
用Python来找合适的妹子
点击 “凹凸域”,马上关注
真爱,请置顶或星标
 文章转载自:公众号python绿色通道
文章转载自:公众号python绿色通道
用Python做有趣的事情
先上效果图吧,no pic say bird!
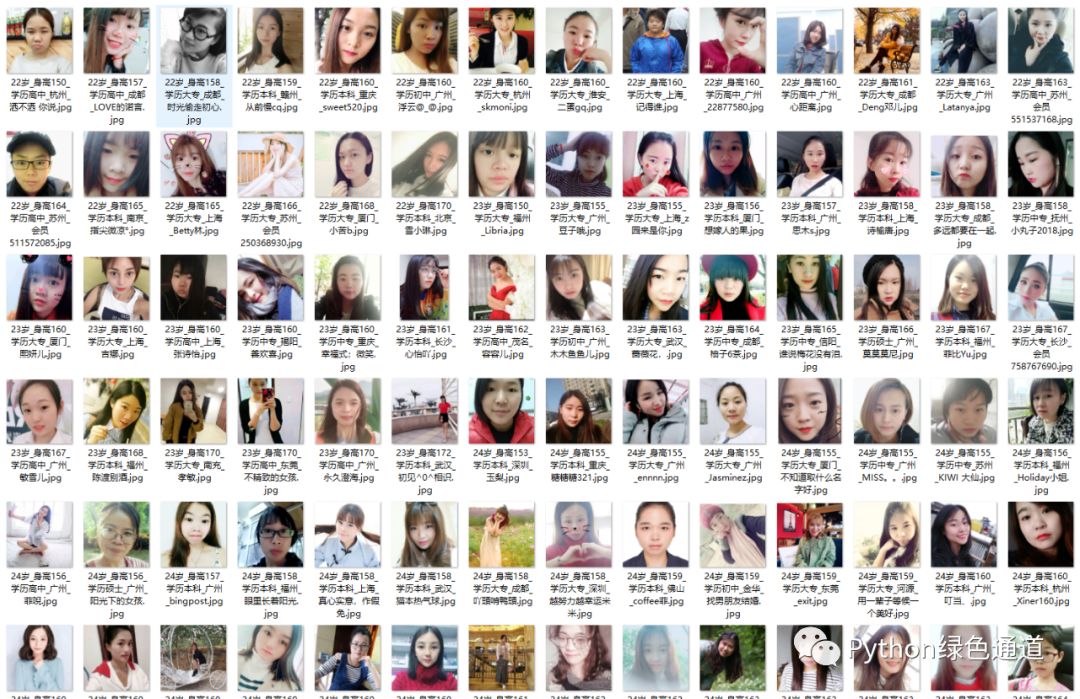
古人云:知己知彼,百战不殆. 好好去了解一下妹子们的内心想法,早日脱单!
这次我在一个某知名婚恋网站,抓取了一些数据,对她们的内心读白进行分析.
我这次筛选条件:女性,年龄20-30,学历本科,就这些条件.
3000条妹子内心读白词云如下:

放心好了,她们都是追求精神满足而非物质,大部分都是要找生命中的另一半,那她们的另一半会是你吗?
完整代码
# coding=utf-8
from selenium import webdriver
import time
from lxml import etree
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
"""
PEP8 Python编程规范
https://www.douban.com/note/134971609/
"""
# 获取浏览器驱动
driver = webdriver.Firefox()
driver.maximize_window()
webUrl = 'http://www.lovewzly.com/jiaoyou.html'
driver.get(webUrl)
# 等15秒,我来手动做一下筛选条件。,女性,21-30左右,学历本科,\
# 本来想通过js代码,来自动执行,但无奈对js真的不熟,也没有太多时间去整了,凑合看看.
time.sleep(15)
"""
下拉滚动条,从1开始到3结束 分2次加载完每页数据
"""
while True:
for i in range(1, 20):
height = 1000 * i # 每次滑动20000像素
strword = "window.scrollBy(0," + str(height) + ")"
driver.execute_script(strword)
time.sleep(3)
s = etree.HTML(driver.page_source)
selectors = s.xpath('//*[@id="hibox"]/table/tbody/tr/td/div')
with open('内心读白.txt', 'a') as f:
for selector in selectors:
img = selector.xpath('./div[1]/img/@src')
nick = selector.xpath('./div[2]/p[1]/span/text()')
age = selector.xpath('./div[2]/p[2]/span[1]/text()')
height = selector.xpath('./div[2]/p[2]/span[2]/text()')
address = selector.xpath('./div[2]/p[2]/span[3]/text()')
heart = selector.xpath('./div[2]/p[3]/text()')
img = img[0] if len(img) > 0 else ''
nick = nick[0] if len(nick) > 0 else ''
age = age[0] if len(age) > 0 else ''
height = height[0] if len(height) > 0 else ''
address = address[0] if len(address) > 0 else ''
heart = heart[0] if len(heart) > 0 else ''
print nick, age, height, address, heart, img
f.write(heart)
生成词云的代码之前的文章里面有,这里就不展示了,自行前往查阅!

我之前写了一个抓取妹子资料的文章,主要是使用selenium来模拟网页操作,然后使用动态加载,再用xpath来提取网页的资料,但这种方式效率不高。用Python来找合适的妹子(一)
所以今天我再补一个高效获取数据的办法.由于并没有什么模拟的操作,一切都可以人工来控制,所以也不需要打开网页就能获取数据!
但我们需要分析这个网页,打开网页 http://www.lovewzly.com/jiaoyou.html 后,按F12,进入Network项中
url在筛选条件后,只有page在发生变化,而且是一页页的累加,而且我们把这个url在浏览器中打开,会得到一批json字符串,所以我可以直接操作这里面的json数据,然后进行存储即可!
代码结构图:
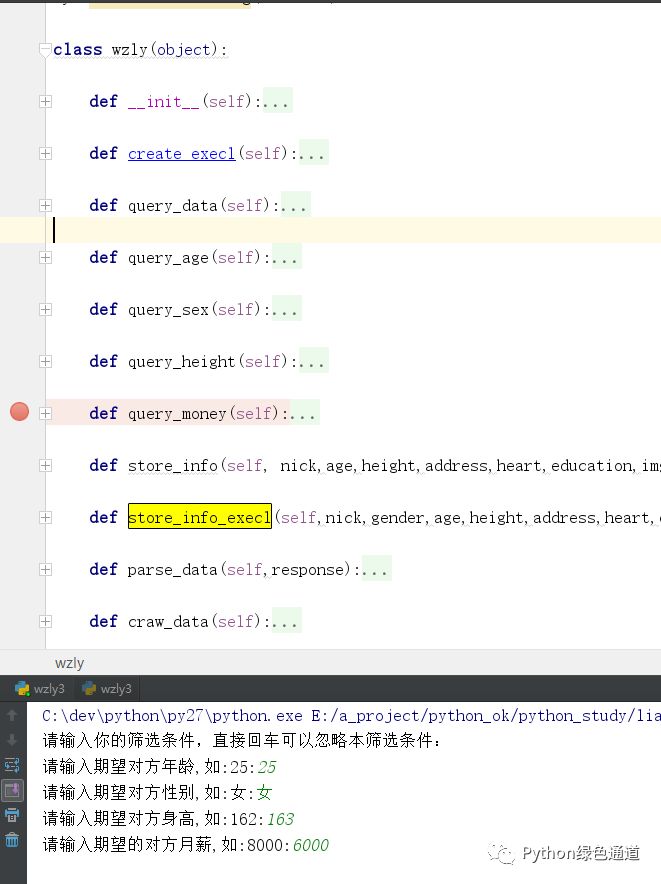
操作流程:
headers 一定要构建反盗链以及模拟浏览器操作,先这样写,可以避免后续问题!
条件拼装
然后记得数据转json格式
然后对json数据进行提取,
把提取到的数据放到文件或者存储起来
主要学习到的技术:
学习requests+urllib
操作execl
文件操作
字符串
异常处理
另外其它基础
请求数据
def craw_data(self):
'''数据抓取'''
headers = {
'Referer': 'http://www.lovewzly.com/jiaoyou.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4620.400 QQBrowser/9.7.13014.400'
}
page = 1
while True:
query_data = {
'page':page,
'gender':self.gender,
'starage':self.stargage,
'endage':self.endgage,
'stratheight':self.startheight,
'endheight':self.endheight,
'marry':self.marry,
'salary':self.salary,
}
url = 'http://www.lovewzly.com/api/user/pc/list/search?'+urllib.urlencode(query_data)
print url
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req).read()
# print response
self.parse_data(response)
page += 1
字段提取
def parse_data(self,response):
'''数据解析'''
persons = json.loads(response).get('data').get('list')
if persons is None:
print '数据已经请求完毕'
return
for person in persons:
nick = person.get('username')
gender = person.get('gender')
age = 2018 - int(person.get('birthdayyear'))
address = person.get('city')
heart = person.get('monolog')
height = person.get('height')
img_url = person.get('avatar')
education = person.get('education')
print nick,age,height,address,heart,education
self.store_info(nick,age,height,address,heart,education,img_url)
self.store_info_execl(nick,age,height,address,heart,education,img_url)
文件存放
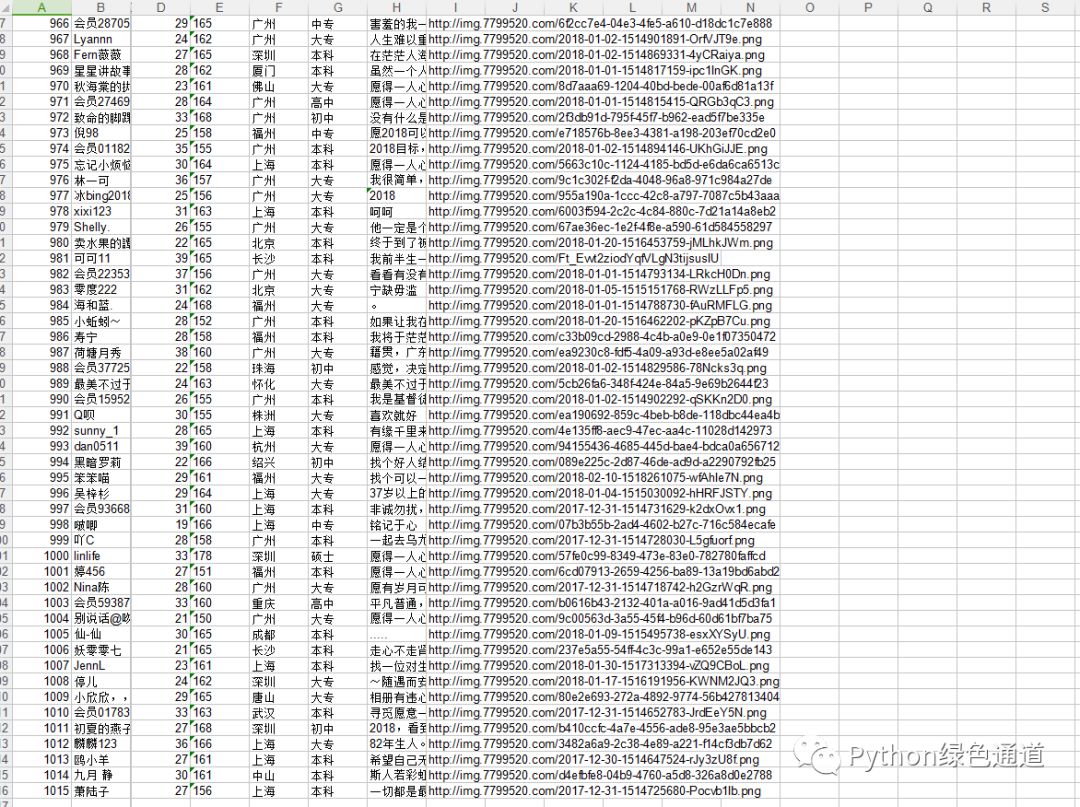
def store_info(self, nick,age,height,address,heart,education,img_url):
'''
存照片,与他们的内心独白
'''
if age < 22:
tag = '22岁以下'
elif 22 <= age < 28:
tag = '22-28岁'
elif 28 <= age < 32:
tag = '28-32岁'
elif 32 <= age:
tag = '32岁以上'
filename = u'{}岁_身高{}_学历{}_{}_{}.jpg'.format(age,height,education, address, nick)
try:
# 补全文件目录
image_path = u'E:/store/pic/{}'.format(tag)
# 判断文件夹是否存在。
if not os.path.exists(image_path):
os.makedirs(image_path)
print image_path + ' 创建成功'
# 注意这里是写入图片,要用二进制格式写入。
with open(image_path + '/' + filename, 'wb') as f:
f.write(urllib.urlopen(img_url).read())
txt_path = u'E:/store/txt'
txt_name = u'内心独白.txt'
# 判断文件夹是否存在。
if not os.path.exists(txt_path):
os.makedirs(txt_path)
print txt_path + ' 创建成功'
# 写入txt文本
with open(txt_path + '/' + txt_name, 'a') as f:
f.write(heart)
except Exception as e:
e.message
execl操作
def store_info_execl(self,nick,age,height,address,heart,education,img_url):
person = []
person.append(self.count) #正好是数据条
person.append(nick)
person.append(u'女' if self.gender == 2 else u'男')
person.append(age)
person.append(height)
person.append(address)
person.append(education)
person.append(heart)
person.append(img_url)
for j in range(len(person)):
self.sheetInfo.write(self.count, j, person[j])
self.f.save(u'我主良缘.xlsx')
self.count += 1
print '插入了{}条数据'.format(self.count)
源码地址:https://github.com/pythonchannel/python27/blob/master/test/meizhi.py
更多内容请关注我们 ↓
看完本文有收获?请转发分享给更多人