
实践教程 | 基于opencv实现模块化图像处理管道

极市导读
在这篇文章中,我们将学习如何为图像处理实现一个简单的模块化管道,本文使用 OpenCV 进行图像处理和操作,并使用 Python 生成器进行管道步骤。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在这篇文章中,我们将学习如何为图像处理实现一个简单的模块化管道,本文使用 OpenCV 进行图像处理和操作,并使用 Python 生成器进行管道步骤。
图像处理管道是一组按预定义顺序执行的任务,用于将图像转换为所需的结果或提取一些有趣的特征。
任务示例可以是:
图像转换,如平移、旋转、调整大小、翻转和裁剪,
图像的增强,
提取感兴趣区域(ROI),
计算特征描述符,
图像或对象分类,
物体检测,
用于机器学习的图像注释,
最终结果可能是一个新图像,或者只是一个包含一些图像信息的JSON文件。
假设我们在一个目录中有大量图像,并且想要检测其中的人脸并将每个人脸写入单独的文件。此外,我们希望有一些 JSON 摘要文件,它告诉我们在何处找到人脸以及在哪个文件中找到人脸。我们的人脸检测流程如下所示:
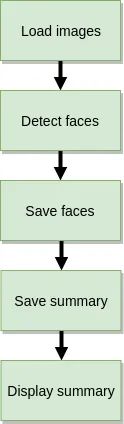
这是一个非常简单的例子,可以用以下代码总结:
import cv2
import os
import json
import numpy as np
def parse_args():
import argparse
# Parse command line arguments
ap = argparse.ArgumentParser(description="Image processing pipeline")
ap.add_argument("-i", "--input", required=True,
help="path to input image files")
ap.add_argument("-o", "--output", default="output",
help="path to output directory")
ap.add_argument("-os", "--out-summary", default=None,
help="output JSON summary file name")
ap.add_argument("-c", "--classifier", default="models/haarcascade/haarcascade_frontalface_default.xml",
help="path to where the face cascade resides")
return vars(ap.parse_args())
def list_images(path, valid_exts=None):
image_files = []
# Loop over the input directory structure
for (root_dir, dir_names, filenames) in os.walk(path):
for filename in sorted(filenames):
# Determine the file extension of the current file
ext = filename[filename.rfind("."):].lower()
if valid_exts and ext.endswith(valid_exts):
# Construct the path to the file and yield it
file = os.path.join(root_dir, filename)
image_files.append(file)
return image_files
def main(args):
os.makedirs(args["output"], exist_ok=True)
# load the face detector
detector = cv2.CascadeClassifier(args["classifier"])
# list images from input directory
input_image_files = list_images(args["input"], (".jpg", ".png"))
# Storage for JSON summary
summary = {}
# Loop over the image paths
for image_file in input_image_files:
# Load the image and convert it to grayscale
image = cv2.imread(image_file)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Detect faces
face_rects = detector.detectMultiScale(gray, scaleFactor=1.05, minNeighbors=5,
minSize=(30, 30), flags=cv2.CASCADE_SCALE_IMAGE)
summary[image_file] = {}
# Loop over all detected faces
for i, (x, y, w, h) in enumerate(face_rects):
face = image[y:y+w, x:x+h]
# Prepare output directory for faces
output = os.path.join(*(image_file.split(os.path.sep)[1:]))
output = os.path.join(args["output"], output)
os.makedirs(output, exist_ok=True)
# Save faces
face_file = os.path.join(output, f"{i:05d}.jpg")
cv2.imwrite(face_file, face)
# Store summary data
summary[image_file][face_file] = np.array([x, y, w, h], dtype=int).tolist()
# Display summary
print(f"[INFO] {image_file}: face detections {len(face_rects)}")
# Save summary data
if args["out_summary"]:
summary_file = os.path.join(args["output"], args["out_summary"])
print(f"[INFO] Saving summary to {summary_file}...")
with open(summary_file, 'w') as json_file:
json_file.write(json.dumps(summary))
if __name__ == '__main__':
args = parse_args()
main(args)
用于人脸检测和提取的简单图像处理脚本
代码中的注释也很有探索性,让我们来深入研究一下。首先,我们定义命令行参数解析器(第 6-20 行)以接受以下参数:
--input:这是包含我们图像的目录的路径(可以是子目录),这是唯一的强制性参数。
--output: 保存管道结果的输出目录。
--out-summary:如果我们想要一个 JSON 摘要,只需提供它的名称(例如 output.json)。
--classifier:用于人脸检测的预训练 Haar 级联的路径
接下来,我们定义list_images函数(第 22-34 行),它将帮助我们遍历输入目录结构以获取图像路径。对于人脸检测,我们使用称为Haar级联(第 40 行)的 Viola-Jones 算法,在深度学习和容易出现误报(在没有人脸的地方报告人脸)的时代,这是一种相当古老的算法。

主要处理循环如下:我们遍历图像文件(第 49行),逐个读取它们(第 51 行),检测人脸(第 55 行),将它们保存到准备好的目录(第 59-72 行)并保存带有人脸坐标的摘要报告(第 78-82 行)。
准备项目环境:
$ git clone git://github.com/jagin/image-processing-pipeline.git
$ cd image-processing-pipeline
$ git checkout 77c19422f0d7a90f1541ff81782948e9a12d2519
$ conda env create -f environment.yml
$ conda activate pipeline
为了确保你们的代码能够正常运行,请检查你们的切换分支命令是否正确:
77c19422f0d7a90f1541ff81782948e9a12d2519
让我们运行它:$ python process\_images.py --input assets/images -os output.json 我们得到了一个很好的总结:
[INFO] assets/images/friends/friends\_01.jpg: face detections 2
[INFO] assets/images/friends/friends\_02.jpg: face detections 3
[INFO] assets/images/friends/friends\_03.jpg: face detections 5
[INFO] assets/images/friends/friends\_04.jpg: face detections 14
[INFO] assets/images/landscapes/landscape\_01.jpg: face detections 0
[INFO] assets/images/landscapes/landscape\_02.jpg: face detections 0
[INFO] Saving summary to output/output.json...
每个图像的人脸图像(也有误报)存储在单独的目录中。
output
├── images
│ └── friends
│ ├── friends_01.jpg
│ │ ├── 00000.jpg
│ │ └── 00001.jpg
│ ├── friends_02.jpg
│ │ ├── 00000.jpg
│ │ ├── 00001.jpg
│ │ └── 00002.jpg
│ ├── friends_03.jpg
│ │ ├── 00000.jpg
│ │ ├── 00001.jpg
│ │ ├── 00002.jpg
│ │ ├── 00003.jpg
│ │ └── 00004.jpg
│ └── friends_04.jpg
│ ├── 00000.jpg
│ ├── 00001.jpg
│ ├── 00002.jpg
│ ├── 00003.jpg
│ ├── 00004.jpg
│ ├── 00005.jpg
│ ├── 00006.jpg
│ ├── 00007.jpg
│ ├── 00008.jpg
│ ├── 00009.jpg
│ ├── 00010.jpg
│ ├── 00011.jpg
│ ├── 00012.jpg
│ └── 00013.jpg
└── output.json如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
