
新智元报道 来源:GoogleAI编辑:肖琴、大明【新智元导读】让机器人研究走向大众。加州大学伯克利分校和谷歌大脑的研究人员联合打造低成本机器人学习平台ROBEL,支持机器人实验扩展和强化学习,兼具稳健性、灵活性和可重复性。该平台现已发布至开源社区。快来新智元 AI 朋友圈参与讨论吧~
用于解决机器人控制问题的基于学习的方法最近有了显著的发展,这是由模拟基准(如dm_control或OpenAI-Gym)的广泛可用和灵活的、可扩展的强化学习技术(如DDPG, QT-Opt, 或 Soft Actor-Critic)的改进推动的。
虽然通过模拟学习很有效,但由于物理现象建模不准确或系统延迟等因素,这些模拟环境在部署到真实机器人时经常遇到困难。这激发了在真实世界中,在真实的物理硬件上直接开发机器人控制解决方案的需求。
当前,在物理硬件上的大多数机器人研究都是在高成本、工业级质量的机器人(PR2、Kuka-arms、ShadowHand、Baxter等)上进行的,目的是在受控环境中进行精确的、受监控的操作。此外,这些机器人是围绕传统的控制方法设计的,这些控制方法注重精度、可重复性和易于表征。
这与基于学习的方法形成了鲜明对比,基于学习的方法对于不完善的传感和和驱动具有鲁棒性,并且要求(a)高度的适应性以允许在现实世界中的反复试验学习,(b)低成本且实现维护,以通过复制实现可扩展性,以及(c)可靠的重置机制以减轻严格的人工监控要求。
来自加州大学伯克利分校(UC Berkeley)和谷歌大脑的研究人员解决了这个问题,他们提出了一个开源的低成本机器人学习平台“ROBEL”(Robotics Benchmarks for Learning with Low-Cost Robots),旨在鼓励快速实验和硬件强化学习。ROBEL还提供了主要用于促进现实世界物理硬件研究和开发的基准任务。ROBEL是一个快速的实验平台,支持广泛的实验需求和开发新的强化学习和控制方法。ROBEL由D’Claw和D'Kitty组成,D'Claw是一个有三只手臂的机械臂型机器人,可以帮助学习灵巧的操作任务.
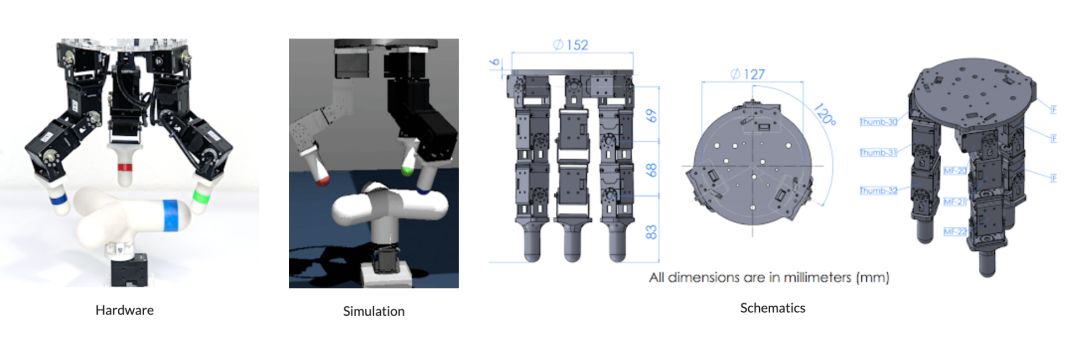 D'ClawD'Kitty是一个有四条腿的机器人,可以帮助学习灵活的腿部运动任务。
D'ClawD'Kitty是一个有四条腿的机器人,可以帮助学习灵活的腿部运动任务。
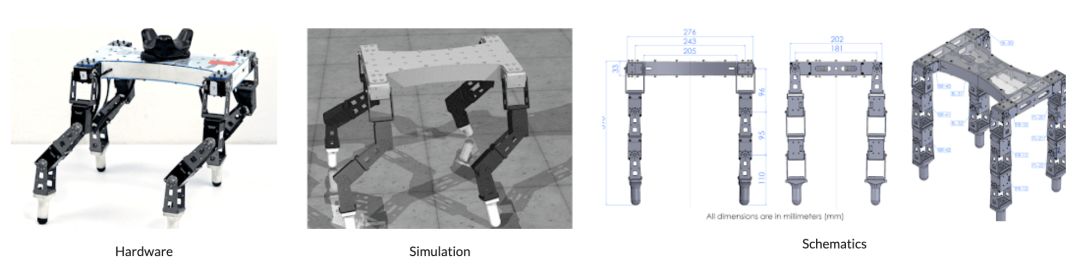 D'Kitty
D'Kitty
这个机器人平台是低成本的,模块化的,易于维护,足够强大,能够支持从零开始的硬件强化学习。左:十二自由度D'Kitty;中:9 自由度D'Claw;右:功能齐全的 D'Claw 装置D’Lantern。
为了使机器人成本便宜和易于构建,研究人员基于现成的组件和常见的原型工具(3D打印或激光切割)设计了ROBEL。该设计很容易组装,只需要几个小时即可构建。
ROBEL基准
谷歌设计了一套对 D’Claw and D’Kitty两个平台都适用的任务,可用于对现实世界的机器人学习进行基准测试。
ROBEL的任务定义包括密集和稀疏任务目标,并在任务定义中引入硬件安全指标,例如,指示关节是否超过“安全”操作界限或作用力阈值。ROBEL还为所有任务提供模拟器,以促进算法开发和快速原型设计。D’Claw 任务主要围绕三种常见的操作行为展开:摆形(Pose)、旋转(Turn)和拧(Screw)。

左: Pose-摆出符合环境的形态。中:Turn-将物体旋转到指定的角度。右:Screw-连续旋转对象,如拧螺丝。D’Kitty的任务主要围绕三种常见的移动行为——站立、定向和行走。
 左:站立-直立。中:调整方向-使方向与目标保持一致。右:走-移动到目标点。
左:站立-直立。中:调整方向-使方向与目标保持一致。右:走-移动到目标点。
针对这些基准任务,研究人员评估了几种深度强化学习方法(on-policy, off policy, demo-accelerated, supervised),评估结果和最终策略被作为baseline包含在软件包中以供比较。具体的任务细节和基线性能请查看论文。
可重复性和稳健性
ROBEL平台具有强大的功能,可以支持直接的硬件训练,迄今已积累了超过14000个小时的实际经验。一年来,这些平台已经非常成熟。由于设计的模块化,对系统的维护变得非常简单,几乎不需要领域内的专业知识。 为了确保平台和基准方法的可重复性,两个不同的研究实验室分别对ROBEL进行了研究。本研究仅使用软件分发和文档。不允许亲自访问。利用ROBEL的设计文档和组装说明,二者都可以复制两个硬件平台。基准任务在两个实验室分别构建的机器人上进行训练。下图所示在两个不同地点打造的两个D'Claw机器人,它们不仅训练进度相似,而且最终收敛到了相同的性能,说明ROBEL基准具备良好的可重复性。 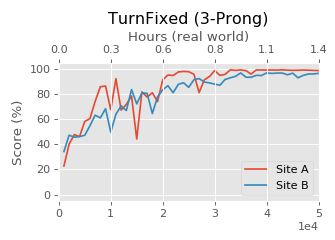
在不同实验室开发的两个真实D'Claw机器人执行任务的训练性能
实验结果与性能展示
到目前为止,ROBEL在各种强化学习研究中都非常有用。下面我们重点介绍一些关键结果, D’Claw平台是完全自主的,可以在很长一段时间内维持实验的可靠性,而且可以使用刚性和柔性对象的各种强化学习范例和任务改进实验。 


上图:高灵活性目标:使用DAPG进行的硬件训练有效学习了如何对灵活目标进行旋转。实验中可以观察到机器人对刚性更高的阀门中心部分进行操纵。D'Claw对硬件训练的稳健性很高,这有助于在难于模拟的任务上获得成功。中图:抗干扰:通过自然策略梯度在MuJoCo模拟中训练Sim2Real策略,其中对象扰动(以及其他)在硬件上进行了测试。我们观察到手指协同工作以抵抗外部干扰。下图:去掉一根手指:通过自然策略梯度在MuJoCo模拟中训练的Sim2Real策略,并在硬件上测试了外部和其他干扰)。机器人用空闲的手指填补了缺失手指的位置。 重要的是,D'Claw平台是高度模块化的,而且具备高度可重复性,便于进行扩展实验。通过扩展设置,我们发现多个D'Claws可以通过共享经验更快地对任务进行集体学习。 通过共享SAC的分布式版本的硬件训练流程,可以面向多个目标任务实现任意角度的结合。在多任务定制中,完成五个任务只需要单个任务经验的2倍即可。在视频中,五只D'Claws机器人将不同的物体旋转180度(这是出于视觉呈现的考虑,实际策略可以实现任意角度的旋转) 我们还成功地在D’Kitty平台上部署了强大的移动策略。下图中为D'Kitty在“盲眼”条件下在室内和室外地形上稳定行走,在“看不见”这一干扰条件下展现了步态的稳健性。
通过共享SAC的分布式版本的硬件训练流程,可以面向多个目标任务实现任意角度的结合。在多任务定制中,完成五个任务只需要单个任务经验的2倍即可。在视频中,五只D'Claws机器人将不同的物体旋转180度(这是出于视觉呈现的考虑,实际策略可以实现任意角度的旋转) 我们还成功地在D’Kitty平台上部署了强大的移动策略。下图中为D'Kitty在“盲眼”条件下在室内和室外地形上稳定行走,在“看不见”这一干扰条件下展现了步态的稳健性。

上图:在杂乱的室内环境行走:通过MuJoCo模拟通过自然策略梯度训练的Sim2Real策略,机器人可以在随机扰动的条件下实现行走,并跨过障碍物。中图:室外环境:碎石和树枝-通过自然策略梯度在MuJoCo模拟中训练的Sim2Real策略具有随机的高度场,可以学习在分布着碎石和树枝的户外环境中行走。下图:室外–斜坡和草丛:通过自然策略梯度在MuJoCo模拟中训练的Sim2Real策略具有随机高度场,机器人可以学习在缓坡上行走。 当D’Kitty收到有关其躯干和场景中目标的信息时,就可以学会与表现出复杂行为的目标进行交互。  左:躲避移动的障碍物:通过Hierarchical Sim2Real训练的策略可以学习躲避移动障碍物,到达目标位置。中:向移动目标推动另一目标。通过Hierarchical Sim2Real训练的策略学习将目标推向移动目标(由手中的控制器标记)。右图:双机器人协同-通过Hi-Herarchical Sim2Real训练的策略可以学习协调两个D'Kitty机器人,将沉重的障碍物推向目标位置(地板上标出的两个+号) 总之,ROBEL平台成本低、性能强大、可靠性高,可以满足新兴的基于学习范式的需求,这些范式需要高度的可扩展性和弹性。我们已经将ROBEL发布到开源社区中,相信可以推动相关研究和实验的多样性的提升。 要使用ROBEL平台和ROBEL基准测试,请访问roboticsbenchmarks.org
左:躲避移动的障碍物:通过Hierarchical Sim2Real训练的策略可以学习躲避移动障碍物,到达目标位置。中:向移动目标推动另一目标。通过Hierarchical Sim2Real训练的策略学习将目标推向移动目标(由手中的控制器标记)。右图:双机器人协同-通过Hi-Herarchical Sim2Real训练的策略可以学习协调两个D'Kitty机器人,将沉重的障碍物推向目标位置(地板上标出的两个+号) 总之,ROBEL平台成本低、性能强大、可靠性高,可以满足新兴的基于学习范式的需求,这些范式需要高度的可扩展性和弹性。我们已经将ROBEL发布到开源社区中,相信可以推动相关研究和实验的多样性的提升。 要使用ROBEL平台和ROBEL基准测试,请访问roboticsbenchmarks.org
参考链接:https://ai.googleblog.com/2019/10/robel-robotics-benchmarks-for-learning.html

