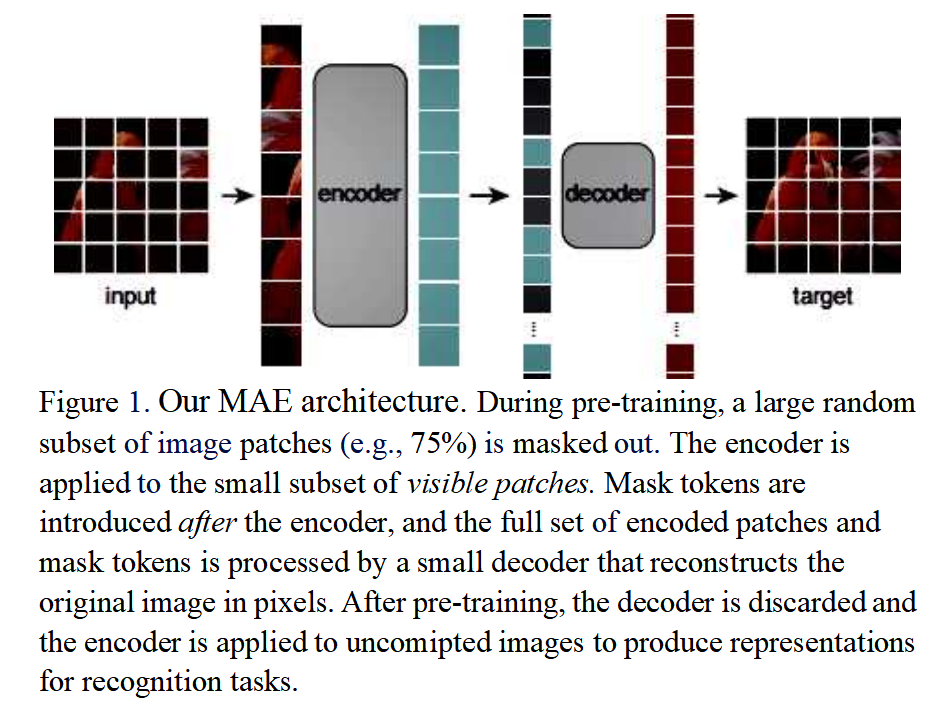
从图片中可以看出,其实模型非常简单:
是一个类似于VIT的transformer结构,图像被分成patch,然后其中模型只能看到其中的少部分(25%)的patch,剩下的75%的patch是看不到的; encoder的输入是可以看到的25%的patch加上这25%的位置掩码; 之后通过decoder,来将25%的patches信息还原出来整张图片,来做重建。 在预训练之后,解码器被丢弃,编码器被应用于未损坏的图像以产生识别任务的表示。
2 代码部分-第一步
因为简单,所以直接看代码。代码是由某位大佬自行复现,而非官方!
def pretrain_mae_small_patch16_224(pretrained=False, **kwargs):
model = PretrainVisionTransformer(
img_size=224,
patch_size=16,
encoder_embed_dim=384,
encoder_depth=12,
encoder_num_heads=6,
encoder_num_classes=0,
decoder_num_classes=768,
decoder_embed_dim=192,
decoder_depth=4,
decoder_num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.load(
kwargs["init_ckpt"], map_location="cpu"
)
model.load_state_dict(checkpoint["model"])
return model
从代码中的,patch_size,encoder_embed_dim这些参数,不难理解,这个PretrainVisionTransformer是一个经典的VIT的transformer结构(先猜测,后验证)。
3 代码部分-第二步
class PretrainVisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self,
img_size=224,
patch_size=16,
encoder_in_chans=3,
encoder_num_classes=0,
encoder_embed_dim=768,
encoder_depth=12,
encoder_num_heads=12,
decoder_num_classes=768,
decoder_embed_dim=512,
decoder_depth=8,
decoder_num_heads=8,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
norm_layer=nn.LayerNorm,
init_values=0.,
use_learnable_pos_emb=False,
num_classes=0, # avoid the error from create_fn in timm
in_chans=0, # avoid the error from create_fn in timm
):
super().__init__()
self.encoder = PretrainVisionTransformerEncoder(
img_size=img_size,
patch_size=patch_size,
in_chans=encoder_in_chans,
num_classes=encoder_num_classes,
embed_dim=encoder_embed_dim,
depth=encoder_depth,
num_heads=encoder_num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop_rate=drop_rate,
attn_drop_rate=attn_drop_rate,
drop_path_rate=drop_path_rate,
norm_layer=norm_layer,
init_values=init_values,
use_learnable_pos_emb=use_learnable_pos_emb)
self.decoder = PretrainVisionTransformerDecoder(
patch_size=patch_size,
num_patches=self.encoder.patch_embed.num_patches,
num_classes=decoder_num_classes,
embed_dim=decoder_embed_dim,
depth=decoder_depth,
num_heads=decoder_num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop_rate=drop_rate,
attn_drop_rate=attn_drop_rate,
drop_path_rate=drop_path_rate,
norm_layer=norm_layer,
init_values=init_values)
self.encoder_to_decoder = nn.Linear(encoder_embed_dim, decoder_embed_dim, bias=False)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.pos_embed = get_sinusoid_encoding_table(self.encoder.patch_embed.num_patches, decoder_embed_dim)
trunc_normal_(self.mask_token, std=.02)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_num_layers(self):
return len(self.blocks)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token', 'mask_token'}
def forward(self, x, mask):
x_vis = self.encoder(x, mask) # [B, N_vis, C_e]
x_vis = self.encoder_to_decoder(x_vis) # [B, N_vis, C_d]
B, N, C = x_vis.shape
# we don't unshuffle the correct visible token order,
# but shuffle the pos embedding accorddingly.
expand_pos_embed = self.pos_embed.expand(B, -1, -1).type_as(x).to(x.device).clone().detach()
pos_emd_vis = expand_pos_embed[~mask].reshape(B, -1, C)
pos_emd_mask = expand_pos_embed[mask].reshape(B, -1, C)
x_full = torch.cat([x_vis + pos_emd_vis, self.mask_token + pos_emd_mask], dim=1)
x = self.decoder(x_full, pos_emd_mask.shape[1]) # [B, N_mask, 3 * 16 * 16]
return x
整体来看,是由Encoder和Decoder组成的。我们来把参数罗列一下:
img_size=224patch_size=16encoder_in_chans=3encoder_num_classes=0encoder_embed_dim=768encoder_depth=12encoder_num_heads=12decoder_num_classes=768decoder_embed_dim=512decoder_depth=8decoder_num_heads=8mlp_ratio=4.qkv_bias=Falseqk_scale=Nonedrop_rate=0.attn_drop_rate=0.drop_path_rate=0.norm_layer=nn.LayerNorminit_values=0.use_learnable_pos_emb=Falsenum_classes=0 # avoid the error from create_fn in timmin_chans=0, # avoid the error from create_fn in timm
4 代码部分-encoder
class PretrainVisionTransformerEncoder(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=0, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, init_values=None,
use_learnable_pos_emb=False):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
# TODO: Add the cls token
# self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
if use_learnable_pos_emb:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
else:
# sine-cosine positional embeddings
self.pos_embed = get_sinusoid_encoding_table(num_patches, embed_dim)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
init_values=init_values)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
if use_learnable_pos_emb:
trunc_normal_(self.pos_embed, std=.02)
# trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_num_layers(self):
return len(self.blocks)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x, mask):
x = self.patch_embed(x)
# cls_tokens = self.cls_token.expand(batch_size, -1, -1)
# x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed.type_as(x).to(x.device).clone().detach()
B, _, C = x.shape
x_vis = x[~mask].reshape(B, -1, C) # ~mask means visible
for blk in self.blocks:
x_vis = blk(x_vis)
x_vis = self.norm(x_vis)
return x_vis
def forward(self, x, mask):
x = self.forward_features(x, mask)
x = self.head(x)
return x
构建Encoder中,用到了这几个模块:
self.patch_embed:将图像patch化 depth个堆叠的Block,transformer的特征提取部分 self.head:这里是一个identity层,无意义。
5 代码部分-patch_embed
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.patch_shape = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x, **kwargs):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
这里面的代码可以看到,其实只是包含一个self.proj(x)这一个卷积层罢了,我做了一个简单的demo研究patchembed模块是如何影响一个图片的形状的:
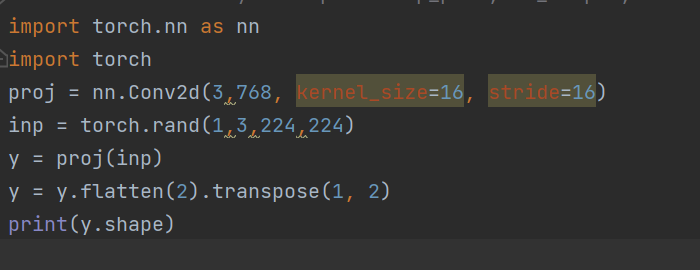
输入是一个1x3x224x224的特征图,输出的y的形状为:

这里我理解了这个过程以及两个参数的含义:
196表示是一张图片的patch的数量,224的输入,16是patch的size,所以一个图片有(224/16)的平方个patches,也就是196个patches; 每一个patch都被卷积编码成了768维度的向量。768对应超参数 embed_dim这里面kernel_size和stride都设置成和patch尺度相同,其实是在数学上完全等价于,对一个patch的所有元素做了一层的全连接层。一个patch包含14x14个像素,也就是196 。这样的卷积层等价于一个196到768的全连接层。
6 代码部分-Block
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., init_values=None, act_layer=nn.GELU, norm_layer=nn.LayerNorm,
attn_head_dim=None):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, attn_head_dim=attn_head_dim)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
if init_values > 0:
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
else:
self.gamma_1, self.gamma_2 = None, None
def forward(self, x):
if self.gamma_1 is None:
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x
这个Block里面包含了三个模块,Attention,Mlp和DropPath.
输入的x先经过Layer norm做归一化,然后放到Attention当中,然后是DropPath,然后是Layer norm归一化,然后时Mlp然后是DropPath。
6 代码部分-Attention
class Attention(nn.Module):
def __init__(
self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0.,
proj_drop=0., attn_head_dim=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
if attn_head_dim is not None:
head_dim = attn_head_dim
all_head_dim = head_dim * self.num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, all_head_dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(all_head_dim))
self.v_bias = nn.Parameter(torch.zeros(all_head_dim))
else:
self.q_bias = None
self.v_bias = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(all_head_dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, torch.zeros_like(self.v_bias, requires_grad=False), self.v_bias))
# qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
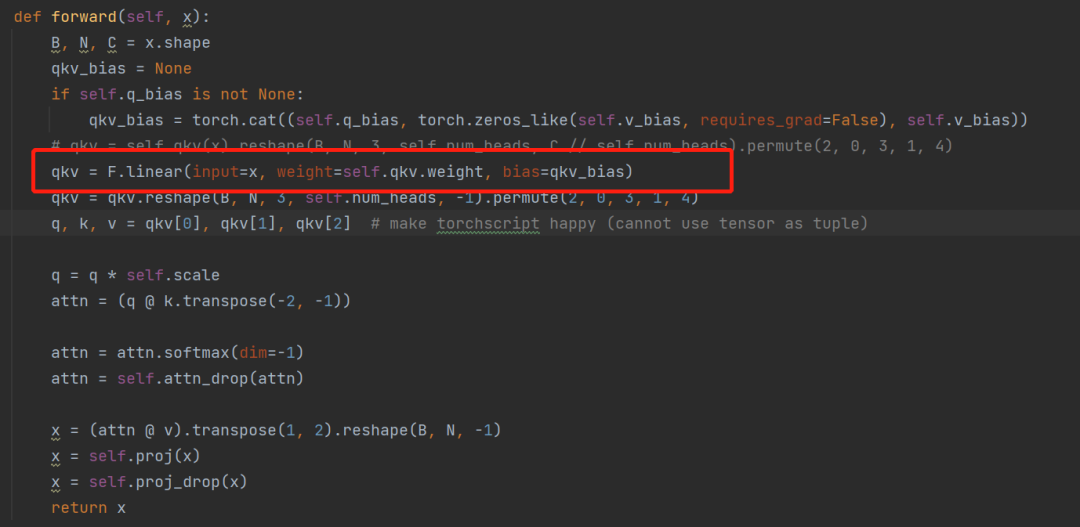
通过这一行全连接层,将输入768个特征,扩展到2304维度,分别对应q,k,v三个变量。
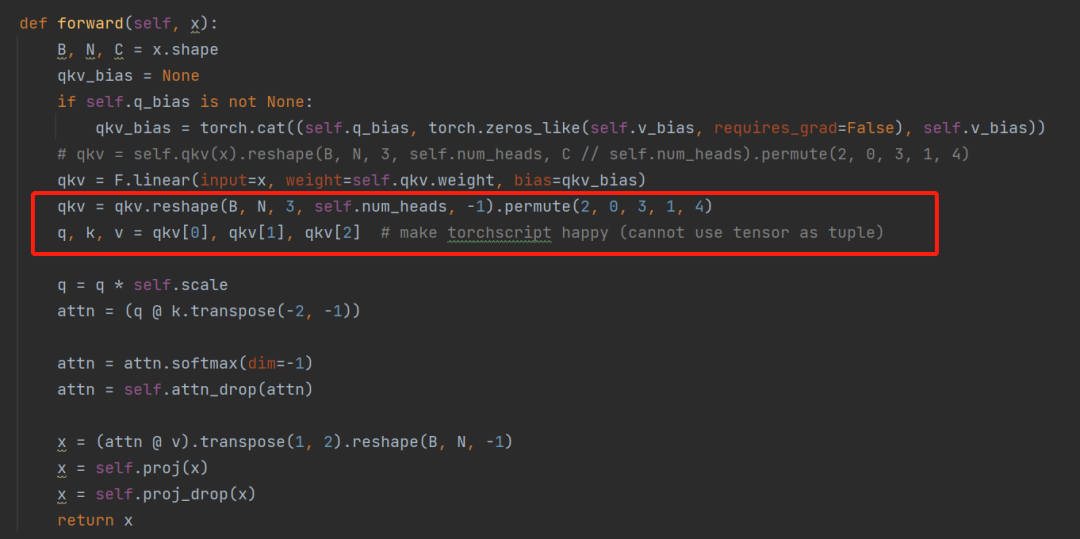 通过reshape,将【batch,196,2304】reshape成【1,196,3,8,96】,然后转置变成【3,1,8,196,96】.这个3,刚好分配给qkv。然后经过两次矩阵的乘法,最终输出还是[batch,196,768]维度。
通过reshape,将【batch,196,2304】reshape成【1,196,3,8,96】,然后转置变成【3,1,8,196,96】.这个3,刚好分配给qkv。然后经过两次矩阵的乘法,最终输出还是[batch,196,768]维度。
【总结】:Attention其实就是特征提取模块,输入是[batch,196,768],输出也是[batch,196,768].
7 代码部分-Mlp
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
# x = self.drop(x)
# commit this for the orignal BERT implement
x = self.fc2(x)
x = self.drop(x)
return x
这个MLP就是两层全连接层,将768放大到768x4的维度,然后再变成768.
7 代码部分-Decode
class PretrainVisionTransformerDecoder(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, patch_size=16, num_classes=768, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, init_values=None, num_patches=196,
):
super().__init__()
self.num_classes = num_classes
assert num_classes == 3 * patch_size ** 2
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_size = patch_size
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
init_values=init_values)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_num_layers(self):
return len(self.blocks)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward(self, x, return_token_num):
for blk in self.blocks:
x = blk(x)
if return_token_num > 0:
x = self.head(self.norm(x[:, -return_token_num:])) # only return the mask tokens predict pixels
else:
x = self.head(self.norm(x)) # [B, N, 3*16^2]
return x
不过总的来说,这个代码复现和论文中的MAE还有有不同的地方。decoder部分有问题。之后自己再修正一下。
我觉得大致的问题在于,这个代码中,encoder之后,decoder之前,缺少一个对于图像位置的还原。就是下图中的红框的步骤:

不过这一步骤的有无,并不会影响模型的训练,只是为了生成完整的重建图形。
往期精彩回顾 本站qq群955171419,加入微信群请扫码: